 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFDA & CLIP at TREC iKAT 2025: Enhancing Personalized Conversational Search via Query Reformulation and Rank Fusion
Sep 19, 2025The 2025 TREC Interactive Knowledge Assistance Track (iKAT) featured both interactive and offline submission tasks. The former requires systems to operate under real-time constraints, making robustness and efficiency as important as accuracy, while the latter enables controlled evaluation of passage ranking and response generation with pre-defined datasets. To address this, we explored query rewriting and retrieval fusion as core strategies. We built our pipelines around Best-of-$N$ selection and Reciprocal Rank Fusion (RRF) strategies to handle different submission tasks. Results show that reranking and fusion improve robustness while revealing trade-offs between effectiveness and efficiency across both tasks.
Test-Time Scaling Strategies for Generative Retrieval in Multimodal Conversational Recommendations
Aug 25, 2025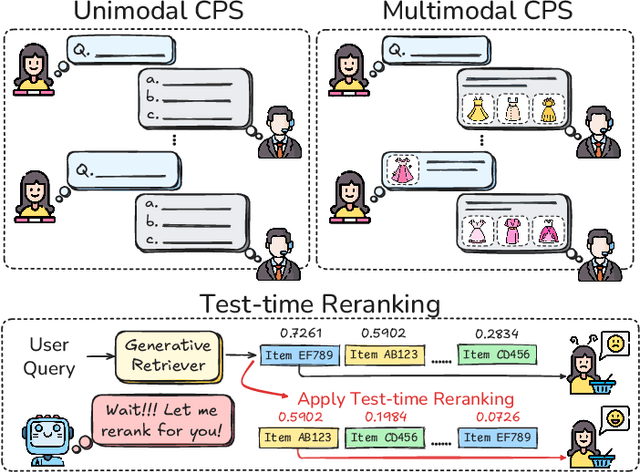
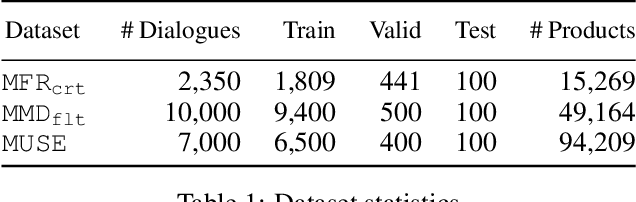
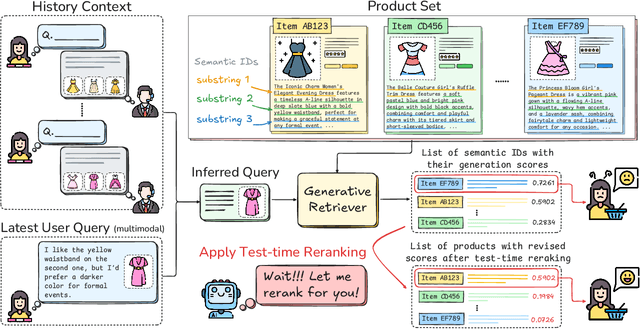
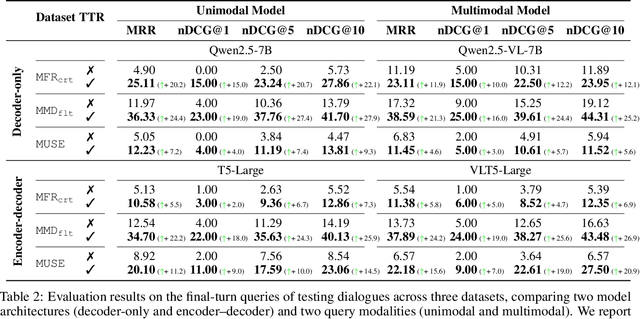
The rapid evolution of e-commerce has exposed the limitations of traditional product retrieval systems in managing complex, multi-turn user interactions. Recent advances in multimodal generative retrieval -- particularly those leveraging multimodal large language models (MLLMs) as retrievers -- have shown promise. However, most existing methods are tailored to single-turn scenarios and struggle to model the evolving intent and iterative nature of multi-turn dialogues when applied naively. Concurrently, test-time scaling has emerged as a powerful paradigm for improving large language model (LLM) performance through iterative inference-time refinement. Yet, its effectiveness typically relies on two conditions: (1) a well-defined problem space (e.g., mathematical reasoning), and (2) the model's ability to self-correct -- conditions that are rarely met in conversational product search. In this setting, user queries are often ambiguous and evolving, and MLLMs alone have difficulty grounding responses in a fixed product corpus. Motivated by these challenges, we propose a novel framework that introduces test-time scaling into conversational multimodal product retrieval. Our approach builds on a generative retriever, further augmented with a test-time reranking (TTR) mechanism that improves retrieval accuracy and better aligns results with evolving user intent throughout the dialogue. Experiments across multiple benchmarks show consistent improvements, with average gains of 14.5 points in MRR and 10.6 points in nDCG@1.
