 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClifford Kolmogorov-Arnold Networks
Feb 05, 2026We introduce Clifford Kolmogorov-Arnold Network (ClKAN), a flexible and efficient architecture for function approximation in arbitrary Clifford algebra spaces. We propose the use of Randomized Quasi Monte Carlo grid generation as a solution to the exponential scaling associated with higher dimensional algebras. Our ClKAN also introduces new batch normalization strategies to deal with variable domain input. ClKAN finds application in scientific discovery and engineering, and is validated in synthetic and physics inspired tasks.
SNAP: A Self-Consistent Agreement Principle with Application to Robust Computation
Feb 02, 2026We introduce SNAP (Self-coNsistent Agreement Principle), a self-supervised framework for robust computation based on mutual agreement. Based on an Agreement-Reliability Hypothesis SNAP assigns weights that quantify agreement, emphasizing trustworthy items and downweighting outliers without supervision or prior knowledge. A key result is the Exponential Suppression of Outlier Weights, ensuring that outliers contribute negligibly to computations, even in high-dimensional settings. We study properties of SNAP weighting scheme and show its practical benefits on vector averaging and subspace estimation. Particularly, we demonstrate that non-iterative SNAP outperforms the iterative Weiszfeld algorithm and two variants of multivariate median of means. SNAP thus provides a flexible, easy-to-use, broadly applicable approach to robust computation.
Joint Learning of Unsupervised Multi-view Feature and Instance Co-selection with Cross-view Imputation
Dec 17, 2025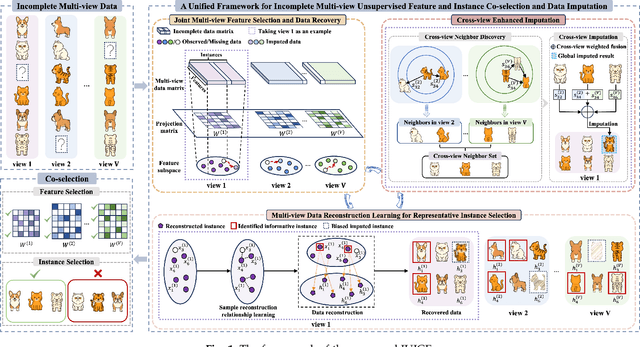
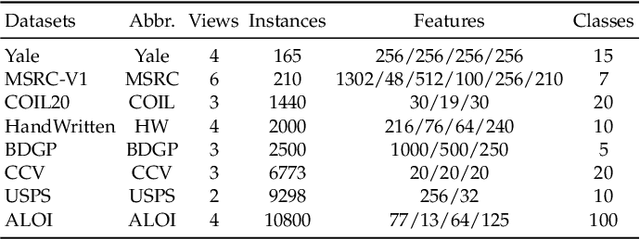
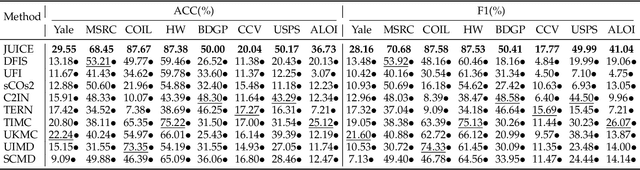
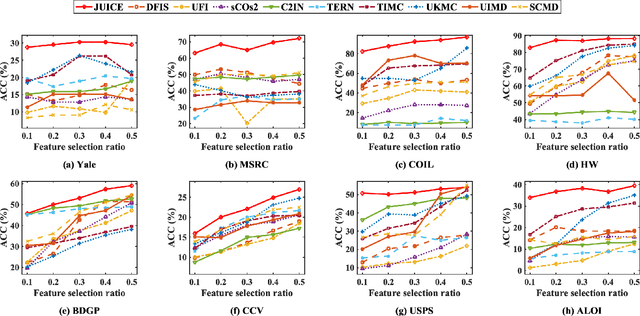
Feature and instance co-selection, which aims to reduce both feature dimensionality and sample size by identifying the most informative features and instances, has attracted considerable attention in recent years. However, when dealing with unlabeled incomplete multi-view data, where some samples are missing in certain views, existing methods typically first impute the missing data and then concatenate all views into a single dataset for subsequent co-selection. Such a strategy treats co-selection and missing data imputation as two independent processes, overlooking potential interactions between them. The inter-sample relationships gleaned from co-selection can aid imputation, which in turn enhances co-selection performance. Additionally, simply merging multi-view data fails to capture the complementary information among views, ultimately limiting co-selection effectiveness. To address these issues, we propose a novel co-selection method, termed Joint learning of Unsupervised multI-view feature and instance Co-selection with cross-viEw imputation (JUICE). JUICE first reconstructs incomplete multi-view data using available observations, bringing missing data recovery and feature and instance co-selection together in a unified framework. Then, JUICE leverages cross-view neighborhood information to learn inter-sample relationships and further refine the imputation of missing values during reconstruction. This enables the selection of more representative features and instances. Extensive experiments demonstrate that JUICE outperforms state-of-the-art methods.
