 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDownstream Task Guided Masking Learning in Masked Autoencoders Using Multi-Level Optimization
Feb 28, 2024



Masked Autoencoder (MAE) is a notable method for self-supervised pretraining in visual representation learning. It operates by randomly masking image patches and reconstructing these masked patches using the unmasked ones. A key limitation of MAE lies in its disregard for the varying informativeness of different patches, as it uniformly selects patches to mask. To overcome this, some approaches propose masking based on patch informativeness. However, these methods often do not consider the specific requirements of downstream tasks, potentially leading to suboptimal representations for these tasks. In response, we introduce the Multi-level Optimized Mask Autoencoder (MLO-MAE), a novel framework that leverages end-to-end feedback from downstream tasks to learn an optimal masking strategy during pretraining. Our experimental findings highlight MLO-MAE's significant advancements in visual representation learning. Compared to existing methods, it demonstrates remarkable improvements across diverse datasets and tasks, showcasing its adaptability and efficiency. Our code is available at: https://github.com/Alexiland/MLOMAE
Learning by Grouping: A Multilevel Optimization Framework for Improving Fairness in Classification without Losing Accuracy
Apr 02, 2023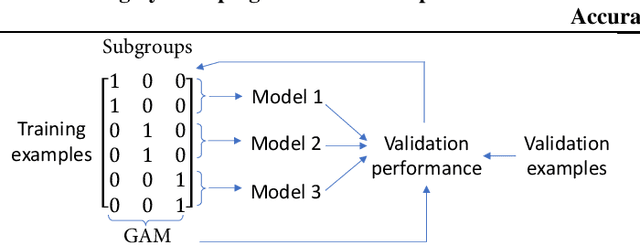
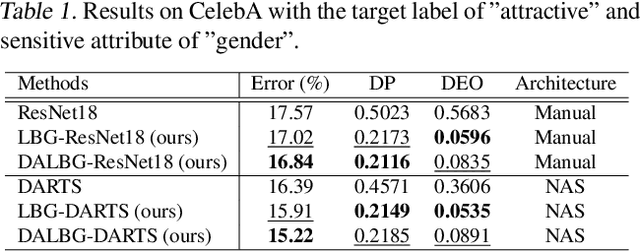
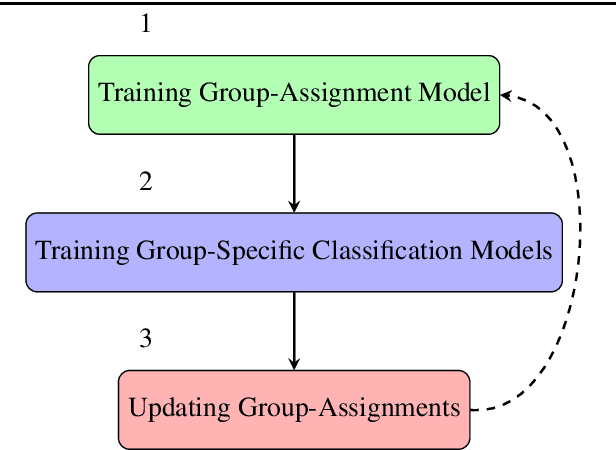
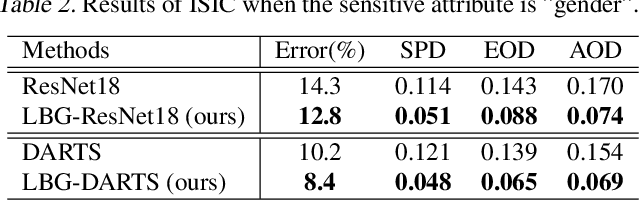
The integration of machine learning models in various real-world applications is becoming more prevalent to assist humans in their daily decision-making tasks as a result of recent advancements in this field. However, it has been discovered that there is a tradeoff between the accuracy and fairness of these decision-making tasks. In some cases, these AI systems can be unfair by exhibiting bias or discrimination against certain social groups, which can have severe consequences in real life. Inspired by one of the most well-known human learning skills called grouping, we address this issue by proposing a novel machine learning framework where the ML model learns to group a diverse set of problems into distinct subgroups to solve each subgroup using its specific sub-model. Our proposed framework involves three stages of learning, which are formulated as a three-level optimization problem: (i) learning to group problems into different subgroups; (ii) learning group-specific sub-models for problem-solving; and (iii) updating group assignments of training examples by minimizing the validation loss. These three learning stages are performed end-to-end in a joint manner using gradient descent. To improve fairness and accuracy, we develop an efficient optimization algorithm to solve this three-level optimization problem. To further reduce the risk of overfitting in small datasets, we incorporate domain adaptation techniques in the second stage of training. We further apply our method to neural architecture search. Extensive experiments on various datasets demonstrate our method's effectiveness and performance improvements in both fairness and accuracy. Our proposed Learning by Grouping can reduce overfitting and achieve state-of-the-art performances with fixed human-designed network architectures and searchable network architectures on various datasets.
