 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching Skeleton-based Activity Representations with Heterogeneous Signals for HAR
Mar 17, 2025In human activity recognition (HAR), activity labels have typically been encoded in one-hot format, which has a recent shift towards using textual representations to provide contextual knowledge. Here, we argue that HAR should be anchored to physical motion data, as motion forms the basis of activity and applies effectively across sensing systems, whereas text is inherently limited. We propose SKELAR, a novel HAR framework that pretrains activity representations from skeleton data and matches them with heterogeneous HAR signals. Our method addresses two major challenges: (1) capturing core motion knowledge without context-specific details. We achieve this through a self-supervised coarse angle reconstruction task that recovers joint rotation angles, invariant to both users and deployments; (2) adapting the representations to downstream tasks with varying modalities and focuses. To address this, we introduce a self-attention matching module that dynamically prioritizes relevant body parts in a data-driven manner. Given the lack of corresponding labels in existing skeleton data, we establish MASD, a new HAR dataset with IMU, WiFi, and skeleton, collected from 20 subjects performing 27 activities. This is the first broadly applicable HAR dataset with time-synchronized data across three modalities. Experiments show that SKELAR achieves the state-of-the-art performance in both full-shot and few-shot settings. We also demonstrate that SKELAR can effectively leverage synthetic skeleton data to extend its use in scenarios without skeleton collections.
Orthogonal Calibration for Asynchronous Federated Learning
Feb 21, 2025Asynchronous federated learning mitigates the inefficiency of conventional synchronous aggregation by integrating updates as they arrive and adjusting their influence based on staleness. Due to asynchrony and data heterogeneity, learning objectives at the global and local levels are inherently inconsistent -- global optimization trajectories may conflict with ongoing local updates. Existing asynchronous methods simply distribute the latest global weights to clients, which can overwrite local progress and cause model drift. In this paper, we propose OrthoFL, an orthogonal calibration framework that decouples global and local learning progress and adjusts global shifts to minimize interference before merging them into local models. In OrthoFL, clients and the server maintain separate model weights. Upon receiving an update, the server aggregates it into the global weights via a moving average. For client weights, the server computes the global weight shift accumulated during the client's delay and removes the components aligned with the direction of the received update. The resulting parameters lie in a subspace orthogonal to the client update and preserve the maximal information from the global progress. The calibrated global shift is then merged into the client weights for further training. Extensive experiments show that OrthoFL improves accuracy by 9.6% and achieves a 12$\times$ speedup compared to synchronous methods. Moreover, it consistently outperforms state-of-the-art asynchronous baselines under various delay patterns and heterogeneity scenarios.
Downstream Task Guided Masking Learning in Masked Autoencoders Using Multi-Level Optimization
Feb 28, 2024



Masked Autoencoder (MAE) is a notable method for self-supervised pretraining in visual representation learning. It operates by randomly masking image patches and reconstructing these masked patches using the unmasked ones. A key limitation of MAE lies in its disregard for the varying informativeness of different patches, as it uniformly selects patches to mask. To overcome this, some approaches propose masking based on patch informativeness. However, these methods often do not consider the specific requirements of downstream tasks, potentially leading to suboptimal representations for these tasks. In response, we introduce the Multi-level Optimized Mask Autoencoder (MLO-MAE), a novel framework that leverages end-to-end feedback from downstream tasks to learn an optimal masking strategy during pretraining. Our experimental findings highlight MLO-MAE's significant advancements in visual representation learning. Compared to existing methods, it demonstrates remarkable improvements across diverse datasets and tasks, showcasing its adaptability and efficiency. Our code is available at: https://github.com/Alexiland/MLOMAE
Large Language Models for Time Series: A Survey
Feb 06, 2024



Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) alignment techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
Misusing Tools in Large Language Models With Visual Adversarial Examples
Oct 04, 2023



Large Language Models (LLMs) are being enhanced with the ability to use tools and to process multiple modalities. These new capabilities bring new benefits and also new security risks. In this work, we show that an attacker can use visual adversarial examples to cause attacker-desired tool usage. For example, the attacker could cause a victim LLM to delete calendar events, leak private conversations and book hotels. Different from prior work, our attacks can affect the confidentiality and integrity of user resources connected to the LLM while being stealthy and generalizable to multiple input prompts. We construct these attacks using gradient-based adversarial training and characterize performance along multiple dimensions. We find that our adversarial images can manipulate the LLM to invoke tools following real-world syntax almost always (~98%) while maintaining high similarity to clean images (~0.9 SSIM). Furthermore, using human scoring and automated metrics, we find that the attacks do not noticeably affect the conversation (and its semantics) between the user and the LLM.