Cross-view Joint Learning for Mixed-Missing Multi-view Unsupervised Feature Selection
Nov 15, 2025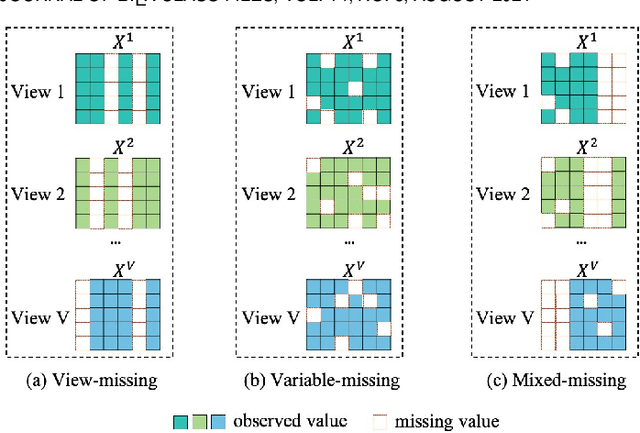
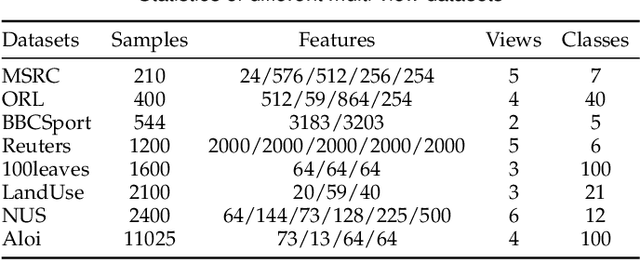
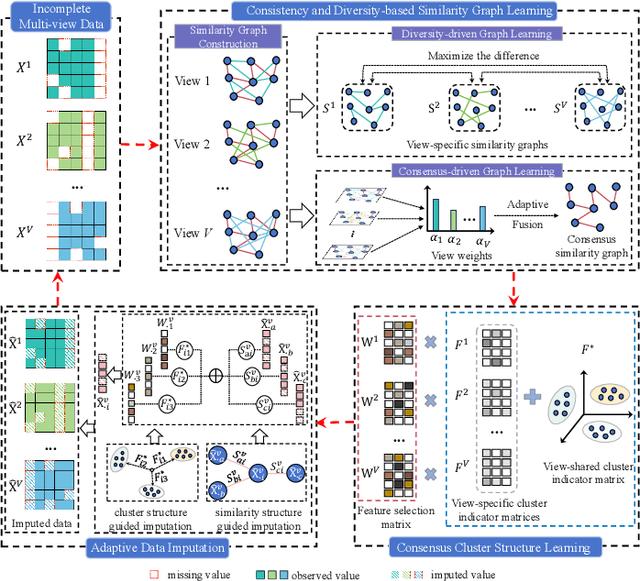
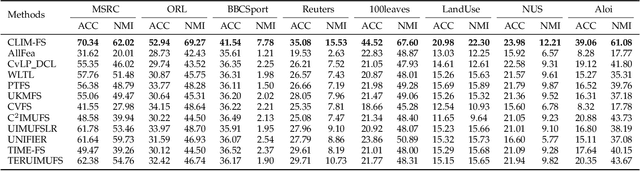
Incomplete multi-view unsupervised feature selection (IMUFS), which aims to identify representative features from unlabeled multi-view data containing missing values, has received growing attention in recent years. Despite their promising performance, existing methods face three key challenges: 1) by focusing solely on the view-missing problem, they are not well-suited to the more prevalent mixed-missing scenario in practice, where some samples lack entire views or only partial features within views; 2) insufficient utilization of consistency and diversity across views limits the effectiveness of feature selection; and 3) the lack of theoretical analysis makes it unclear how feature selection and data imputation interact during the joint learning process. Being aware of these, we propose CLIM-FS, a novel IMUFS method designed to address the mixed-missing problem. Specifically, we integrate the imputation of both missing views and variables into a feature selection model based on nonnegative orthogonal matrix factorization, enabling the joint learning of feature selection and adaptive data imputation. Furthermore, we fully leverage consensus cluster structure and cross-view local geometrical structure to enhance the synergistic learning process. We also provide a theoretical analysis to clarify the underlying collaborative mechanism of CLIM-FS. Experimental results on eight real-world multi-view datasets demonstrate that CLIM-FS outperforms state-of-the-art methods.
Thermal Detection of People with Mobility Restrictions for Barrier Reduction at Traffic Lights Controlled Intersections
May 14, 2025Rapid advances in deep learning for computer vision have driven the adoption of RGB camera-based adaptive traffic light systems to improve traffic safety and pedestrian comfort. However, these systems often overlook the needs of people with mobility restrictions. Moreover, the use of RGB cameras presents significant challenges, including limited detection performance under adverse weather or low-visibility conditions, as well as heightened privacy concerns. To address these issues, we propose a fully automated, thermal detector-based traffic light system that dynamically adjusts signal durations for individuals with walking impairments or mobility burden and triggers the auditory