 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Nov 13, 2025Recent progress in large language models (LLMs) has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
PrefPalette: Personalized Preference Modeling with Latent Attributes
Jul 17, 2025



Personalizing AI systems requires understanding not just what users prefer, but the reasons that underlie those preferences - yet current preference models typically treat human judgment as a black box. We introduce PrefPalette, a framework that decomposes preferences into attribute dimensions and tailors its preference prediction to distinct social community values in a human-interpretable manner. PrefPalette operationalizes a cognitive science principle known as multi-attribute decision making in two ways: (1) a scalable counterfactual attribute synthesis step that involves generating synthetic training data to isolate for individual attribute effects (e.g., formality, humor, cultural values), and (2) attention-based preference modeling that learns how different social communities dynamically weight these attributes. This approach moves beyond aggregate preference modeling to capture the diverse evaluation frameworks that drive human judgment. When evaluated on 45 social communities from the online platform Reddit, PrefPalette outperforms GPT-4o by 46.6% in average prediction accuracy. Beyond raw predictive improvements, PrefPalette also shed light on intuitive, community-specific profiles: scholarly communities prioritize verbosity and stimulation, conflict-oriented communities value sarcasm and directness, and support-based communities emphasize empathy. By modeling the attribute-mediated structure of human judgment, PrefPalette delivers both superior preference modeling and transparent, interpretable insights, and serves as a first step toward more trustworthy, value-aware personalized applications.
On the Duality between Gradient Transformations and Adapters
Feb 19, 2025We study memory-efficient optimization of neural networks with linear gradient transformations, where the gradients are linearly mapped to a lower dimensional space than the full parameter space, thus saving memory required for gradient accumulation and optimizer state persistence. The model parameters are updated by first performing an optimization step in the lower dimensional space and then going back into the original parameter space via the linear map's transpose. We show that optimizing the model in this transformed space is equivalent to reparameterizing the original model through a linear adapter that additively modifies the model parameters, and then only optimizing the adapter's parameters. When the transformation is Kronecker-factored, this establishes an equivalence between GaLore and one-sided LoRA. We show that this duality between gradient transformations and adapter-based reparameterizations unifies existing approaches to memory-efficient training and suggests new techniques for improving training efficiency and memory use.
When One LLM Drools, Multi-LLM Collaboration Rules
Feb 06, 2025This position paper argues that in many realistic (i.e., complex, contextualized, subjective) scenarios, one LLM is not enough to produce a reliable output. We challenge the status quo of relying solely on a single general-purpose LLM and argue for multi-LLM collaboration to better represent the extensive diversity of data, skills, and people. We first posit that a single LLM underrepresents real-world data distributions, heterogeneous skills, and pluralistic populations, and that such representation gaps cannot be trivially patched by further training a single LLM. We then organize existing multi-LLM collaboration methods into a hierarchy, based on the level of access and information exchange, ranging from API-level, text-level, logit-level, to weight-level collaboration. Based on these methods, we highlight how multi-LLM collaboration addresses challenges that a single LLM struggles with, such as reliability, democratization, and pluralism. Finally, we identify the limitations of existing multi-LLM methods and motivate future work. We envision multi-LLM collaboration as an essential path toward compositional intelligence and collaborative AI development.
Theoretical Analysis of Weak-to-Strong Generalization
May 25, 2024Strong student models can learn from weaker teachers: when trained on the predictions of a weaker model, a strong pretrained student can learn to correct the weak model's errors and generalize to examples where the teacher is not confident, even when these examples are excluded from training. This enables learning from cheap, incomplete, and possibly incorrect label information, such as coarse logical rules or the generations of a language model. We show that existing weak supervision theory fails to account for both of these effects, which we call pseudolabel correction and coverage expansion, respectively. We give a new bound based on expansion properties of the data distribution and student hypothesis class that directly accounts for pseudolabel correction and coverage expansion. Our bounds capture the intuition that weak-to-strong generalization occurs when the strong model is unable to fit the mistakes of the weak teacher without incurring additional error. We show that these expansion properties can be checked from finite data and give empirical evidence that they hold in practice.