ACuTE: Automatic Curriculum Transfer from Simple to Complex Environments
Apr 11, 2022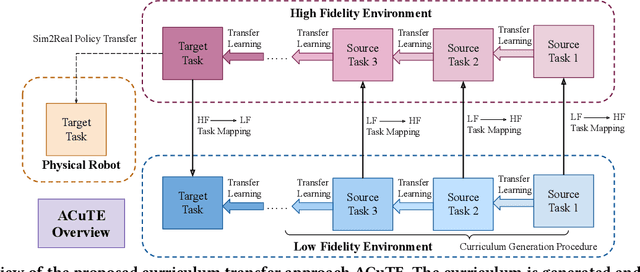
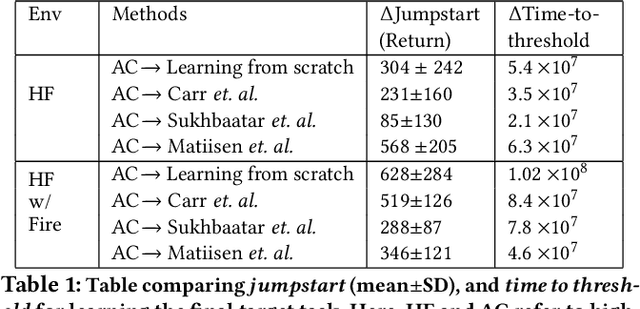
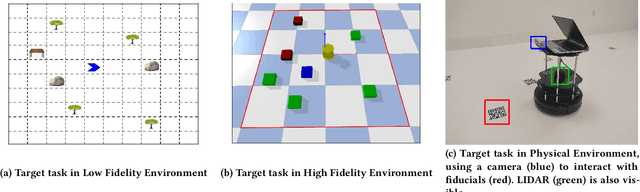

Despite recent advances in Reinforcement Learning (RL), many problems, especially real-world tasks, remain prohibitively expensive to learn. To address this issue, several lines of research have explored how tasks, or data samples themselves, can be sequenced into a curriculum to learn a problem that may otherwise be too difficult to learn from scratch. However, generating and optimizing a curriculum in a realistic scenario still requires extensive interactions with the environment. To address this challenge, we formulate the curriculum transfer problem, in which the schema of a curriculum optimized in a simpler, easy-to-solve environment (e.g., a grid world) is transferred to a complex, realistic scenario (e.g., a physics-based robotics simulation or the real world). We present "ACuTE", Automatic Curriculum Transfer from Simple to Complex Environments, a novel framework to solve this problem, and evaluate our proposed method by comparing it to other baseline approaches (e.g., domain adaptation) designed to speed up learning. We observe that our approach produces improved jumpstart and time-to-threshold performance even when adding task elements that further increase the difficulty of the realistic scenario. Finally, we demonstrate that our approach is independent of the learning algorithm used for curriculum generation, and is Sim2Real transferable to a real world scenario using a physical robot.