Modeling Label Semantics Improves Activity Recognition
Jan 01, 2023



Human activity recognition (HAR) aims to classify sensory time series into different activities, with wide applications in activity tracking, healthcare, human computer interaction, etc. Existing HAR works improve recognition performance by designing more complicated feature extraction methods, but they neglect the label semantics by simply treating labels as integer IDs. We find that many activities in the current HAR datasets have shared label names, e.g., "open door" and "open fridge", "walk upstairs" and "walk downstairs". Through some exploratory analysis, we find that such shared structure in activity names also maps to similarity in the input features. To this end, we design a sequence-to-sequence framework to decode the label name semantics rather than classifying labels as integer IDs. Our proposed method decomposes learning activities into learning shared tokens ("open", "walk"), which is easier than learning the joint distribution ("open fridge", "walk upstairs") and helps transfer learning to activities with insufficient data samples. For datasets originally without shared tokens in label names, we also offer an automated method, using OpenAI's ChatGPT, to generate shared actions and objects. Extensive experiments on seven HAR benchmark datasets demonstrate the state-of-the-art performance of our method. We also show better performance in the long-tail activity distribution settings and few-shot settings.
Federated Learning with Client-Exclusive Classes
Jan 01, 2023


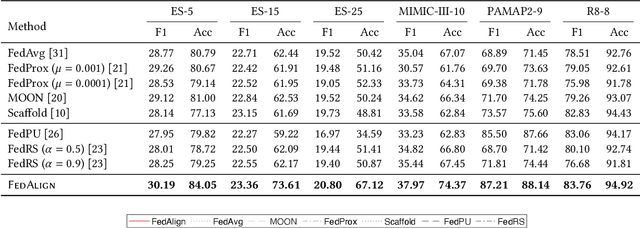
Existing federated classification algorithms typically assume the local annotations at every client cover the same set of classes. In this paper, we aim to lift such an assumption and focus on a more general yet practical non-IID setting where every client can work on non-identical and even disjoint sets of classes (i.e., client-exclusive classes), and the clients have a common goal which is to build a global classification model to identify the union of these classes. Such heterogeneity in client class sets poses a new challenge: how to ensure different clients are operating in the same latent space so as to avoid the drift after aggregation? We observe that the classes can be described in natural languages (i.e., class names) and these names are typically safe to share with all parties. Thus, we formulate the classification problem as a matching process between data representations and class representations and break the classification model into a data encoder and a label encoder. We leverage the natural-language class names as the common ground to anchor the class representations in the label encoder. In each iteration, the label encoder updates the class representations and regulates the data representations through matching. We further use the updated class representations at each round to annotate data samples for locally-unaware classes according to similarity and distill knowledge to local models. Extensive experiments on four real-world datasets show that the proposed method can outperform various classical and state-of-the-art federated learning methods designed for learning with non-IID data.
ACES -- Automatic Configuration of Energy Harvesting Sensors with Reinforcement Learning
Sep 04, 2019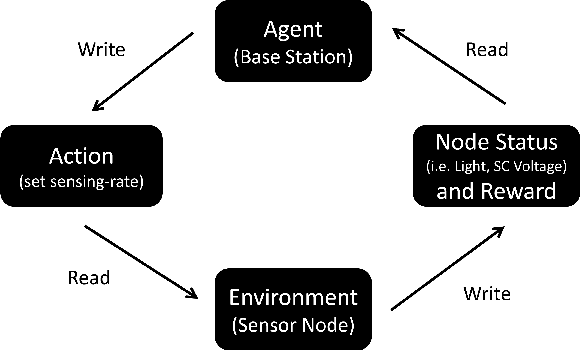



Internet of Things forms the backbone of modern building applications. Wireless sensors are being increasingly adopted for their flexibility and reduced cost of deployment. However, most wireless sensors are powered by batteries today and large deployments are inhibited by manual battery replacement. Energy harvesting sensors provide an attractive alternative, but they need to provide adequate quality of service to applications given uncertain energy availability. We propose using reinforcement learning to optimize the operation of energy harvesting sensors to maximize sensing quality with available energy. We present our system ACES that uses reinforcement learning for periodic and event-driven sensing indoors with ambient light energy harvesting. Our custom-built board uses a supercapacitor to store energy temporarily, senses light, motion events and relays them using Bluetooth Low Energy. Using simulations and real deployments, we show that our sensor nodes adapt to their lighting conditions and continuously sends measurements and events across nights and weekends. We use deployment data to continually adapt sensing to changing environmental patterns and transfer learning to reduce the training time in real deployments. In our 60 node deployment lasting two weeks, we observe a dead time of 0.1%. The periodic sensors that measure luminosity have a mean sampling period of 90 seconds and the event sensors that detect motion with PIR captured 86% of the events on average compared to a battery-powered node.
