 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDownstream Task Guided Masking Learning in Masked Autoencoders Using Multi-Level Optimization
Feb 28, 2024



Masked Autoencoder (MAE) is a notable method for self-supervised pretraining in visual representation learning. It operates by randomly masking image patches and reconstructing these masked patches using the unmasked ones. A key limitation of MAE lies in its disregard for the varying informativeness of different patches, as it uniformly selects patches to mask. To overcome this, some approaches propose masking based on patch informativeness. However, these methods often do not consider the specific requirements of downstream tasks, potentially leading to suboptimal representations for these tasks. In response, we introduce the Multi-level Optimized Mask Autoencoder (MLO-MAE), a novel framework that leverages end-to-end feedback from downstream tasks to learn an optimal masking strategy during pretraining. Our experimental findings highlight MLO-MAE's significant advancements in visual representation learning. Compared to existing methods, it demonstrates remarkable improvements across diverse datasets and tasks, showcasing its adaptability and efficiency. Our code is available at: https://github.com/Alexiland/MLOMAE
Large Language Models for Time Series: A Survey
Feb 06, 2024



Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) alignment techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
Physics-Informed Data Denoising for Real-Life Sensing Systems
Nov 12, 2023
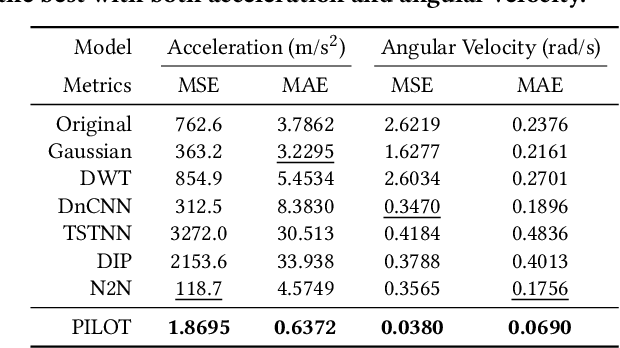


Sensors measuring real-life physical processes are ubiquitous in today's interconnected world. These sensors inherently bear noise that often adversely affects performance and reliability of the systems they support. Classic filtering-based approaches introduce strong assumptions on the time or frequency characteristics of sensory measurements, while learning-based denoising approaches typically rely on using ground truth clean data to train a denoising model, which is often challenging or prohibitive to obtain for many real-world applications. We observe that in many scenarios, the relationships between different sensor measurements (e.g., location and acceleration) are analytically described by laws of physics (e.g., second-order differential equation). By incorporating such physics constraints, we can guide the denoising process to improve even in the absence of ground truth data. In light of this, we design a physics-informed denoising model that leverages the inherent algebraic relationships between different measurements governed by the underlying physics. By obviating the need for ground truth clean data, our method offers a practical denoising solution for real-world applications. We conducted experiments in various domains, including inertial navigation, CO2 monitoring, and HVAC control, and achieved state-of-the-art performance compared with existing denoising methods. Our method can denoise data in real time (4ms for a sequence of 1s) for low-cost noisy sensors and produces results that closely align with those from high-precision, high-cost alternatives, leading to an efficient, cost-effective approach for more accurate sensor-based systems.
Towards Diverse and Coherent Augmentation for Time-Series Forecasting
Mar 24, 2023



Time-series data augmentation mitigates the issue of insufficient training data for deep learning models. Yet, existing augmentation methods are mainly designed for classification, where class labels can be preserved even if augmentation alters the temporal dynamics. We note that augmentation designed for forecasting requires diversity as well as coherence with the original temporal dynamics. As time-series data generated by real-life physical processes exhibit characteristics in both the time and frequency domains, we propose to combine Spectral and Time Augmentation (STAug) for generating more diverse and coherent samples. Specifically, in the frequency domain, we use the Empirical Mode Decomposition to decompose a time series and reassemble the subcomponents with random weights. This way, we generate diverse samples while being coherent with the original temporal relationships as they contain the same set of base components. In the time domain, we adapt a mix-up strategy that generates diverse as well as linearly in-between coherent samples. Experiments on five real-world time-series datasets demonstrate that STAug outperforms the base models without data augmentation as well as state-of-the-art augmentation methods.
Modeling Label Semantics Improves Activity Recognition
Jan 01, 2023



Human activity recognition (HAR) aims to classify sensory time series into different activities, with wide applications in activity tracking, healthcare, human computer interaction, etc. Existing HAR works improve recognition performance by designing more complicated feature extraction methods, but they neglect the label semantics by simply treating labels as integer IDs. We find that many activities in the current HAR datasets have shared label names, e.g., "open door" and "open fridge", "walk upstairs" and "walk downstairs". Through some exploratory analysis, we find that such shared structure in activity names also maps to similarity in the input features. To this end, we design a sequence-to-sequence framework to decode the label name semantics rather than classifying labels as integer IDs. Our proposed method decomposes learning activities into learning shared tokens ("open", "walk"), which is easier than learning the joint distribution ("open fridge", "walk upstairs") and helps transfer learning to activities with insufficient data samples. For datasets originally without shared tokens in label names, we also offer an automated method, using OpenAI's ChatGPT, to generate shared actions and objects. Extensive experiments on seven HAR benchmark datasets demonstrate the state-of-the-art performance of our method. We also show better performance in the long-tail activity distribution settings and few-shot settings.