Learning from Mistakes -- A Framework for Neural Architecture Search
Nov 11, 2021
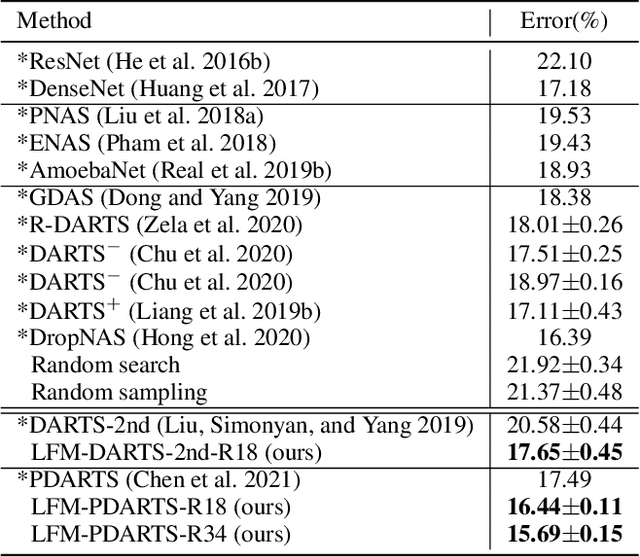
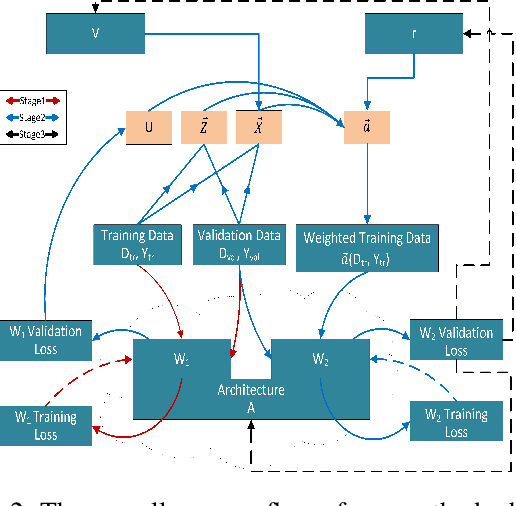
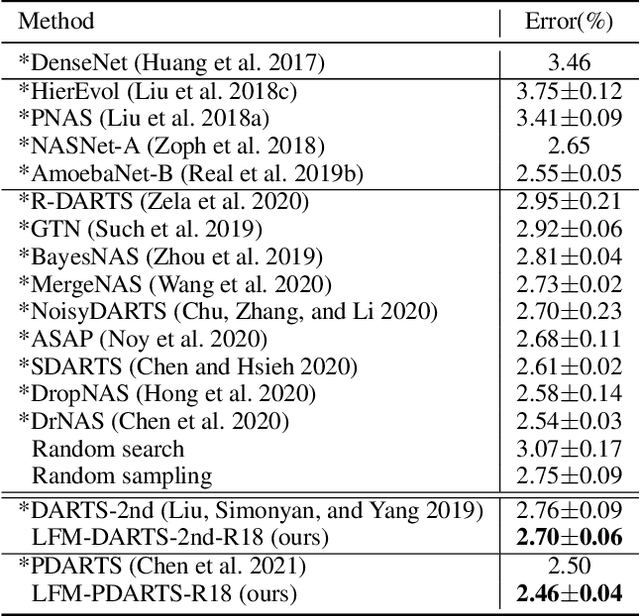
Learning from one's mistakes is an effective human learning technique where the learners focus more on the topics where mistakes were made, so as to deepen their understanding. In this paper, we investigate if this human learning strategy can be applied in machine learning. We propose a novel machine learning method called Learning From Mistakes (LFM), wherein the learner improves its ability to learn by focusing more on the mistakes during revision. We formulate LFM as a three-stage optimization problem: 1) learner learns; 2) learner re-learns focusing on the mistakes, and; 3) learner validates its learning. We develop an efficient algorithm to solve the LFM problem. We apply the LFM framework to neural architecture search on CIFAR-10, CIFAR-100, and Imagenet. Experimental results strongly demonstrate the effectiveness of our model.