Improving Conversational Passage Re-ranking with View Ensemble
Apr 26, 2023
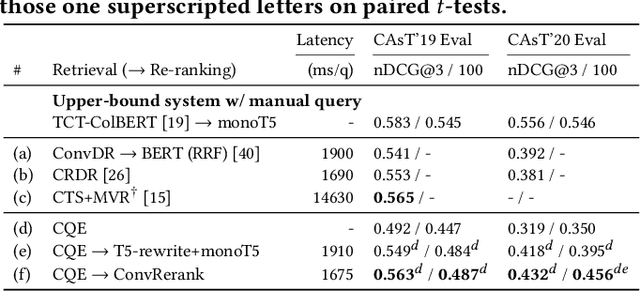
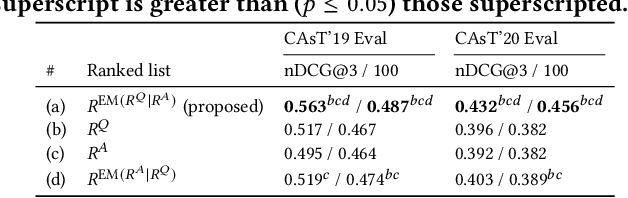
This paper presents ConvRerank, a conversational passage re-ranker that employs a newly developed pseudo-labeling approach. Our proposed view-ensemble method enhances the quality of pseudo-labeled data, thus improving the fine-tuning of ConvRerank. Our experimental evaluation on benchmark datasets shows that combining ConvRerank with a conversational dense retriever in a cascaded manner achieves a good balance between effectiveness and efficiency. Compared to baseline methods, our cascaded pipeline demonstrates lower latency and higher top-ranking effectiveness. Furthermore, the in-depth analysis confirms the potential of our approach to improving the effectiveness of conversational search.
On the Use of Unrealistic Predictions in Hundreds of Papers Evaluating Graph Representations
Dec 13, 2021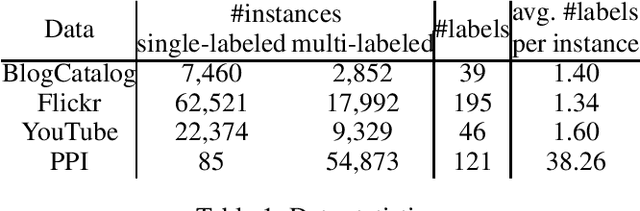
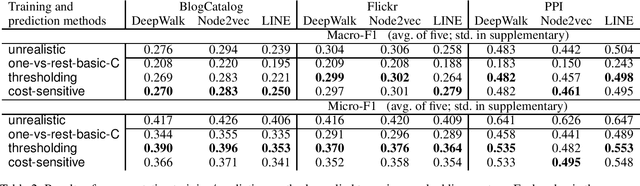

Prediction using the ground truth sounds like an oxymoron in machine learning. However, such an unrealistic setting was used in hundreds, if not thousands of papers in the area of finding graph representations. To evaluate the multi-label problem of node classification by using the obtained representations, many works assume in the prediction stage that the number of labels of each test instance is known. In practice such ground truth information is rarely available, but we point out that such an inappropriate setting is now ubiquitous in this research area. We detailedly investigate why the situation occurs. Our analysis indicates that with unrealistic information, the performance is likely over-estimated. To see why suitable predictions were not used, we identify difficulties in applying some multi-label techniques. For the use in future studies, we propose simple and effective settings without using practically unknown information. Finally, we take this chance to conduct a fair and serious comparison of major graph-representation learning methods on multi-label node classification.