Associative Convolutional Layers
Jun 12, 2019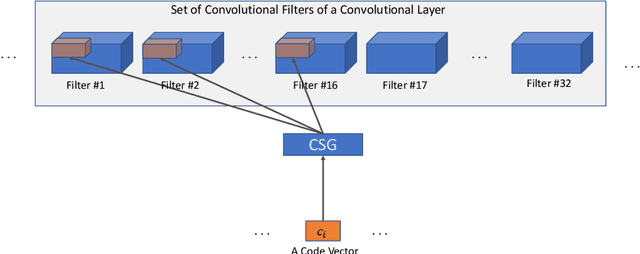
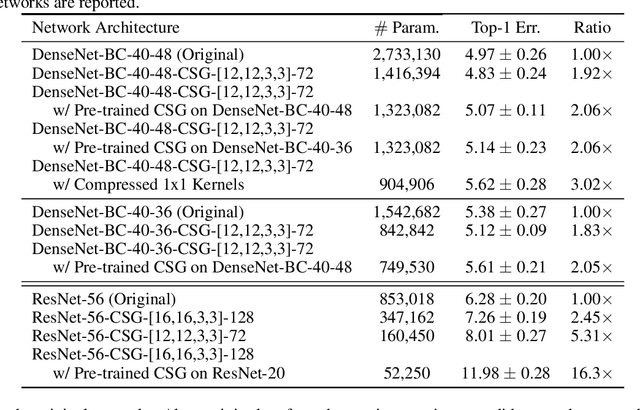
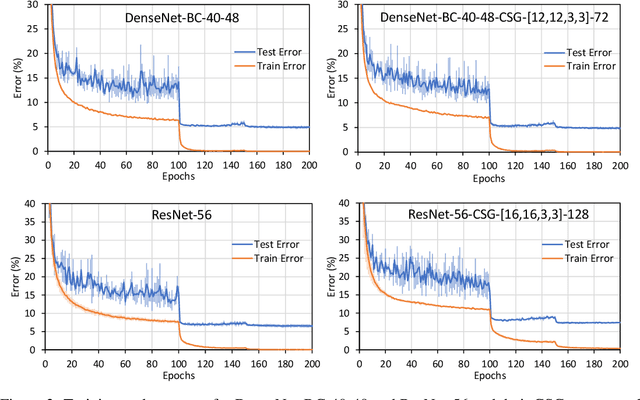
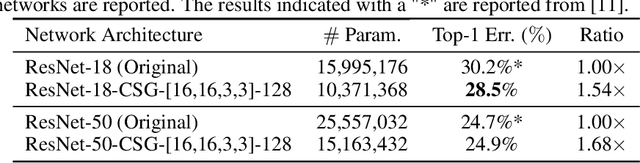
Motivated by the necessity for parameter efficiency in distributed machine learning and AI-enabled edge devices, we provide a general and easy to implement method for significantly reducing the number of parameters of Convolutional Neural Networks (CNNs), during both the training and inference phases. We introduce a simple auxiliary neural network which can generate the convolutional filters of any CNN architecture from a low dimensional latent space. This auxiliary neural network, which we call "Convolutional Slice Generator" (CSG), is unique to the network and provides the association between its convolutional layers. During the training of the CNN, instead of training the filters of the convolutional layers, only the parameters of the CSG and their corresponding `code vectors' are trained. This results in a significant reduction of the number of parameters due to the fact that the CNN can be fully represented using only the parameters of the CSG, the code vectors, the fully connected layers, and the architecture of the CNN. To show the capability of our method, we apply it to ResNet and DenseNet architectures, using the CIFAR-10 dataset without any hyper-parameter tuning. Experiments show that our approach, even when applied to already compressed and efficient CNNs such as DenseNet-BC, significantly reduces the number of network parameters. In two models based on DenseNet-BC with $\approx 2\times$ reduction in one of them we had a slight improvement in accuracy and in another one, with $\approx 2\times$ reduction the change in accuracy is negligible. In case of ResNet-56, $\approx 2.5\times$ reduction leads to an accuracy loss within $1\%$.