A Framework for Multisensory Foresight for Embodied Agents
Sep 15, 2021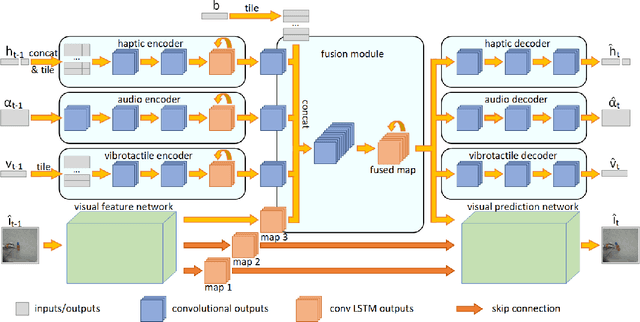
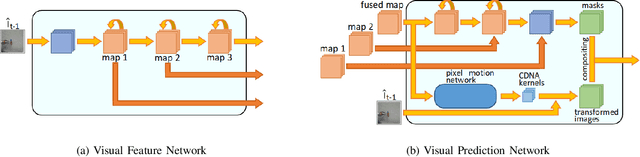
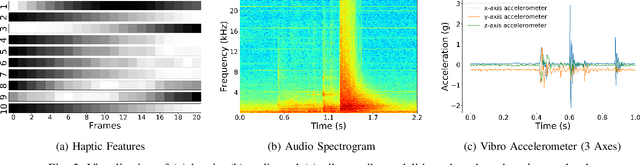
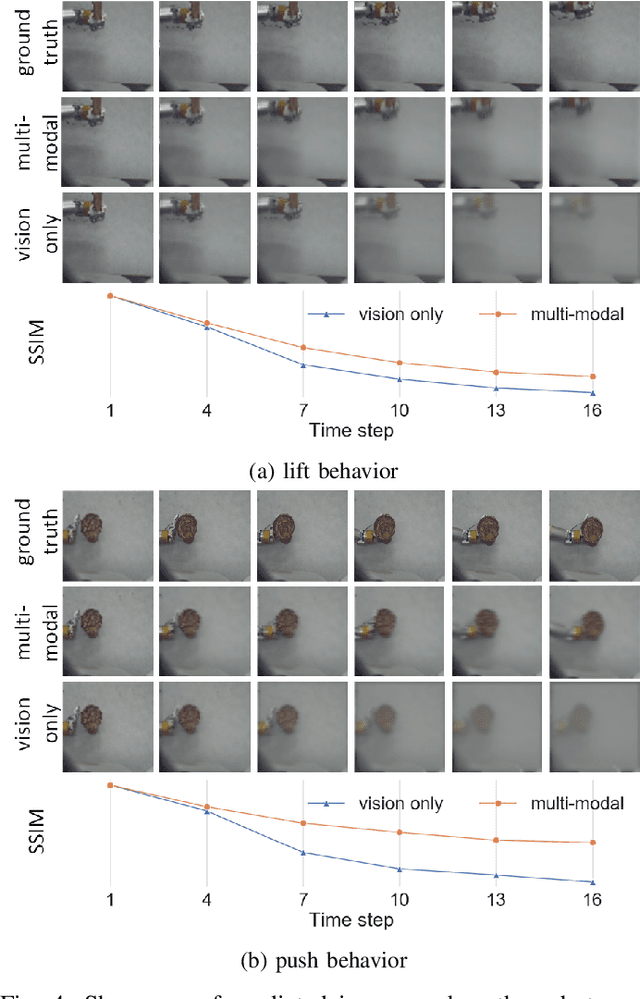
Predicting future sensory states is crucial for learning agents such as robots, drones, and autonomous vehicles. In this paper, we couple multiple sensory modalities with exploratory actions and propose a predictive neural network architecture to address this problem. Most existing approaches rely on large, manually annotated datasets, or only use visual data as a single modality. In contrast, the unsupervised method presented here uses multi-modal perceptions for predicting future visual frames. As a result, the proposed model is more comprehensive and can better capture the spatio-temporal dynamics of the environment, leading to more accurate visual frame prediction. The other novelty of our framework is the use of sub-networks dedicated to anticipating future haptic, audio, and tactile signals. The framework was tested and validated with a dataset containing 4 sensory modalities (vision, haptic, audio, and tactile) on a humanoid robot performing 9 behaviors multiple times on a large set of objects. While the visual information is the dominant modality, utilizing the additional non-visual modalities improves the accuracy of predictions.
