 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Geometry-Aware Efficient Algorithm for Compositional Entropic Risk Minimization
Feb 02, 2026This paper studies optimization for a family of problems termed $\textbf{compositional entropic risk minimization}$, in which each data's loss is formulated as a Log-Expectation-Exponential (Log-E-Exp) function. The Log-E-Exp formulation serves as an abstraction of the Log-Sum-Exponential (LogSumExp) function when the explicit summation inside the logarithm is taken over a gigantic number of items and is therefore expensive to evaluate. While entropic risk objectives of this form arise in many machine learning problems, existing optimization algorithms suffer from several fundamental limitations including non-convergence, numerical instability, and slow convergence rates. To address these limitations, we propose a geometry-aware stochastic algorithm, termed $\textbf{SCENT}$, for the dual formulation of entropic risk minimization cast as a min--min optimization problem. The key to our design is a $\textbf{stochastic proximal mirror descent (SPMD)}$ update for the dual variable, equipped with a Bregman divergence induced by a negative exponential function that faithfully captures the geometry of the objective. Our main contributions are threefold: (i) we establish an $O(1/\sqrt{T})$ convergence rate of the proposed SCENT algorithm for convex problems; (ii) we theoretically characterize the advantages of SPMD over standard SGD update for optimizing the dual variable; and (iii) we demonstrate the empirical effectiveness of SCENT on extreme classification, partial AUC maximization, contrastive learning and distributionally robust optimization, where it consistently outperforms existing baselines.
NeuCLIP: Efficient Large-Scale CLIP Training with Neural Normalizer Optimization
Nov 11, 2025Accurately estimating the normalization term (also known as the partition function) in the contrastive loss is a central challenge for training Contrastive Language-Image Pre-training (CLIP) models. Conventional methods rely on large batches for approximation, demanding substantial computational resources. To mitigate this issue, prior works introduced per-sample normalizer estimators, which are updated at each epoch in a blockwise coordinate manner to keep track of updated encoders. However, this scheme incurs optimization error that scales with the ratio of dataset size to batch size, limiting effectiveness for large datasets or small batches. To overcome this limitation, we propose NeuCLIP, a novel and elegant optimization framework based on two key ideas: (i) $\textbf{reformulating}$ the contrastive loss for each sample $\textbf{via convex analysis}$ into a minimization problem with an auxiliary variable representing its log-normalizer; and (ii) $\textbf{transforming}$ the resulting minimization over $n$ auxiliary variables (where $n$ is the dataset size) via $\textbf{variational analysis}$ into the minimization over a compact neural network that predicts the log-normalizers. We design an alternating optimization algorithm that jointly trains the CLIP model and the auxiliary network. By employing a tailored architecture and acceleration techniques for the auxiliary network, NeuCLIP achieves more accurate normalizer estimation, leading to improved performance compared with previous methods. Extensive experiments on large-scale CLIP training, spanning datasets from millions to billions of samples, demonstrate that NeuCLIP outperforms previous methods.
Exploring space efficiency in a tree-based linear model for extreme multi-label classification