Binarized Convolutional Neural Networks with Separable Filters for Efficient Hardware Acceleration
Jul 15, 2017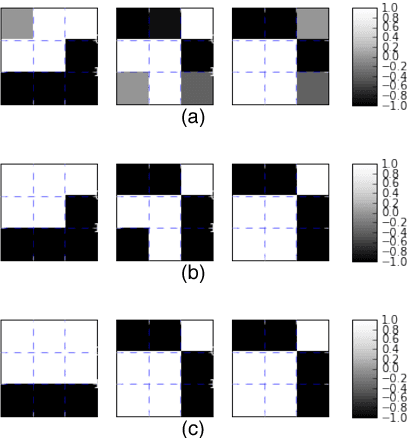
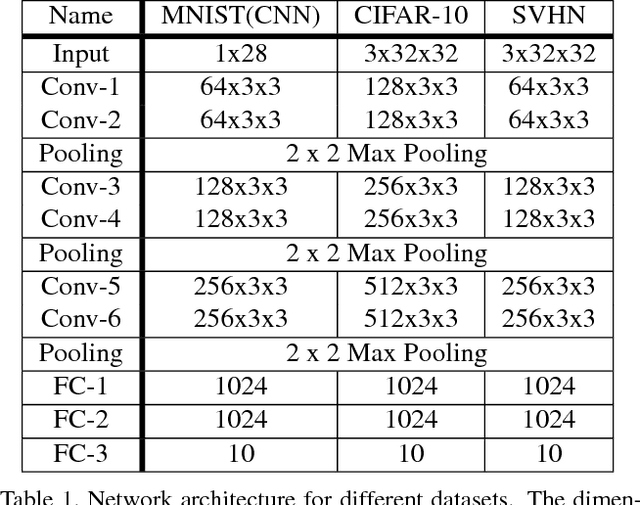
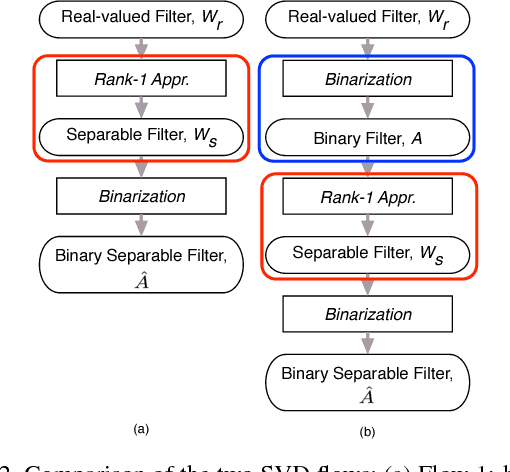
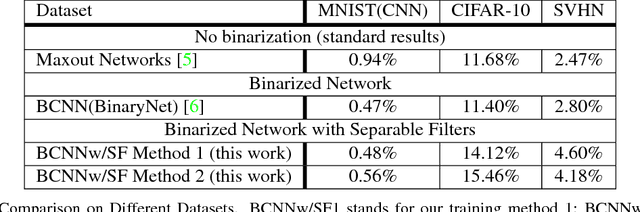
State-of-the-art convolutional neural networks are enormously costly in both compute and memory, demanding massively parallel GPUs for execution. Such networks strain the computational capabilities and energy available to embedded and mobile processing platforms, restricting their use in many important applications. In this paper, we push the boundaries of hardware-effective CNN design by proposing BCNN with Separable Filters (BCNNw/SF), which applies Singular Value Decomposition (SVD) on BCNN kernels to further reduce computational and storage complexity. To enable its implementation, we provide a closed form of the gradient over SVD to calculate the exact gradient with respect to every binarized weight in backward propagation. We verify BCNNw/SF on the MNIST, CIFAR-10, and SVHN datasets, and implement an accelerator for CIFAR-10 on FPGA hardware. Our BCNNw/SF accelerator realizes memory savings of 17% and execution time reduction of 31.3% compared to BCNN with only minor accuracy sacrifices.