Learning by Self-Explanation, with Application to Neural Architecture Search
Dec 23, 2020
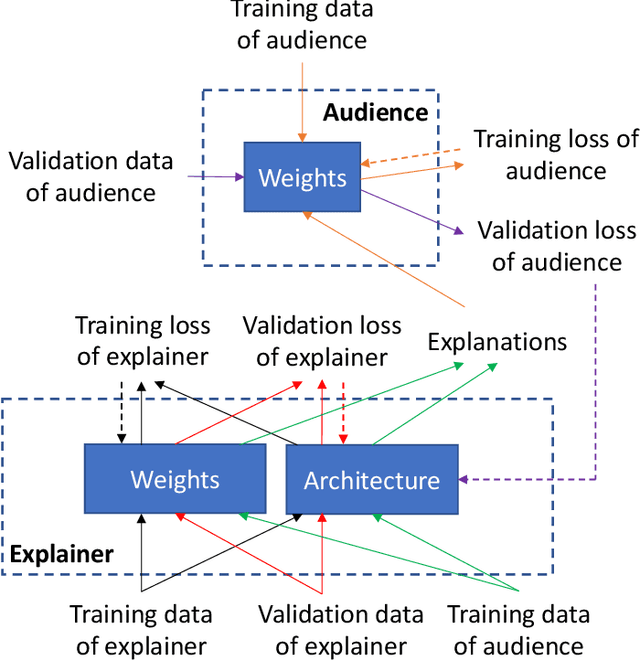
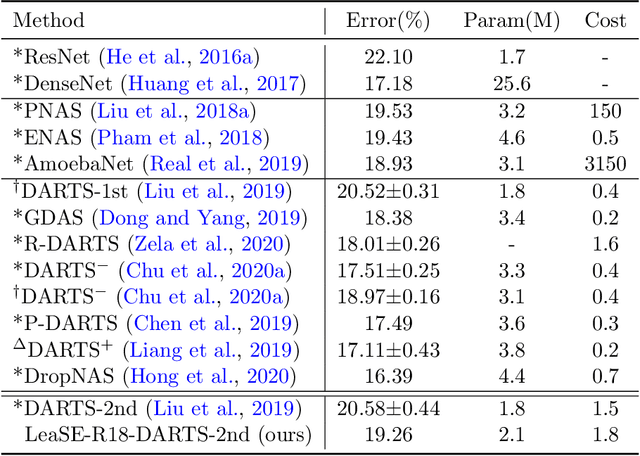
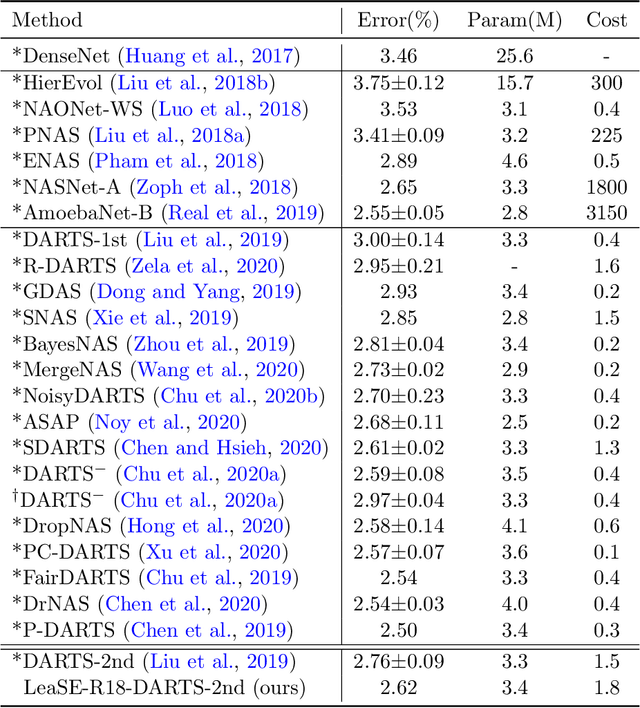
Learning by self-explanation, where students explain a learned topic to themselves for deepening their understanding of this topic, is a broadly used methodology in human learning and shows great effectiveness in improving learning outcome. We are interested in investigating whether this powerful learning technique can be borrowed from humans to improve the learning abilities of machines. We propose a novel learning approach called learning by self-explanation (LeaSE). In our approach, an explainer model improves its learning ability by trying to clearly explain to an audience model regarding how a prediction outcome is made. We propose a multi-level optimization framework to formulate LeaSE which involves four stages of learning: explainer learns; explainer explains; audience learns; explainer and audience validate themselves. We develop an efficient algorithm to solve the LeaSE problem. We apply our approach to neural architecture search on CIFAR-100, CIFAR-10, and ImageNet. The results demonstrate the effectiveness of our method.
