 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnglish is Not All You Need: Systematically Exploring the Role of Multilinguality in LLM Post-Training
Apr 14, 2026Despite the widespread multilingual deployment of large language models, post-training pipelines remain predominantly English-centric, contributing to performance disparities across languages. We present a systematic, controlled study of the interplay between training language coverage, model scale, and task domain, based on 220 supervised fine-tuning runs on parallel translated multilingual data mixtures spanning mathematical reasoning and API calling tasks, with models up to 8B parameters. We find that increasing language coverage during post-training is largely beneficial across tasks and model scales, with low-resource languages benefiting the most and high-resource languages plateauing rather than degrading. Even minimal multilinguality helps: incorporating a single non-English language improves both English performance and cross-lingual generalization, making English-only post-training largely suboptimal. Moreover, at sufficient language diversity, zero-shot cross-lingual transfer can match or exceed the effects of direct language inclusion in a low-diversity setting, although gains remain limited for typologically distant, low-resource languages.
Should LLMs, $\textit{like}$, Generate How Users Talk? Building Dialect-Accurate Dialog[ue]s Beyond the American Default with MDial
Jan 30, 2026More than 80% of the 1.6 billion English speakers do not use Standard American English (SAE) and experience higher failure rates and stereotyped responses when interacting with LLMs as a result. Yet multi-dialectal performance remains underexplored. We introduce $\textbf{MDial}$, the first large-scale framework for generating multi-dialectal conversational data encompassing the three pillars of written dialect -- lexical (vocabulary), orthographic (spelling), and morphosyntactic (grammar) features -- for nine English dialects. Partnering with native linguists, we design an annotated and scalable rule-based LLM transformation to ensure precision. Our approach challenges the assumption that models should mirror users' morphosyntactic features, showing that up to 90% of the grammatical features of a dialect should not be reproduced by models. Independent evaluations confirm data quality, with annotators preferring MDial outputs over prior methods in 98% of pairwise comparisons for dialect naturalness. Using this pipeline, we construct the dialect-parallel $\textbf{MDialBench}$mark with 50k+ dialogs, resulting in 97k+ QA pairs, and evaluate 17 LLMs on dialect identification and response generation tasks. Even frontier models achieve under 70% accuracy, fail to reach 50% for Canadian English, and systematically misclassify non-SAE dialects as American or British. As dialect identification underpins natural language understanding, these errors risk cascading failures into downstream tasks.
LinguaMap: Which Layers of LLMs Speak Your Language and How to Tune Them?
Jan 27, 2026Despite multilingual pretraining, large language models often struggle with non-English tasks, particularly in language control, the ability to respond in the intended language. We identify and characterize two key failure modes: the multilingual transfer bottleneck (correct language, incorrect task response) and the language consistency bottleneck (correct task response, wrong language). To systematically surface these issues, we design a four-scenario evaluation protocol spanning MMLU, MGSM, and XQuAD benchmarks. To probe these issues with interpretability, we extend logit lens analysis to track language probabilities layer by layer and compute cross-lingual semantic similarity of hidden states. The results reveal a three-phase internal structure: early layers align inputs into a shared semantic space, middle layers perform task reasoning, and late layers drive language-specific generation. Guided by these insights, we introduce selective fine-tuning of only the final layers responsible for language control. On Qwen-3-32B and Bloom-7.1B, this method achieves over 98 percent language consistency across six languages while fine-tuning only 3-5 percent of parameters, without sacrificing task accuracy. Importantly, this result is nearly identical to that of full-scope fine-tuning (for example, above 98 percent language consistency for both methods across all prompt scenarios) but uses a fraction of the computational resources. To the best of our knowledge, this is the first approach to leverage layer-localization of language control for efficient multilingual adaptation.