signal for visually impaired individuals, thereby advancing towards barrier-free intersection for all users. To this end, we build the thermal dataset for people with mobility restrictions (TD4PWMR), designed to capture diverse pedestrian scenarios, particularly focusing on individuals with mobility aids or mobility burden under varying environmental conditions, such as different lighting, weather, and crowded urban settings. While thermal imaging offers advantages in terms of privacy and robustness to adverse conditions, it also introduces inherent hurdles for object detection due to its lack of color and fine texture details and generally lower resolution of thermal images. To overcome these limitations, we develop YOLO-Thermal, a novel variant of the YOLO architecture that integrates advanced feature extraction and attention mechanisms for enhanced detection accuracy and robustness in thermal imaging. Experiments demonstrate that the proposed thermal detector outperforms existing detectors, while the proposed traffic light system effectively enhances barrier-free intersection. The source codes and dataset are available at https://github.com/leon2014dresden/YOLO-THERMAL.
Robustness of Generalized Median Computation for Consensus Learning in Arbitrary Spaces
Mar 07, 2025
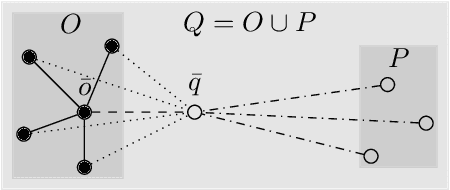

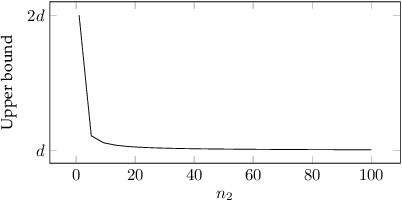
Robustness in terms of outliers is an important topic and has been formally studied for a variety of problems in machine learning and computer vision. Generalized median computation is a special instance of consensus learning and a common approach to finding prototypes. Related research can be found in numerous problem domains with a broad range of applications. So far, however, robustness of generalized median has only been studied in a few specific spaces. To our knowledge, there is no robustness characterization in a general setting, i.e. for arbitrary spaces. We address this open issue in our work. The breakdown point >=0.5 is proved for generalized median with metric distance functions in general. We also study the detailed behavior in case of outliers from different perspectives. In addition, we present robustness results for weighted generalized median computation and non-metric distance functions. Given the importance of robustness, our work contributes to closing a gap in the literature. The presented results have general impact and applicability, e.g. providing deeper understanding of generalized median computation and practical guidance to avoid non-robust computation.