Oct 12, 2024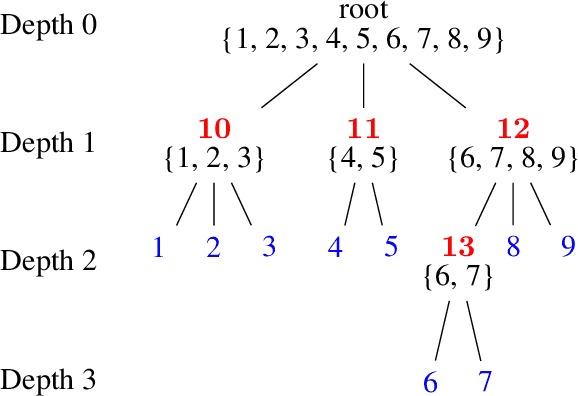
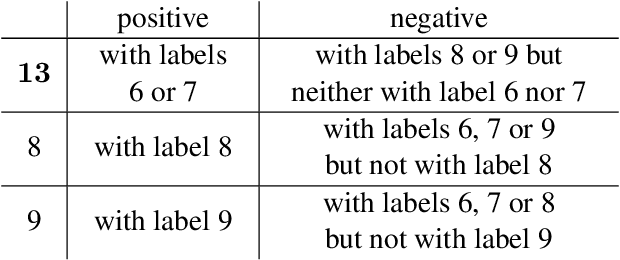
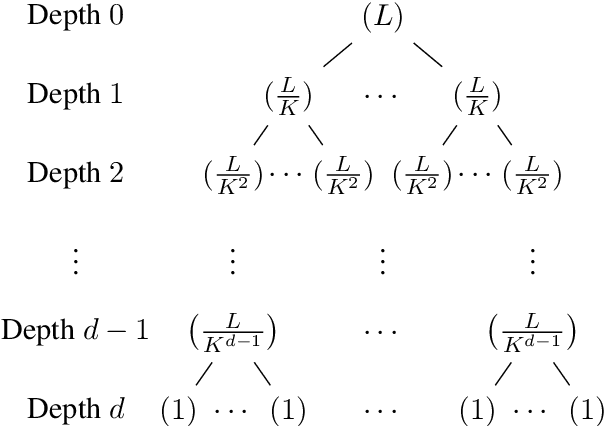
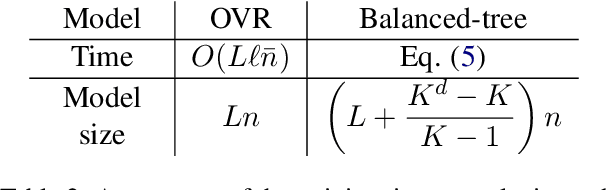
Extreme multi-label classification (XMC) aims to identify relevant subsets from numerous labels. Among the various approaches for XMC, tree-based linear models are effective due to their superior efficiency and simplicity. However, the space complexity of tree-based methods is not well-studied. Many past works assume that storing the model is not affordable and apply techniques such as pruning to save space, which may lead to performance loss. In this work, we conduct both theoretical and empirical analyses on the space to store a tree model under the assumption of sparse data, a condition frequently met in text data. We found that, some features may be unused when training binary classifiers in a tree method, resulting in zero values in the weight vectors. Hence, storing only non-zero elements can greatly save space. Our experimental results indicate that tree models can achieve up to a 95% reduction in storage space compared to the standard one-vs-rest method for multi-label text classification. Our research provides a simple procedure to estimate the size of a tree model before training any classifier in the tree nodes. Then, if the model size is already acceptable, this approach can help avoid modifying the model through weight pruning or other techniques.
A Step-by-step Introduction to the Implementation of Automatic Differentiation
Feb 25, 2024Automatic differentiation is a key component in deep learning. This topic is well studied and excellent surveys such as Baydin et al. (2018) have been available to clearly describe the basic concepts. Further, sophisticated implementations of automatic differentiation are now an important part of popular deep learning frameworks. However, it is difficult, if not impossible, to directly teach students the implementation of existing systems due to the complexity. On the other hand, if the teaching stops at the basic concept, students fail to sense the realization of an implementation. For example, we often mention the computational graph in teaching automatic differentiation, but students wonder how to implement and use it. In this document, we partially fill the gap by giving a step by step introduction of implementing a simple automatic differentiation system. We streamline the mathematical concepts and the implementation. Further, we give the motivation behind each implementation detail, so the whole setting becomes very natural.
Linear Classifier: An Often-Forgotten Baseline for Text Classification
Jun 12, 2023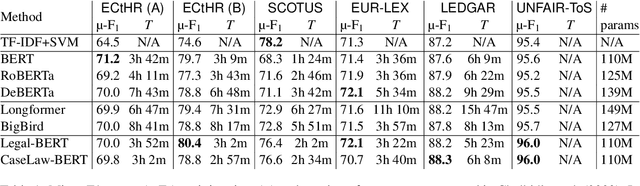
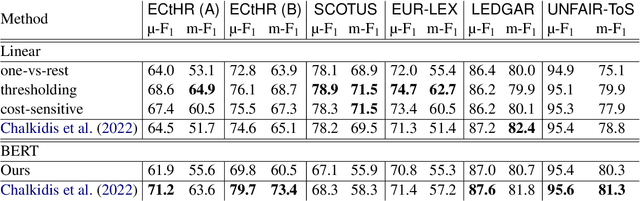
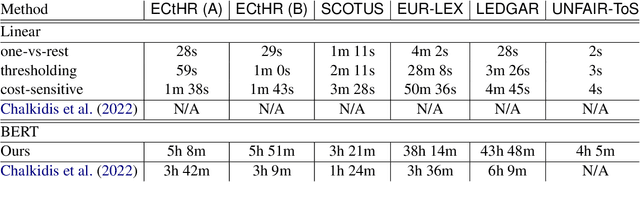

Large-scale pre-trained language models such as BERT are popular solutions for text classification. Due to the superior performance of these advanced methods, nowadays, people often directly train them for a few epochs and deploy the obtained model. In this opinion paper, we point out that this way may only sometimes get satisfactory results. We argue the importance of running a simple baseline like linear classifiers on bag-of-words features along with advanced methods. First, for many text data, linear methods show competitive performance, high efficiency, and robustness. Second, advanced models such as BERT may only achieve the best results if properly applied. Simple baselines help to confirm whether the results of advanced models are acceptable. Our experimental results fully support these points.