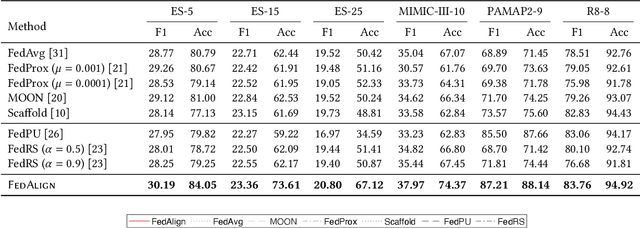
PolyLingua: Margin-based Inter-class Transformer for Robust Cross-domain Language Detection
Dec 10, 2025Language identification is a crucial first step in multilingual systems such as chatbots and virtual assistants, enabling linguistically and culturally accurate user experiences. Errors at this stage can cascade into downstream failures, setting a high bar for accuracy. Yet, existing language identification tools struggle with key cases -- such as music requests where the song title and user language differ. Open-source tools like LangDetect, FastText are fast but less accurate, while large language models, though effective, are often too costly for low-latency or low-resource settings. We introduce PolyLingua, a lightweight Transformer-based model for in-domain language detection and fine-grained language classification. It employs a two-level contrastive learning framework combining instance-level separation and class-level alignment with adaptive margins, yielding compact and well-separated embeddings even for closely related languages. Evaluated on two challenging datasets -- Amazon Massive (multilingual digital assistant utterances) and a Song dataset (music requests with frequent code-switching) -- PolyLingua achieves 99.25% F1 and 98.15% F1, respectively, surpassing Sonnet 3.5 while using 10x fewer parameters, making it ideal for compute- and latency-constrained environments.
Can Time-Series Foundation Models Perform Building Energy Management Tasks?
Jun 12, 2025Building energy management (BEM) tasks require processing and learning from a variety of time-series data. Existing solutions rely on bespoke task- and data-specific models to perform these tasks, limiting their broader applicability. Inspired by the transformative success of Large Language Models (LLMs), Time-Series Foundation Models (TSFMs), trained on diverse datasets, have the potential to change this. Were TSFMs to achieve a level of generalizability across tasks and contexts akin to LLMs, they could fundamentally address the scalability challenges pervasive in BEM. To understand where they stand today, we evaluate TSFMs across four dimensions: (1) generalizability in zero-shot univariate forecasting, (2) forecasting with covariates for thermal behavior modeling, (3) zero-shot representation learning for classification tasks, and (4) robustness to performance metrics and varying operational conditions. Our results reveal that TSFMs exhibit \emph{limited} generalizability, performing only marginally better than statistical models on unseen datasets and modalities for univariate forecasting. Similarly, inclusion of covariates in TSFMs does not yield performance improvements, and their performance remains inferior to conventional models that utilize covariates. While TSFMs generate effective zero-shot representations for downstream classification tasks, they may remain inferior to statistical models in forecasting when statistical models perform test-time fitting. Moreover, TSFMs forecasting performance is sensitive to evaluation metrics, and they struggle in more complex building environments compared to statistical models. These findings underscore the need for targeted advancements in TSFM design, particularly their handling of covariates and incorporating context and temporal dynamics into prediction mechanisms, to develop more adaptable and scalable solutions for BEM.
