 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use of Unrealistic Predictions in Hundreds of Papers Evaluating Graph Representations
Dec 13, 2021
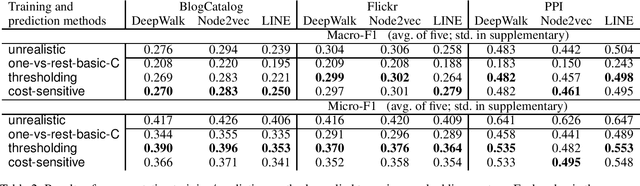

Prediction using the ground truth sounds like an oxymoron in machine learning. However, such an unrealistic setting was used in hundreds, if not thousands of papers in the area of finding graph representations. To evaluate the multi-label problem of node classification by using the obtained representations, many works assume in the prediction stage that the number of labels of each test instance is known. In practice such ground truth information is rarely available, but we point out that such an inappropriate setting is now ubiquitous in this research area. We detailedly investigate why the situation occurs. Our analysis indicates that with unrealistic information, the performance is likely over-estimated. To see why suitable predictions were not used, we identify difficulties in applying some multi-label techniques. For the use in future studies, we propose simple and effective settings without using practically unknown information. Finally, we take this chance to conduct a fair and serious comparison of major graph-representation learning methods on multi-label node classification.
Skewness Ranking Optimization for Personalized Recommendation
May 23, 2020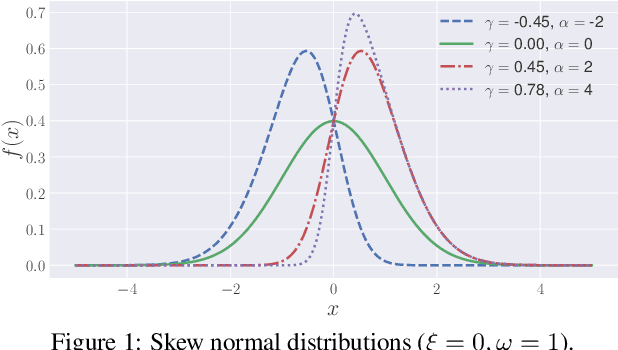
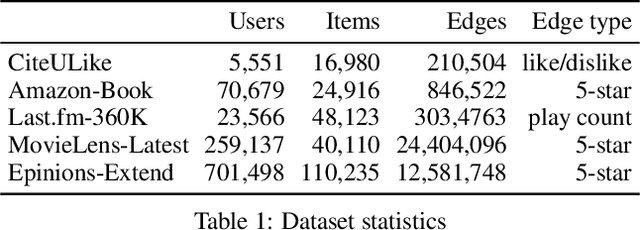

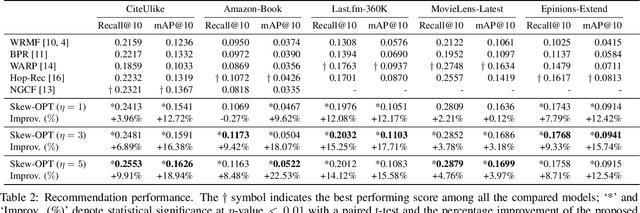
In this paper, we propose a novel optimization criterion that leverages features of the skew normal distribution to better model the problem of personalized recommendation. Specifically, the developed criterion borrows the concept and the flexibility of the skew normal distribution, based on which three hyperparameters are attached to the optimization criterion. Furthermore, from a theoretical point of view, we not only establish the relation between the maximization of the proposed criterion and the shape parameter in the skew normal distribution, but also provide the analogies and asymptotic analysis of the proposed criterion to maximization of the area under the ROC curve. Experimental results conducted on a range of large-scale real-world datasets show that our model significantly outperforms the state of the art and yields consistently best performance on all tested datasets.