 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHasse Diagrams for Attention: A Partial Order Framework for Designing Transformer Masks
Jun 08, 2026During the training of large Transformer models, attention masks regulate the scope and direction of information flow across a sequence. Numerous mask variants exist, and operators such as FlexAttention already support arbitrary attention masks. Nevertheless, a systematic formal analysis of the information-flow structure induced by arbitrary masks has been missing. This paper develops a complete theoretical framework. We prove that, with sufficient depth, the information flow of a multi-layer Transformer converges to a Hasse diagram -- a directed acyclic graph representing a partial order. Building on this, we recast the design of parallel training tasks as the problem of finding a minimal common supergraph of Hasse diagrams, and we establish a criterion for the minimal common supergraph. This yields a constructive method to derive attention masks directly from a family of tasks. Applying the framework, we design two novel masks: a block-generation attention mask that ensures training-inference consistency (Block Two-Stream Attention), and a fully supervised bidirectional attention mask (Butterfly Attention). These results demonstrate the framework's capacity to discover new structures.
CODA: Rewriting Transformer Blocks as GEMM-Epilogue Programs
May 20, 2026Transformer training systems are built around dense linear algebra, yet a nontrivial fraction of end-to-end time is spent on surrounding memory-bound operators. Normalization, activations, residual updates, reductions, and related computations repeatedly move large intermediate tensors through global memory while performing little arithmetic, making data movement an increasingly important bottleneck in otherwise highly optimized training stacks. We introduce CODA, a GPU kernel abstraction that expresses these computations as GEMM-plus-epilogue programs. CODA is based on the observation that many Transformer operators exposed as separate framework kernels can be algebraically reparameterized to execute while a GEMM output tile remains on chip, before it is written to memory. The abstraction fixes the GEMM mainloop and exposes a small set of composable epilogue primitives for scaling, reductions, pairwise transformations, and accumulation. This constrained interface preserves the performance structure of expert-written GEMMs while remaining expressive enough to cover nearly all non-attention computation in the forward and backward pass of a standard Transformer block. Across representative Transformer workloads, both human- and LLM-authored CODA kernels achieve high performance, suggesting that GEMM-plus-epilogue programming offers a practical path toward combining framework-level productivity with hardware-level efficiency.
Fast KV Compaction via Attention Matching
Feb 18, 2026Scaling language models to long contexts is often bottlenecked by the size of the key-value (KV) cache. In deployed settings, long contexts are typically managed through compaction in token space via summarization. However, summarization can be highly lossy, substantially harming downstream performance. Recent work on Cartridges has shown that it is possible to train highly compact KV caches in latent space that closely match full-context performance, but at the cost of slow and expensive end-to-end optimization. This work describes an approach for fast context compaction in latent space through Attention Matching, which constructs compact keys and values to reproduce attention outputs and preserve attention mass at a per-KV-head level. We show that this formulation naturally decomposes into simple subproblems, some of which admit efficient closed-form solutions. Within this framework, we develop a family of methods that significantly push the Pareto frontier of compaction time versus quality, achieving up to 50x compaction in seconds on some datasets with little quality loss.