Personalized TV Recommendation: Fusing User Behavior and Preferences
Aug 30, 2020
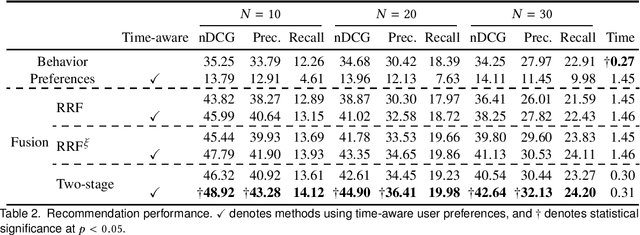
In this paper, we propose a two-stage ranking approach for recommending linear TV programs. The proposed approach first leverages user viewing patterns regarding time and TV channels to identify potential candidates for recommendation and then further leverages user preferences to rank these candidates given textual information about programs. To evaluate the method, we conduct empirical studies on a real-world TV dataset, the results of which demonstrate the superior performance of our model in terms of both recommendation accuracy and time efficiency.
Skewness Ranking Optimization for Personalized Recommendation
May 23, 2020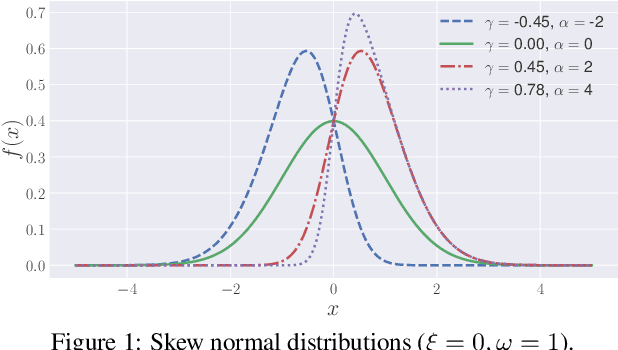

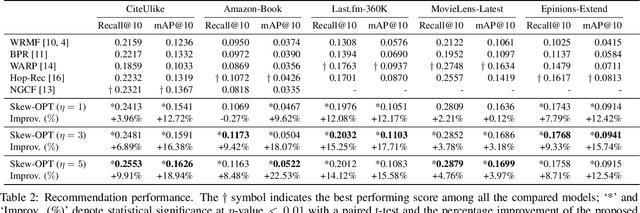
In this paper, we propose a novel optimization criterion that leverages features of the skew normal distribution to better model the problem of personalized recommendation. Specifically, the developed criterion borrows the concept and the flexibility of the skew normal distribution, based on which three hyperparameters are attached to the optimization criterion. Furthermore, from a theoretical point of view, we not only establish the relation between the maximization of the proposed criterion and the shape parameter in the skew normal distribution, but also provide the analogies and asymptotic analysis of the proposed criterion to maximization of the area under the ROC curve. Experimental results conducted on a range of large-scale real-world datasets show that our model significantly outperforms the state of the art and yields consistently best performance on all tested datasets.