Mimic-IV-ICD: A new benchmark for eXtreme MultiLabel Classification
Apr 27, 2023



Clinical notes are assigned ICD codes - sets of codes for diagnoses and procedures. In the recent years, predictive machine learning models have been built for automatic ICD coding. However, there is a lack of widely accepted benchmarks for automated ICD coding models based on large-scale public EHR data. This paper proposes a public benchmark suite for ICD-10 coding using a large EHR dataset derived from MIMIC-IV, the most recent public EHR dataset. We implement and compare several popular methods for ICD coding prediction tasks to standardize data preprocessing and establish a comprehensive ICD coding benchmark dataset. This approach fosters reproducibility and model comparison, accelerating progress toward employing automated ICD coding in future studies. Furthermore, we create a new ICD-9 benchmark using MIMIC-IV data, providing more data points and a higher number of ICD codes than MIMIC-III. Our open-source code offers easy access to data processing steps, benchmark creation, and experiment replication for those with MIMIC-IV access, providing insights, guidance, and protocols to efficiently develop ICD coding models.
On the Use of Unrealistic Predictions in Hundreds of Papers Evaluating Graph Representations
Dec 13, 2021
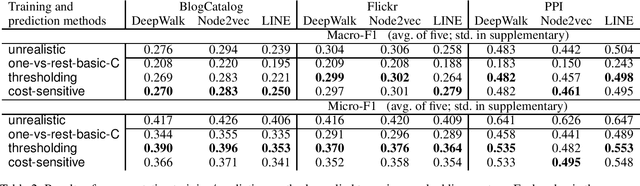

Prediction using the ground truth sounds like an oxymoron in machine learning. However, such an unrealistic setting was used in hundreds, if not thousands of papers in the area of finding graph representations. To evaluate the multi-label problem of node classification by using the obtained representations, many works assume in the prediction stage that the number of labels of each test instance is known. In practice such ground truth information is rarely available, but we point out that such an inappropriate setting is now ubiquitous in this research area. We detailedly investigate why the situation occurs. Our analysis indicates that with unrealistic information, the performance is likely over-estimated. To see why suitable predictions were not used, we identify difficulties in applying some multi-label techniques. For the use in future studies, we propose simple and effective settings without using practically unknown information. Finally, we take this chance to conduct a fair and serious comparison of major graph-representation learning methods on multi-label node classification.
Parameter Selection: Why We Should Pay More Attention to It
Jul 08, 2021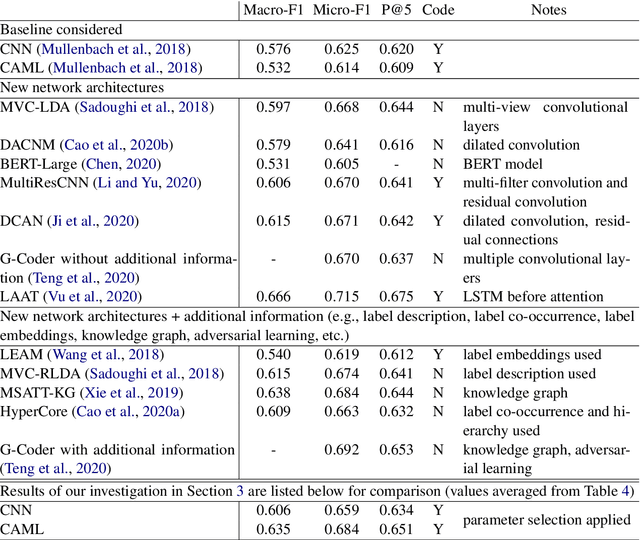
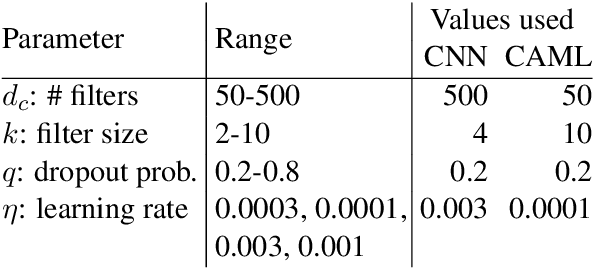
The importance of parameter selection in supervised learning is well known. However, due to the many parameter combinations, an incomplete or an insufficient procedure is often applied. This situation may cause misleading or confusing conclusions. In this opinion paper, through an intriguing example we point out that the seriousness goes beyond what is generally recognized. In the topic of multi-label classification for medical code prediction, one influential paper conducted a proper parameter selection on a set, but when moving to a subset of frequently occurring labels, the authors used the same parameters without a separate tuning. The set of frequent labels became a popular benchmark in subsequent studies, which kept pushing the state of the art. However, we discovered that most of the results in these studies cannot surpass the approach in the original paper if a parameter tuning had been conducted at the time. Thus it is unclear how much progress the subsequent developments have actually brought. The lesson clearly indicates that without enough attention on parameter selection, the research progress in our field can be uncertain or even illusive.