DSRNA: Differentiable Search of Robust Neural Architectures
Dec 11, 2020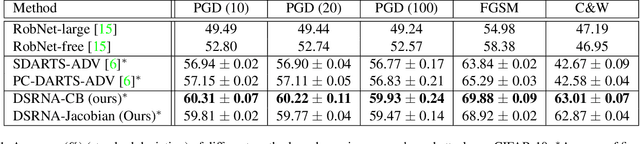
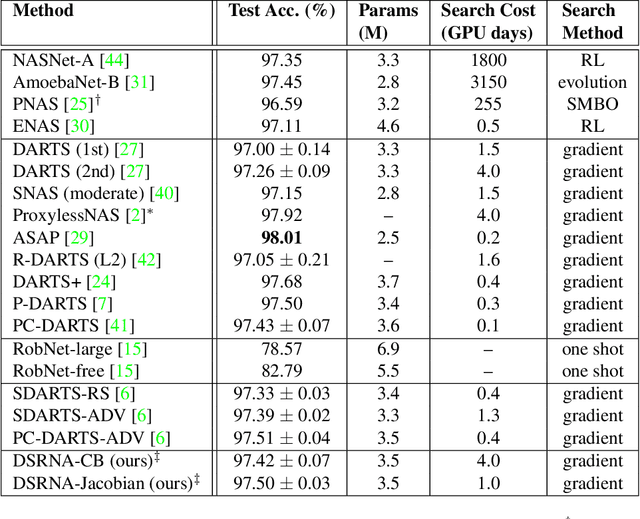
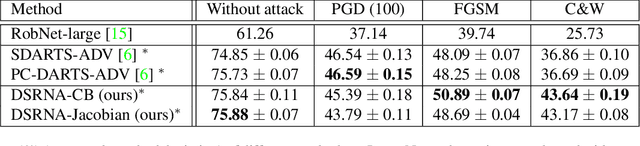
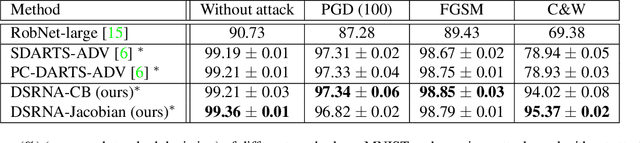
In deep learning applications, the architectures of deep neural networks are crucial in achieving high accuracy. Many methods have been proposed to search for high-performance neural architectures automatically. However, these searched architectures are prone to adversarial attacks. A small perturbation of the input data can render the architecture to change prediction outcomes significantly. To address this problem, we propose methods to perform differentiable search of robust neural architectures. In our methods, two differentiable metrics are defined to measure architectures' robustness, based on certified lower bound and Jacobian norm bound. Then we search for robust architectures by maximizing the robustness metrics. Different from previous approaches which aim to improve architectures' robustness in an implicit way: performing adversarial training and injecting random noise, our methods explicitly and directly maximize robustness metrics to harvest robust architectures. On CIFAR-10, ImageNet, and MNIST, we perform game-based evaluation and verification-based evaluation on the robustness of our methods. The experimental results show that our methods 1) are more robust to various norm-bound attacks than several robust NAS baselines; 2) are more accurate than baselines when there are no attacks; 3) have significantly higher certified lower bounds than baselines.