Physics-Informed Data Denoising for Real-Life Sensing Systems
Nov 12, 2023
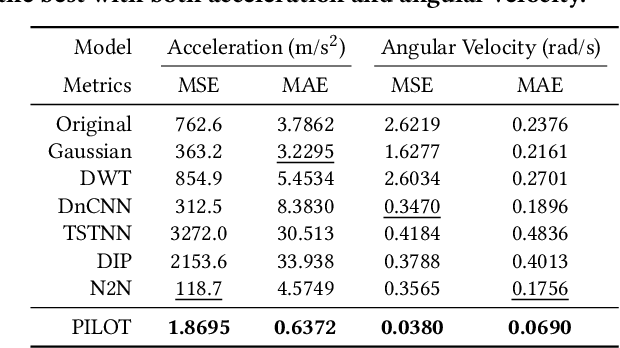


Sensors measuring real-life physical processes are ubiquitous in today's interconnected world. These sensors inherently bear noise that often adversely affects performance and reliability of the systems they support. Classic filtering-based approaches introduce strong assumptions on the time or frequency characteristics of sensory measurements, while learning-based denoising approaches typically rely on using ground truth clean data to train a denoising model, which is often challenging or prohibitive to obtain for many real-world applications. We observe that in many scenarios, the relationships between different sensor measurements (e.g., location and acceleration) are analytically described by laws of physics (e.g., second-order differential equation). By incorporating such physics constraints, we can guide the denoising process to improve even in the absence of ground truth data. In light of this, we design a physics-informed denoising model that leverages the inherent algebraic relationships between different measurements governed by the underlying physics. By obviating the need for ground truth clean data, our method offers a practical denoising solution for real-world applications. We conducted experiments in various domains, including inertial navigation, CO2 monitoring, and HVAC control, and achieved state-of-the-art performance compared with existing denoising methods. Our method can denoise data in real time (4ms for a sequence of 1s) for low-cost noisy sensors and produces results that closely align with those from high-precision, high-cost alternatives, leading to an efficient, cost-effective approach for more accurate sensor-based systems.
Towards Diverse and Coherent Augmentation for Time-Series Forecasting
Mar 24, 2023



Time-series data augmentation mitigates the issue of insufficient training data for deep learning models. Yet, existing augmentation methods are mainly designed for classification, where class labels can be preserved even if augmentation alters the temporal dynamics. We note that augmentation designed for forecasting requires diversity as well as coherence with the original temporal dynamics. As time-series data generated by real-life physical processes exhibit characteristics in both the time and frequency domains, we propose to combine Spectral and Time Augmentation (STAug) for generating more diverse and coherent samples. Specifically, in the frequency domain, we use the Empirical Mode Decomposition to decompose a time series and reassemble the subcomponents with random weights. This way, we generate diverse samples while being coherent with the original temporal relationships as they contain the same set of base components. In the time domain, we adapt a mix-up strategy that generates diverse as well as linearly in-between coherent samples. Experiments on five real-world time-series datasets demonstrate that STAug outperforms the base models without data augmentation as well as state-of-the-art augmentation methods.
Federated Learning with Client-Exclusive Classes
Jan 01, 2023


Existing federated classification algorithms typically assume the local annotations at every client cover the same set of classes. In this paper, we aim to lift such an assumption and focus on a more general yet practical non-IID setting where every client can work on non-identical and even disjoint sets of classes (i.e., client-exclusive classes), and the clients have a common goal which is to build a global classification model to identify the union of these classes. Such heterogeneity in client class sets poses a new challenge: how to ensure different clients are operating in the same latent space so as to avoid the drift after aggregation? We observe that the classes can be described in natural languages (i.e., class names) and these names are typically safe to share with all parties. Thus, we formulate the classification problem as a matching process between data representations and class representations and break the classification model into a data encoder and a label encoder. We leverage the natural-language class names as the common ground to anchor the class representations in the label encoder. In each iteration, the label encoder updates the class representations and regulates the data representations through matching. We further use the updated class representations at each round to annotate data samples for locally-unaware classes according to similarity and distill knowledge to local models. Extensive experiments on four real-world datasets show that the proposed method can outperform various classical and state-of-the-art federated learning methods designed for learning with non-IID data.