Query Reformulation using Query History for Passage Retrieval in Conversational Search
May 05, 2020
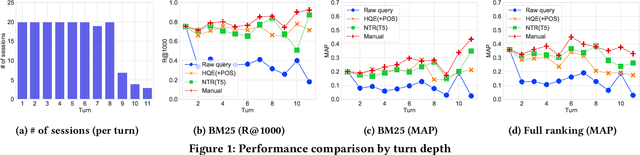
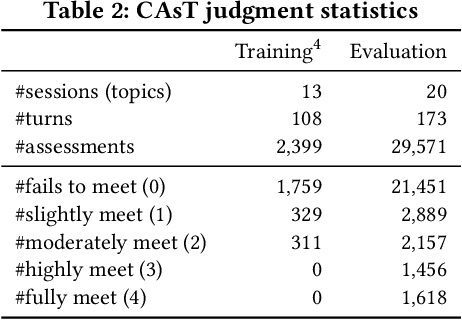
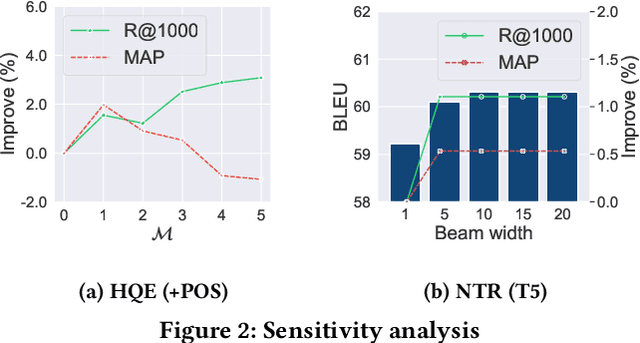
Passage retrieval in a conversational context is essential for many downstream applications; it is however extremely challenging due to limited data resources. To address this problem, we present an effective multi-stage pipeline for passage ranking in conversational search that integrates a widely-used IR system with a conversational query reformulation module. Along these lines, we propose two simple yet effective query reformulation approaches: historical query expansion (HQE) and neural transfer reformulation (NTR). Whereas HQE applies query expansion, a traditional IR query reformulation technique, NTR transfers human knowledge of conversational query understanding to a neural query reformulation model. The proposed HQE method was the top-performing submission of automatic systems in CAsT Track at TREC 2019. Building on this, our NTR approach improves an additional 18% over that best entry in terms of NDCG@3. We further analyze the distinct behaviors of the two approaches, and show that fusing their output reduces the performance gap (measured in NDCG@3) between the manually-rewritten and automatically-generated queries to 4 from 22 points when compared with the best CAsT submission.
Conversational Question Reformulation via Sequence-to-Sequence Architectures and Pretrained Language Models
Apr 04, 2020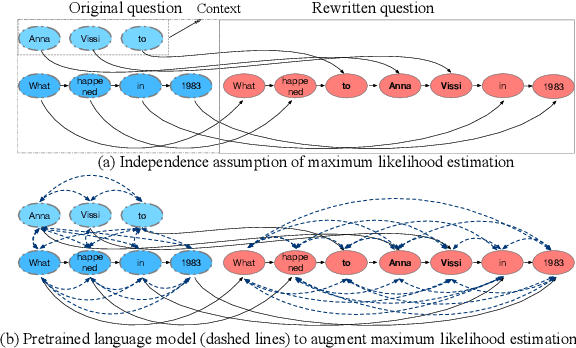
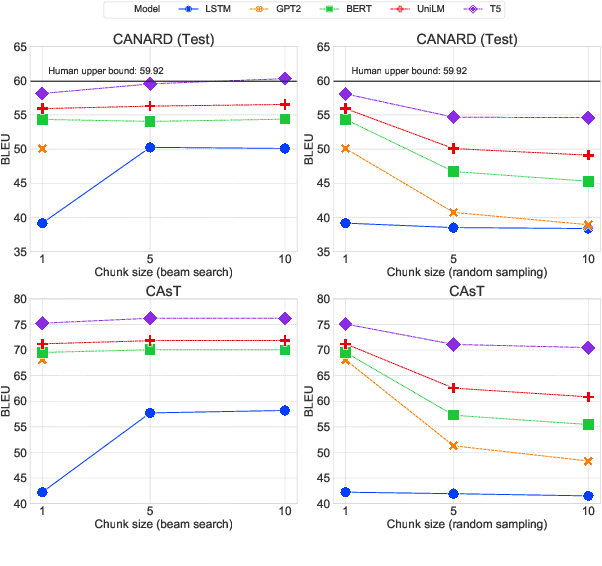
This paper presents an empirical study of conversational question reformulation (CQR) with sequence-to-sequence architectures and pretrained language models (PLMs). We leverage PLMs to address the strong token-to-token independence assumption made in the common objective, maximum likelihood estimation, for the CQR task. In CQR benchmarks of task-oriented dialogue systems, we evaluate fine-tuned PLMs on the recently-introduced CANARD dataset as an in-domain task and validate the models using data from the TREC 2019 CAsT Track as an out-domain task. Examining a variety of architectures with different numbers of parameters, we demonstrate that the recent text-to-text transfer transformer (T5) achieves the best results both on CANARD and CAsT with fewer parameters, compared to similar transformer architectures.
