 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring space efficiency in a tree-based linear model for extreme multi-label classification
Paper and Code
Oct 12, 2024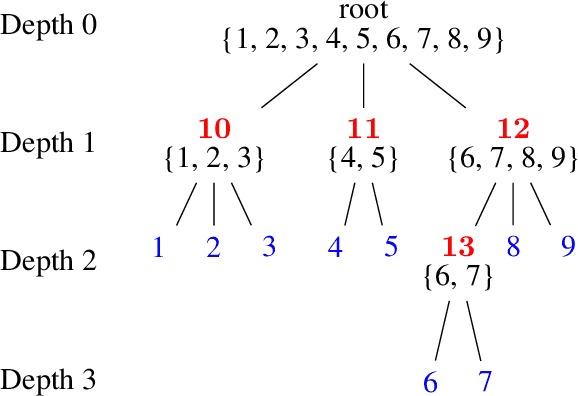
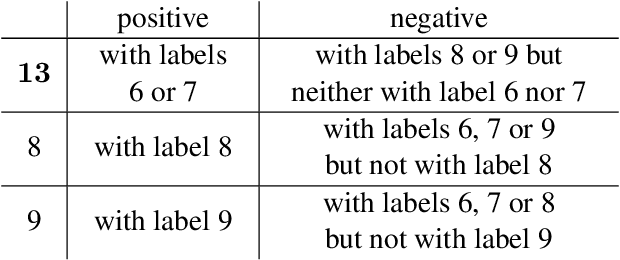
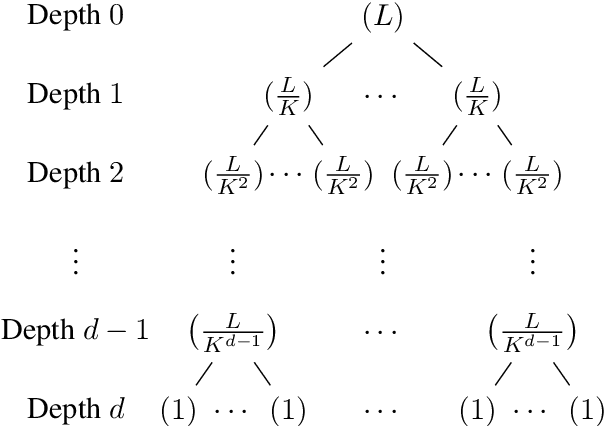
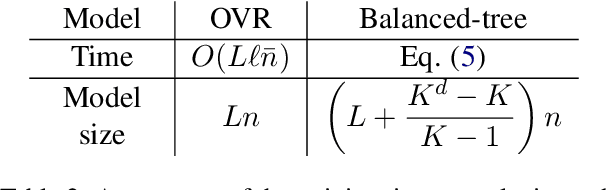
Extreme multi-label classification (XMC) aims to identify relevant subsets from numerous labels. Among the various approaches for XMC, tree-based linear models are effective due to their superior efficiency and simplicity. However, the space complexity of tree-based methods is not well-studied. Many past works assume that storing the model is not affordable and apply techniques such as pruning to save space, which may lead to performance loss. In this work, we conduct both theoretical and empirical analyses on the space to store a tree model under the assumption of sparse data, a condition frequently met in text data. We found that, some features may be unused when training binary classifiers in a tree method, resulting in zero values in the weight vectors. Hence, storing only non-zero elements can greatly save space. Our experimental results indicate that tree models can achieve up to a 95% reduction in storage space compared to the standard one-vs-rest method for multi-label text classification. Our research provides a simple procedure to estimate the size of a tree model before training any classifier in the tree nodes. Then, if the model size is already acceptable, this approach can help avoid modifying the model through weight pruning or other techniques.