CVKAN: Complex-Valued Kolmogorov-Arnold Networks
Feb 04, 2025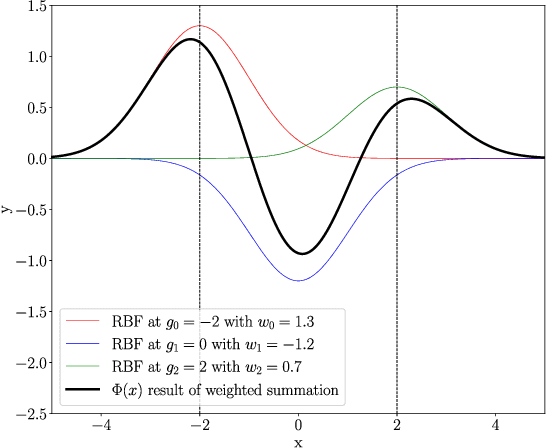
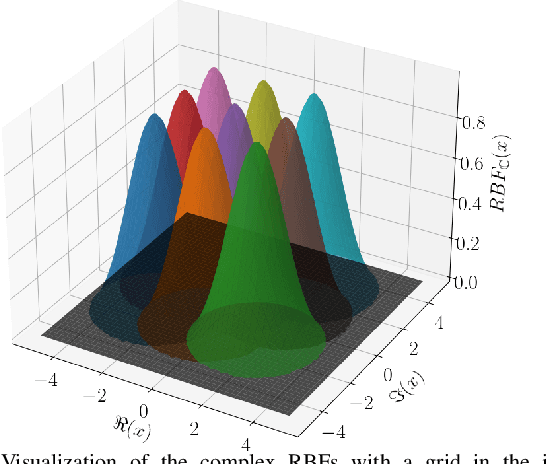
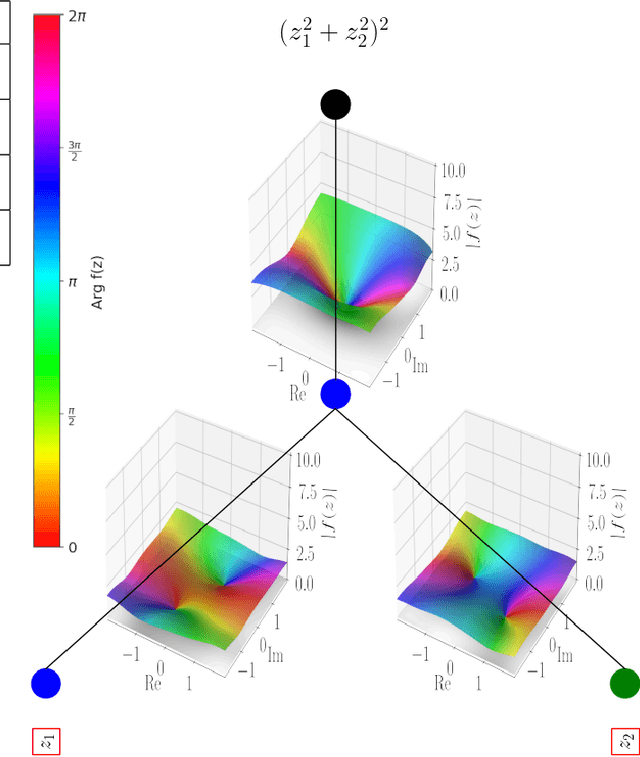
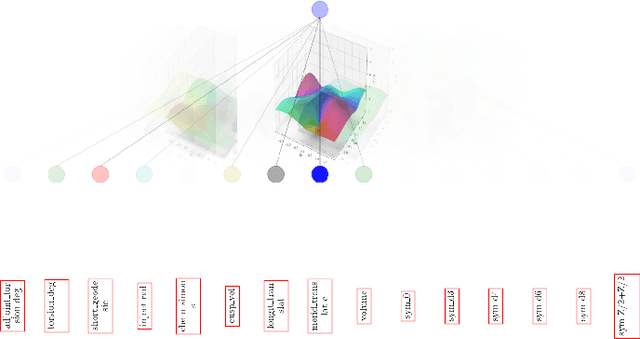
In this work we propose CKAN, a complex-valued KAN, to join the intrinsic interpretability of KANs and the advantages of Complex-Valued Neural Networks (CVNNs). We show how to transfer a KAN and the necessary associated mechanisms into the complex domain. To confirm that CKAN meets expectations we conduct experiments on symbolic complex-valued function fitting and physically meaningful formulae as well as on a more realistic dataset from knot theory. Our proposed CKAN is more stable and performs on par or better than real-valued KANs while requiring less parameters and a shallower network architecture, making it more explainable.