TTTTTackling WinoGrande Schemas
Mar 18, 2020
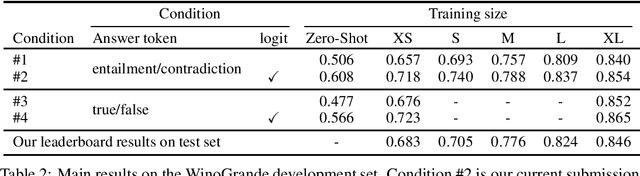
We applied the T5 sequence-to-sequence model to tackle the AI2 WinoGrande Challenge by decomposing each example into two input text strings, each containing a hypothesis, and using the probabilities assigned to the "entailment" token as a score of the hypothesis. Our first (and only) submission to the official leaderboard yielded 0.7673 AUC on March 13, 2020, which is the best known result at this time and beats the previous state of the art by over five points.
Superhighway: Bypass Data Sparsity in Cross-Domain CF
Aug 28, 2018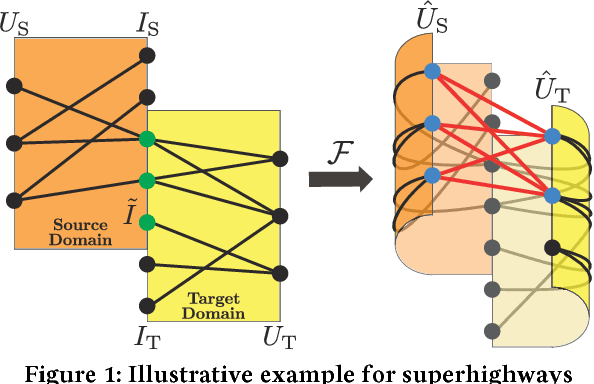
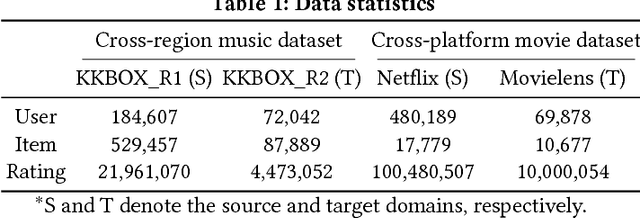
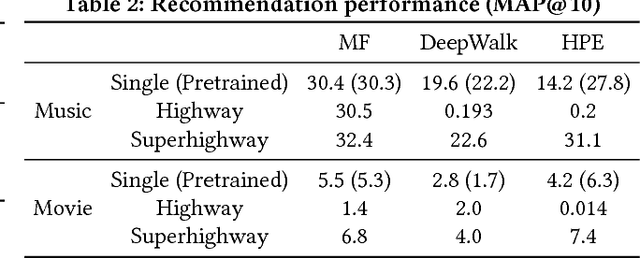
Cross-domain collaborative filtering (CF) aims to alleviate data sparsity in single-domain CF by leveraging knowledge transferred from related domains. Many traditional methods focus on enriching compared neighborhood relations in CF directly to address the sparsity problem. In this paper, we propose superhighway construction, an alternative explicit relation-enrichment procedure, to improve recommendations by enhancing cross-domain connectivity. Specifically, assuming partially overlapped items (users), superhighway bypasses multi-hop inter-domain paths between cross-domain users (items, respectively) with direct paths to enrich the cross-domain connectivity. The experiments conducted on a real-world cross-region music dataset and a cross-platform movie dataset show that the proposed superhighway construction significantly improves recommendation performance in both target and source domains.