FoBa: A Foreground-Background co-Guided Method and New Benchmark for Remote Sensing Semantic Change Detection
Sep 19, 2025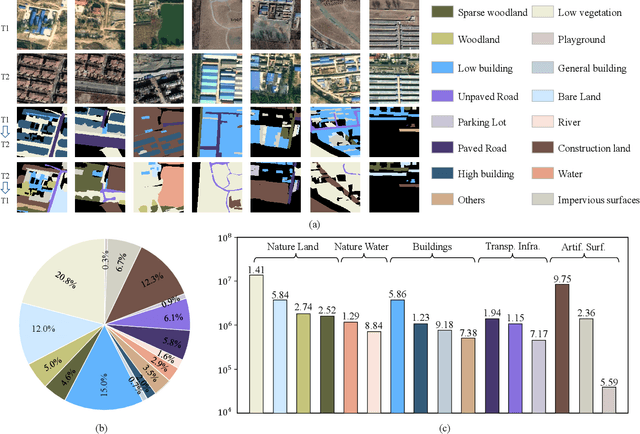

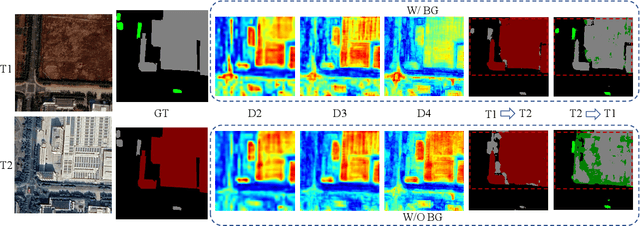
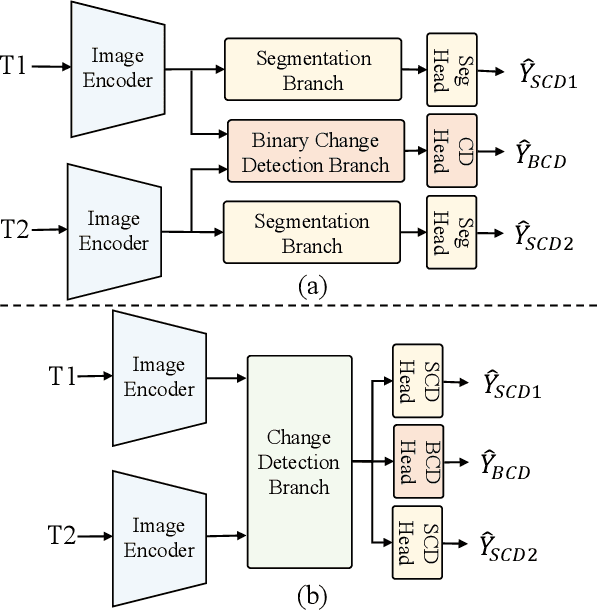
Despite the remarkable progress achieved in remote sensing semantic change detection (SCD), two major challenges remain. At the data level, existing SCD datasets suffer from limited change categories, insufficient change types, and a lack of fine-grained class definitions, making them inadequate to fully support practical applications. At the methodological level, most current approaches underutilize change information, typically treating it as a post-processing step to enhance spatial consistency, which constrains further improvements in model performance. To address these issues, we construct a new benchmark for remote sensing SCD, LevirSCD. Focused on the Beijing area, the dataset covers 16 change categories and 210 specific change types, with more fine-grained class definitions (e.g., roads are divided into unpaved and paved roads). Furthermore, we propose a foreground-background co-guided SCD (FoBa) method, which leverages foregrounds that focus on regions of interest and backgrounds enriched with contextual information to guide the model collaboratively, thereby alleviating semantic ambiguity while enhancing its ability to detect subtle changes. Considering the requirements of bi-temporal interaction and spatial consistency in SCD, we introduce a Gated Interaction Fusion (GIF) module along with a simple consistency loss to further enhance the model's detection performance. Extensive experiments on three datasets (SECOND, JL1, and the proposed LevirSCD) demonstrate that FoBa achieves competitive results compared to current SOTA methods, with improvements of 1.48%, 3.61%, and 2.81% in the SeK metric, respectively. Our code and dataset are available at https://github.com/zmoka-zht/FoBa.
Self-Adapting Language Models
Jun 12, 2025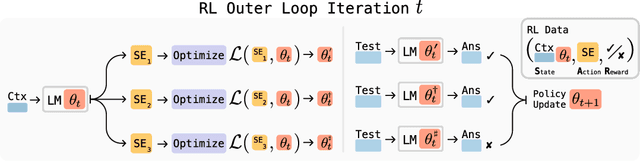


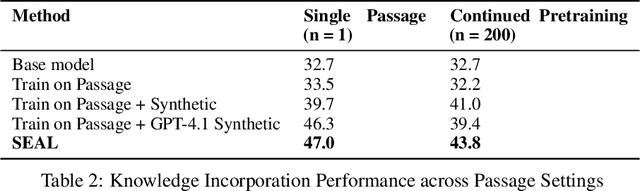
Large language models (LLMs) are powerful but static; they lack mechanisms to adapt their weights in response to new tasks, knowledge, or examples. We introduce Self-Adapting LLMs (SEAL), a framework that enables LLMs to self-adapt by generating their own finetuning data and update directives. Given a new input, the model produces a self-edit-a generation that may restructure the information in different ways, specify optimization hyperparameters, or invoke tools for data augmentation and gradient-based updates. Through supervised finetuning (SFT), these self-edits result in persistent weight updates, enabling lasting adaptation. To train the model to produce effective self-edits, we use a reinforcement learning loop with the downstream performance of the updated model as the reward signal. Unlike prior approaches that rely on separate adaptation modules or auxiliary networks, SEAL directly uses the model's own generation to control its adaptation process. Experiments on knowledge incorporation and few-shot generalization show that SEAL is a promising step toward language models capable of self-directed adaptation. Our website and code is available at https://jyopari.github.io/posts/seal.