Pathway Activity Analysis and Metabolite Annotation for Untargeted Metabolomics using Probabilistic Modeling
Dec 12, 2019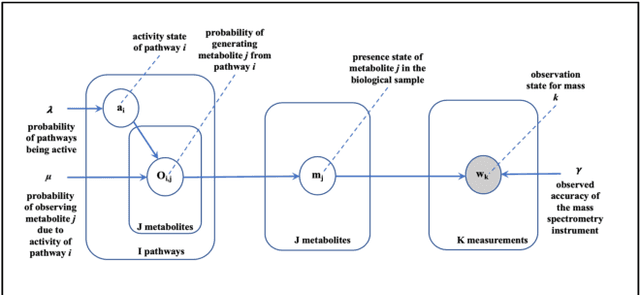
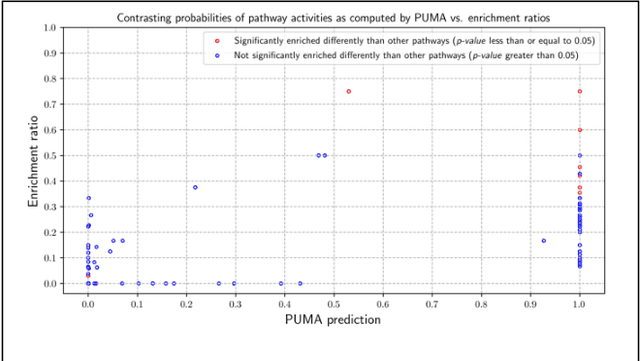
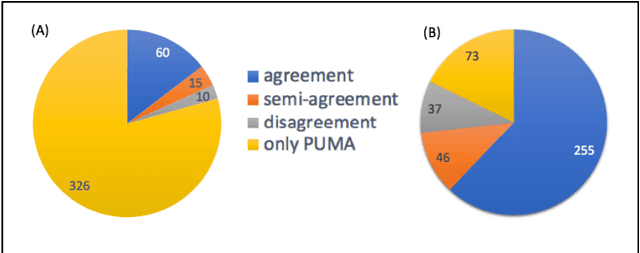
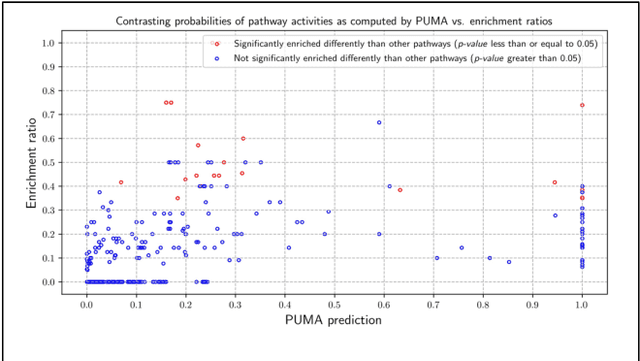
Motivation: Untargeted metabolomics comprehensively characterizes small molecules and elucidates activities of biochemical pathways within a biological sample. Despite computational advances, interpreting collected measurements and determining their biological role remains a challenge. Results: To interpret measurements, we present an inference-based approach, termed Probabilistic modeling for Untargeted Metabolomics Analysis (PUMA). Our approach captures measurements and known information about the sample under study in a generative model and uses stochastic sampling to compute posterior probability distributions. PUMA predicts the likelihood of pathways being active, and then derives a probabilistic annotation, which assigns chemical identities to the measurements. PUMA is validated on synthetic datasets. When applied to test cases, the resulting pathway activities are biologically meaningful and distinctly different from those obtained using statistical pathway enrichment techniques. Annotation results are in agreement to those obtained using other tools that utilize additional information in the form of spectral signatures. Importantly, PUMA annotates many additional measurements.