Single Image Estimation of Cell Migration Direction by Deep Circular Regression
Jun 27, 2024



In this paper we study the problem of estimating the migration direction of cells based on a single image. To the best of our knowledge, there is only one related work that uses a classification CNN for four classes (quadrants). This approach does not allow detailed directional resolution. We solve the single image estimation problem using deep circular regression with special attention to cycle-sensitive methods. On two databases we achieve an average accuracy of $\sim$17 degrees, which is a significant improvement over the previous work.
DeepCSHAP: Utilizing Shapley Values to Explain Deep Complex-Valued Neural Networks
Mar 13, 2024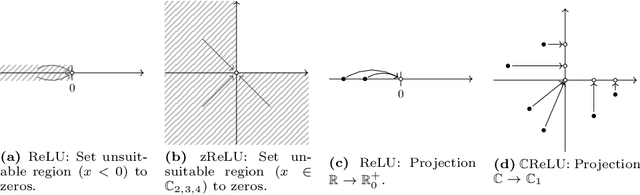


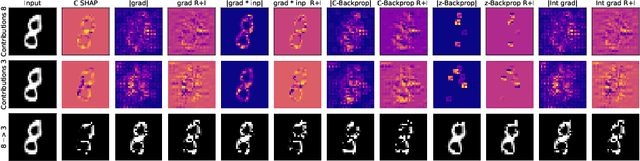
Deep Neural Networks are widely used in academy as well as corporate and public applications, including safety critical applications such as health care and autonomous driving. The ability to explain their output is critical for safety reasons as well as acceptance among applicants. A multitude of methods have been proposed to explain real-valued neural networks. Recently, complex-valued neural networks have emerged as a new class of neural networks dealing with complex-valued input data without the necessity of projecting them onto $\mathbb{R}^2$. This brings up the need to develop explanation algorithms for this kind of neural networks. In this paper we provide these developments. While we focus on adapting the widely used DeepSHAP algorithm to the complex domain, we also present versions of four gradient based explanation methods suitable for use in complex-valued neural networks. We evaluate the explanation quality of all presented algorithms and provide all of them as an open source library adaptable to most recent complex-valued neural network architectures.
A Data-Centric Approach To Generate Faithful and High Quality Patient Summaries with Large Language Models
Feb 23, 2024



Patients often face difficulties in understanding their hospitalizations, while healthcare workers have limited resources to provide explanations. In this work, we investigate the potential of large language models to generate patient summaries based on doctors' notes and study the effect of training data on the faithfulness and quality of the generated summaries. To this end, we develop a rigorous labeling protocol for hallucinations, and have two medical experts annotate 100 real-world summaries and 100 generated summaries. We show that fine-tuning on hallucination-free data effectively reduces hallucinations from 2.60 to 1.55 per summary for Llama 2, while preserving relevant information. Although the effect is still present, it is much smaller for GPT-4 when prompted with five examples (0.70 to 0.40). We also conduct a qualitative evaluation using hallucination-free and improved training data. GPT-4 shows very good results even in the zero-shot setting. We find that common quantitative metrics do not correlate well with faithfulness and quality. Finally, we test GPT-4 for automatic hallucination detection, which yields promising results.