Log-Linear Attention
Jun 05, 2025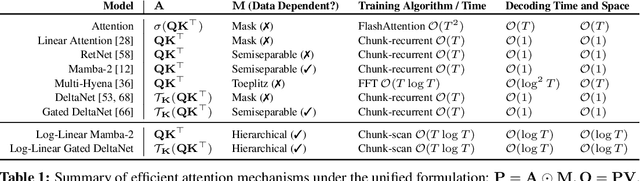
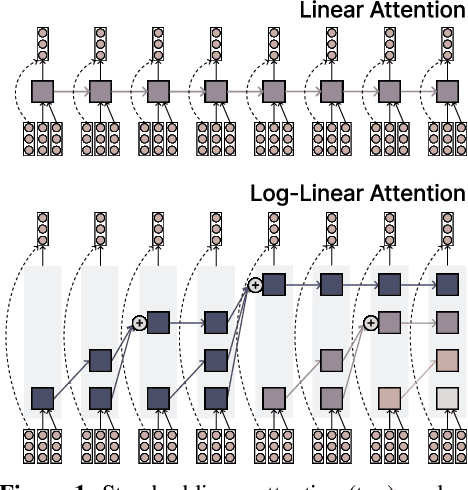
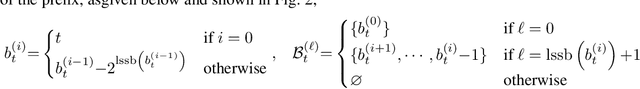
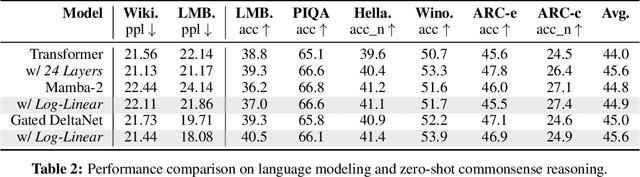
The attention mechanism in Transformers is an important primitive for accurate and scalable sequence modeling. Its quadratic-compute and linear-memory complexity however remain significant bottlenecks. Linear attention and state-space models enable linear-time, constant-memory sequence modeling and can moreover be trained efficiently through matmul-rich parallelization across sequence length. However, at their core these models are still RNNs, and thus their use of a fixed-size hidden state to model the context is a fundamental limitation. This paper develops log-linear attention, an attention mechanism that balances linear attention's efficiency and the expressiveness of softmax attention. Log-linear attention replaces the fixed-size hidden state with a logarithmically growing set of hidden states. We show that with a particular growth function, log-linear attention admits a similarly matmul-rich parallel form whose compute cost is log-linear in sequence length. Log-linear attention is a general framework and can be applied on top of existing linear attention variants. As case studies, we instantiate log-linear variants of two recent architectures -- Mamba-2 and Gated DeltaNet -- and find they perform well compared to their linear-time variants.
On the Duality between Gradient Transformations and Adapters
Feb 19, 2025We study memory-efficient optimization of neural networks with linear gradient transformations, where the gradients are linearly mapped to a lower dimensional space than the full parameter space, thus saving memory required for gradient accumulation and optimizer state persistence. The model parameters are updated by first performing an optimization step in the lower dimensional space and then going back into the original parameter space via the linear map's transpose. We show that optimizing the model in this transformed space is equivalent to reparameterizing the original model through a linear adapter that additively modifies the model parameters, and then only optimizing the adapter's parameters. When the transformation is Kronecker-factored, this establishes an equivalence between GaLore and one-sided LoRA. We show that this duality between gradient transformations and adapter-based reparameterizations unifies existing approaches to memory-efficient training and suggests new techniques for improving training efficiency and memory use.