Learning to Decode Collaboratively with Multiple Language Models
Mar 06, 2024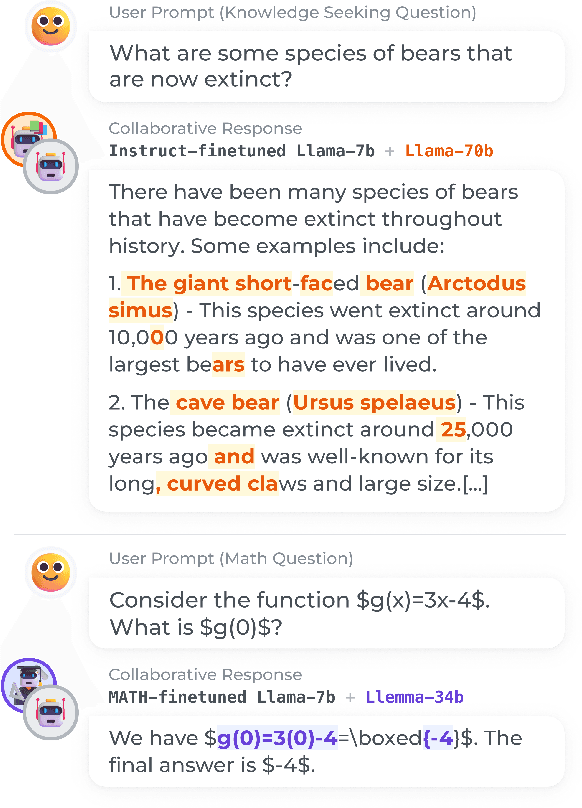
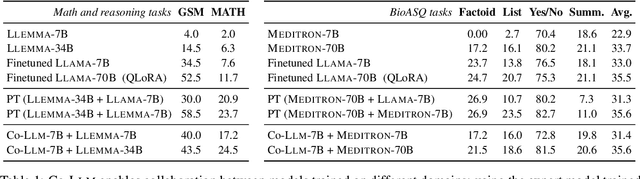


We propose a method to teach multiple large language models (LLM) to collaborate by interleaving their generations at the token level. We model the decision of which LLM generates the next token as a latent variable. By optimizing the marginal likelihood of a training set under our latent variable model, the base LLM automatically learns when to generate itself and when to call on one of the ``assistant'' language models to generate, all without direct supervision. Token-level collaboration during decoding allows for a fusion of each model's expertise in a manner tailored to the specific task at hand. Our collaborative decoding is especially useful in cross-domain settings where a generalist base LLM learns to invoke domain expert models. On instruction-following, domain-specific QA, and reasoning tasks, we show that the performance of the joint system exceeds that of the individual models. Through qualitative analysis of the learned latent decisions, we show models trained with our method exhibit several interesting collaboration patterns, e.g., template-filling. Our code is available at https://github.com/clinicalml/co-llm.
Who Should Predict? Exact Algorithms For Learning to Defer to Humans
Jan 15, 2023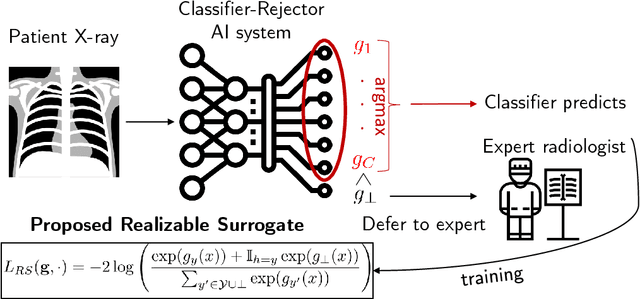

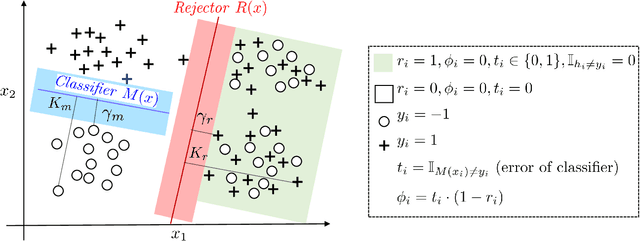
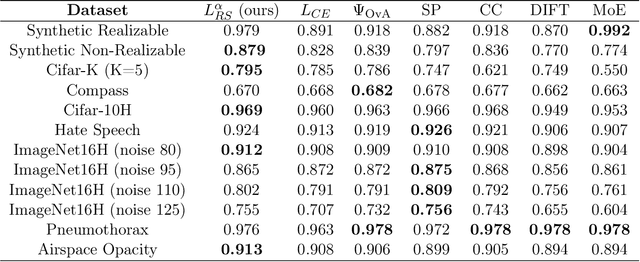
Automated AI classifiers should be able to defer the prediction to a human decision maker to ensure more accurate predictions. In this work, we jointly train a classifier with a rejector, which decides on each data point whether the classifier or the human should predict. We show that prior approaches can fail to find a human-AI system with low misclassification error even when there exists a linear classifier and rejector that have zero error (the realizable setting). We prove that obtaining a linear pair with low error is NP-hard even when the problem is realizable. To complement this negative result, we give a mixed-integer-linear-programming (MILP) formulation that can optimally solve the problem in the linear setting. However, the MILP only scales to moderately-sized problems. Therefore, we provide a novel surrogate loss function that is realizable-consistent and performs well empirically. We test our approaches on a comprehensive set of datasets and compare to a wide range of baselines.