An Efficient Newton Method for Extreme Similarity Learning with Nonlinear Embeddings
Oct 26, 2020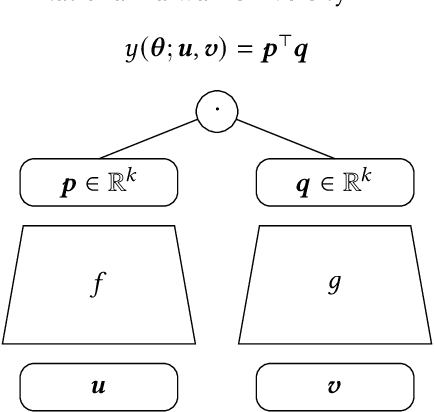

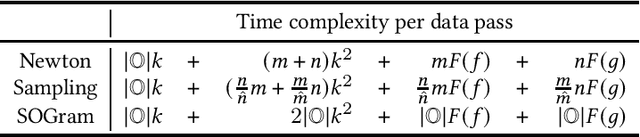
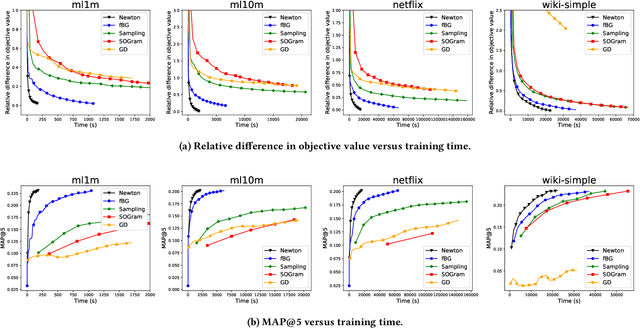
We study the problem of learning similarity by using nonlinear embedding models (e.g., neural networks) from all possible pairs. This problem is well-known for its difficulty of training with the extreme number of pairs. Existing optimization methods extended from stochastic gradient methods suffer from slow convergence and high complexity per pass of all possible pairs. Inspired by some recent works reporting that Newton methods are competitive for training certain types of neural networks, in this work, we novelly apply the Newton method for this problem. A prohibitive cost depending on the extreme number of pairs occurs if the Newton method is directly applied. We propose an efficient algorithm which successfully eliminates the cost. Our proposed algorithm can take advantage of second-order information and lower time complexity per pass of all possible pairs. Experiments conducted on large-scale data sets demonstrate that the proposed algorithm is more efficient than existing algorithms.
Newton Methods for Convolutional Neural Networks
Nov 14, 2018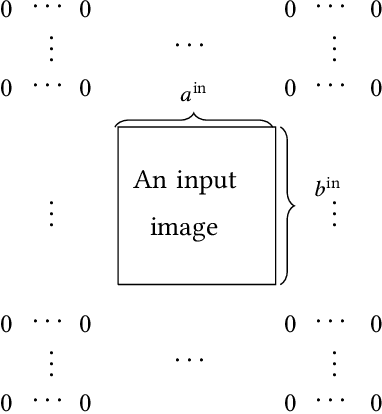



Deep learning involves a difficult non-convex optimization problem, which is often solved by stochastic gradient (SG) methods. While SG is usually effective, it may not be robust in some situations. Recently, Newton methods have been investigated as an alternative optimization technique, but nearly all existing studies consider only fully-connected feedforward neural networks. They do not investigate other types of networks such as Convolutional Neural Networks (CNN), which are more commonly used in deep-learning applications. One reason is that Newton methods for CNN involve complicated operations, and so far no works have conducted a thorough investigation. In this work, we give details of all building blocks including function, gradient, and Jacobian evaluation, and Gauss-Newton matrix-vector products. These basic components are very important because with them further developments of Newton methods for CNN become possible. We show that an efficient MATLAB implementation can be done in just several hundred lines of code and demonstrate that the Newton method gives competitive test accuracy.