Pushing the Limits of Large Language Model Quantization via the Linearity Theorem
Nov 26, 2024



Quantizing large language models has become a standard way to reduce their memory and computational costs. Typically, existing methods focus on breaking down the problem into individual layer-wise sub-problems, and minimizing per-layer error, measured via various metrics. Yet, this approach currently lacks theoretical justification and the metrics employed may be sub-optimal. In this paper, we present a "linearity theorem" establishing a direct relationship between the layer-wise $\ell_2$ reconstruction error and the model perplexity increase due to quantization. This insight enables two novel applications: (1) a simple data-free LLM quantization method using Hadamard rotations and MSE-optimal grids, dubbed HIGGS, which outperforms all prior data-free approaches such as the extremely popular NF4 quantized format, and (2) an optimal solution to the problem of finding non-uniform per-layer quantization levels which match a given compression constraint in the medium-bitwidth regime, obtained by reduction to dynamic programming. On the practical side, we demonstrate improved accuracy-compression trade-offs on Llama-3.1 and 3.2-family models, as well as on Qwen-family models. Further, we show that our method can be efficiently supported in terms of GPU kernels at various batch sizes, advancing both data-free and non-uniform quantization for LLMs.
The Surprising Effectiveness of Test-Time Training for Abstract Reasoning
Nov 11, 2024
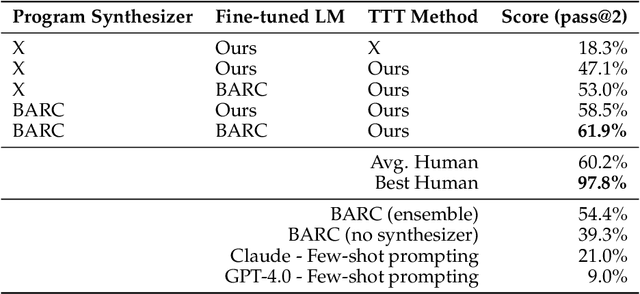
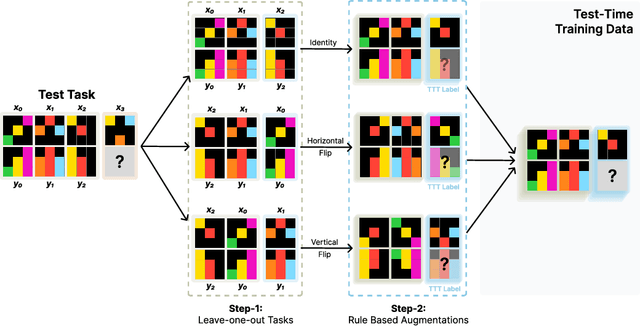
Language models have shown impressive performance on tasks within their training distribution, but often struggle with novel problems requiring complex reasoning. We investigate the effectiveness of test-time training (TTT) -- updating model parameters temporarily during inference using a loss derived from input data -- as a mechanism for improving models' reasoning capabilities, using the Abstraction and Reasoning Corpus (ARC) as a benchmark. Through systematic experimentation, we identify three crucial components for successful TTT: (1) initial finetuning on similar tasks (2) auxiliary task format and augmentations (3) per-instance training. TTT significantly improves performance on ARC tasks, achieving up to 6x improvement in accuracy compared to base fine-tuned models; applying TTT to an 8B-parameter language model, we achieve 53% accuracy on the ARC's public validation set, improving the state-of-the-art by nearly 25% for public and purely neural approaches. By ensembling our method with recent program generation approaches, we get SoTA public validation accuracy of 61.9%, matching the average human score. Our findings suggest that explicit symbolic search is not the only path to improved abstract reasoning in neural language models; additional test-time applied to continued training on few-shot examples can also be extremely effective.
Training-Free Activation Sparsity in Large Language Models
Aug 26, 2024Activation sparsity can enable practical inference speedups in large language models (LLMs) by reducing the compute and memory-movement required for matrix multiplications during the forward pass. However, existing methods face limitations that inhibit widespread adoption. Some approaches are tailored towards older models with ReLU-based sparsity, while others require extensive continued pre-training on up to hundreds of billions of tokens. This paper describes TEAL, a simple training-free method that applies magnitude-based activation sparsity to hidden states throughout the entire model. TEAL achieves 40-50% model-wide sparsity with minimal performance degradation across Llama-2, Llama-3, and Mistral families, with sizes varying from 7B to 70B. We improve existing sparse kernels and demonstrate wall-clock decoding speed-ups of up to 1.53$\times$ and 1.8$\times$ at 40% and 50% model-wide sparsity. TEAL is compatible with weight quantization, enabling further efficiency gains.