TabLLM: Few-shot Classification of Tabular Data with Large Language Models
Oct 19, 2022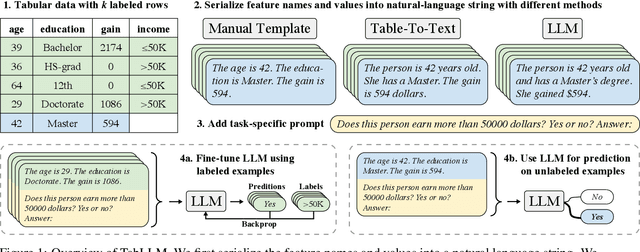
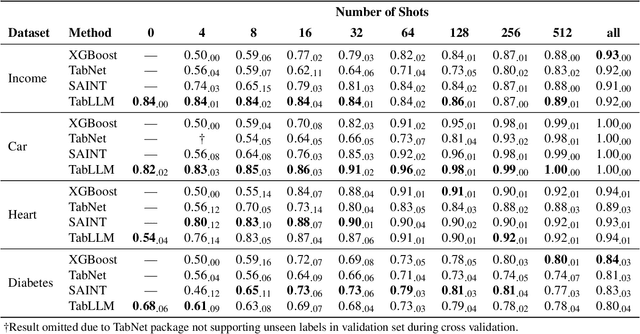
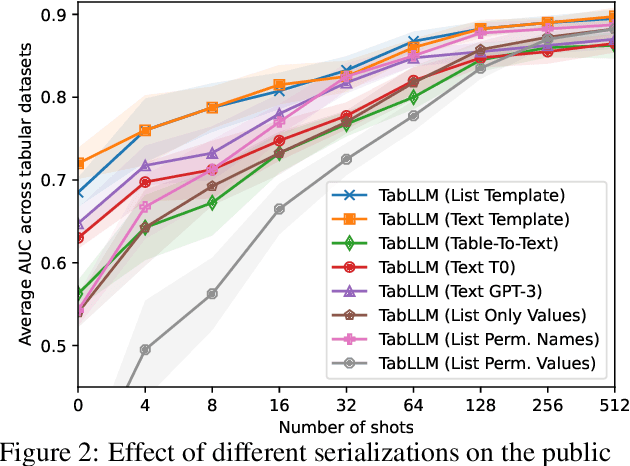
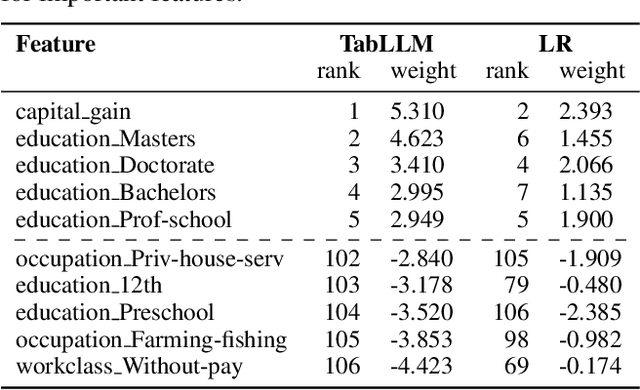
We study the application of large language models to zero-shot and few-shot classification of tabular data. We prompt the large language model with a serialization of the tabular data to a natural-language string, together with a short description of the classification problem. In the few-shot setting, we fine-tune the large language model using some labeled examples. We evaluate several serialization methods including templates, table-to-text models, and large language models. Despite its simplicity, we find that this technique outperforms prior deep-learning-based tabular classification methods on several benchmark datasets. In most cases, even zero-shot classification obtains non-trivial performance, illustrating the method's ability to exploit prior knowledge encoded in large language models. Unlike many deep learning methods for tabular datasets, this approach is also competitive with strong traditional baselines like gradient-boosted trees, especially in the very-few-shot setting.