Modeling Label Semantics Improves Activity Recognition
Jan 01, 2023



Human activity recognition (HAR) aims to classify sensory time series into different activities, with wide applications in activity tracking, healthcare, human computer interaction, etc. Existing HAR works improve recognition performance by designing more complicated feature extraction methods, but they neglect the label semantics by simply treating labels as integer IDs. We find that many activities in the current HAR datasets have shared label names, e.g., "open door" and "open fridge", "walk upstairs" and "walk downstairs". Through some exploratory analysis, we find that such shared structure in activity names also maps to similarity in the input features. To this end, we design a sequence-to-sequence framework to decode the label name semantics rather than classifying labels as integer IDs. Our proposed method decomposes learning activities into learning shared tokens ("open", "walk"), which is easier than learning the joint distribution ("open fridge", "walk upstairs") and helps transfer learning to activities with insufficient data samples. For datasets originally without shared tokens in label names, we also offer an automated method, using OpenAI's ChatGPT, to generate shared actions and objects. Extensive experiments on seven HAR benchmark datasets demonstrate the state-of-the-art performance of our method. We also show better performance in the long-tail activity distribution settings and few-shot settings.
B2RL: An open-source Dataset for Building Batch Reinforcement Learning
Sep 30, 2022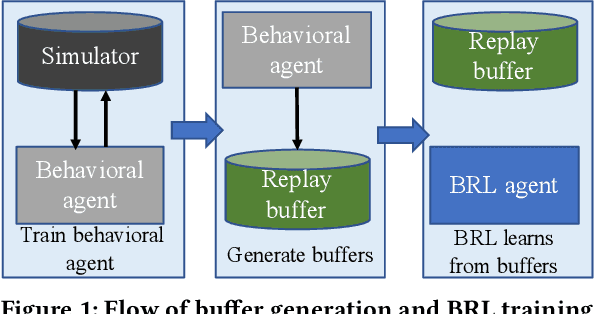
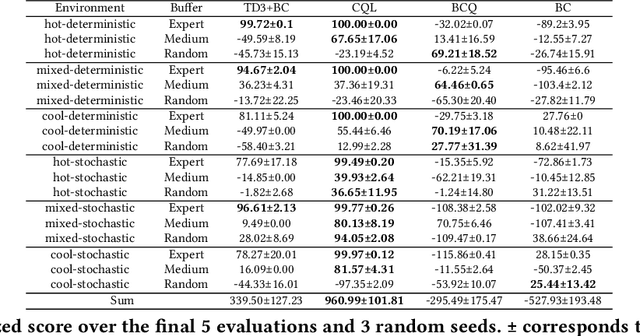
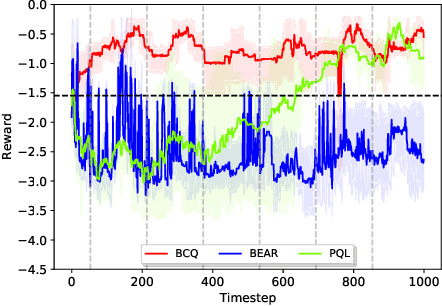
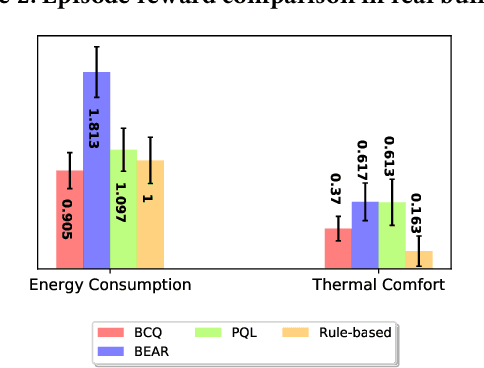
Batch reinforcement learning (BRL) is an emerging research area in the RL community. It learns exclusively from static datasets (i.e. replay buffers) without interaction with the environment. In the offline settings, existing replay experiences are used as prior knowledge for BRL models to find the optimal policy. Thus, generating replay buffers is crucial for BRL model benchmark. In our B2RL (Building Batch RL) dataset, we collected real-world data from our building management systems, as well as buffers generated by several behavioral policies in simulation environments. We believe it could help building experts on BRL research. To the best of our knowledge, we are the first to open-source building datasets for the purpose of BRL learning.