Training Subset Selection for Weak Supervision
Jun 06, 2022
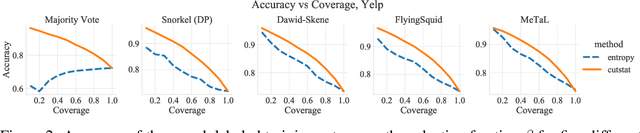

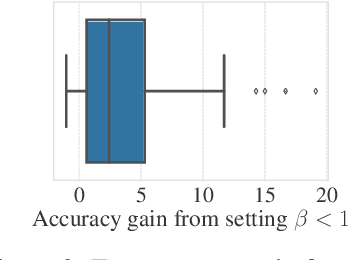
Existing weak supervision approaches use all the data covered by weak signals to train a classifier. We show both theoretically and empirically that this is not always optimal. Intuitively, there is a tradeoff between the amount of weakly-labeled data and the precision of the weak labels. We explore this tradeoff by combining pretrained data representations with the cut statistic (Muhlenbach et al., 2004) to select (hopefully) high-quality subsets of the weakly-labeled training data. Subset selection applies to any label model and classifier and is very simple to plug in to existing weak supervision pipelines, requiring just a few lines of code. We show our subset selection method improves the performance of weak supervision for a wide range of label models, classifiers, and datasets. Using less weakly-labeled data improves the accuracy of weak supervision pipelines by up to 19% (absolute) on benchmark tasks.
Large Language Models are Zero-Shot Clinical Information Extractors
May 25, 2022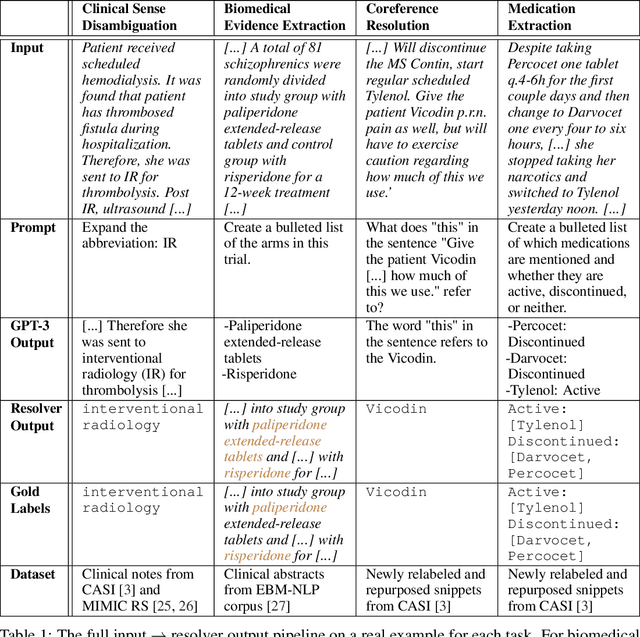


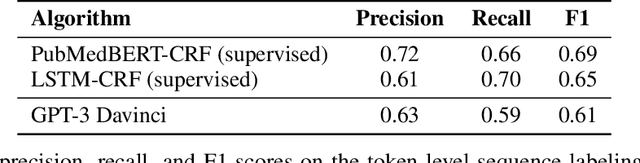
We show that large language models, such as GPT-3, perform well at zero-shot information extraction from clinical text despite not being trained specifically for the clinical domain. We present several examples showing how to use these models as tools for the diverse tasks of (i) concept disambiguation, (ii) evidence extraction, (iii) coreference resolution, and (iv) concept extraction, all on clinical text. The key to good performance is the use of simple task-specific programs that map from the language model outputs to the label space of the task. We refer to these programs as resolvers, a generalization of the verbalizer, which defines a mapping between output tokens and a discrete label space. We show in our examples that good resolvers share common components (e.g., "safety checks" that ensure the language model outputs faithfully match the input data), and that the common patterns across tasks make resolvers lightweight and easy to create. To better evaluate these systems, we also introduce two new datasets for benchmarking zero-shot clinical information extraction based on manual relabeling of the CASI dataset (Moon et al., 2014) with labels for new tasks. On the clinical extraction tasks we studied, the GPT-3 + resolver systems significantly outperform existing zero- and few-shot baselines.