 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClifford Kolmogorov-Arnold Networks
Feb 05, 2026We introduce Clifford Kolmogorov-Arnold Network (ClKAN), a flexible and efficient architecture for function approximation in arbitrary Clifford algebra spaces. We propose the use of Randomized Quasi Monte Carlo grid generation as a solution to the exponential scaling associated with higher dimensional algebras. Our ClKAN also introduces new batch normalization strategies to deal with variable domain input. ClKAN finds application in scientific discovery and engineering, and is validated in synthetic and physics inspired tasks.
CVKAN: Complex-Valued Kolmogorov-Arnold Networks
Feb 04, 2025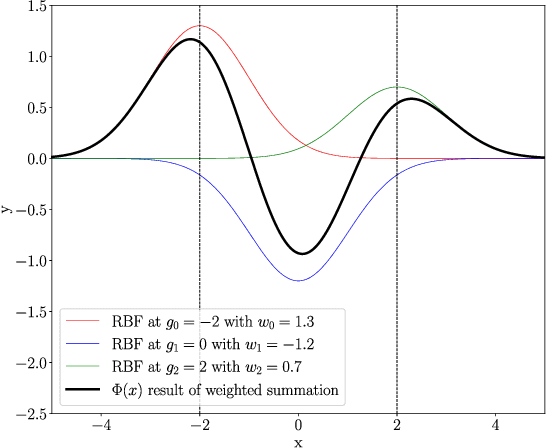
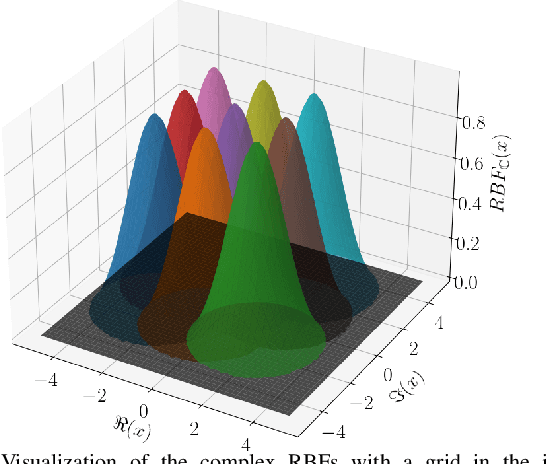
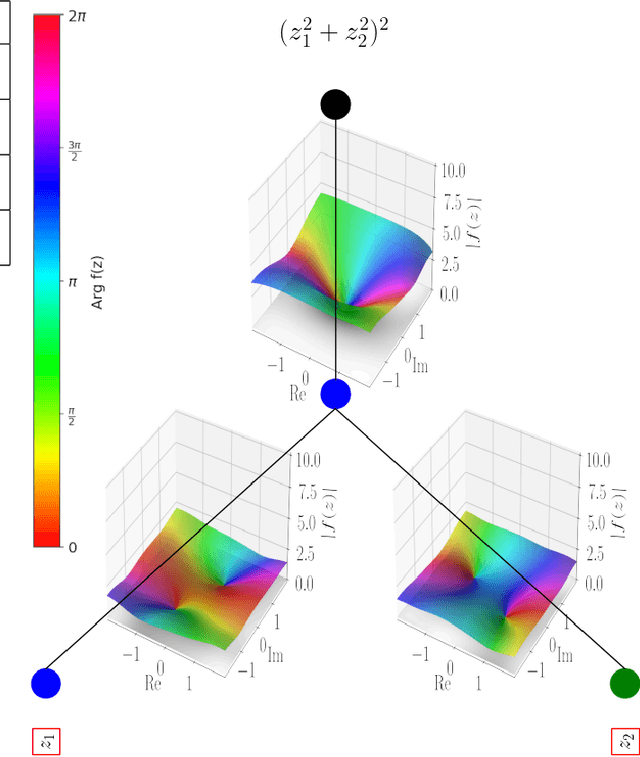
In this work we propose CKAN, a complex-valued KAN, to join the intrinsic interpretability of KANs and the advantages of Complex-Valued Neural Networks (CVNNs). We show how to transfer a KAN and the necessary associated mechanisms into the complex domain. To confirm that CKAN meets expectations we conduct experiments on symbolic complex-valued function fitting and physically meaningful formulae as well as on a more realistic dataset from knot theory. Our proposed CKAN is more stable and performs on par or better than real-valued KANs while requiring less parameters and a shallower network architecture, making it more explainable.
Arithmetics-Based Decomposition of Numeral Words -- Arithmetic Conditions give the Unpacking Strategy
Dec 14, 2023In this paper we present a novel numeral decomposer that is designed to revert Hurford's Packing Strategy. The Packing Strategy is a model on how numeral words are formed out of smaller numeral words by recursion. The decomposer does not simply check decimal digits but it also works for numerals formed on base 20 or any other base or even combinations of different bases. All assumptions that we use are justified with Hurford's Packing Strategy. The decomposer reads through the numeral. When it finds a sub-numeral, it checks arithmetic conditions to decide whether or not to unpack the sub-numeral. The goal is to unpack those numerals that can sensibly be substituted by similar numerals. E.g., in 'twenty-seven thousand and two hundred and six' it should unpack 'twenty-seven' and 'two hundred and six', as those could each be sensibly replaced by any numeral from 1 to 999. Our most used condition is: If S is a substitutable sub-numeral of a numeral N, then 2*value(S) < value(N). We have tested the decomposer on numeral systems in 254 different natural languages. We also developed a reinforcement learning algorithm based on the decomposer. Both algorithms' code and the results are open source on GitHub.
How to Do Machine Learning with Small Data? -- A Review from an Industrial Perspective
Nov 13, 2023



Artificial intelligence experienced a technological breakthrough in science, industry, and everyday life in the recent few decades. The advancements can be credited to the ever-increasing availability and miniaturization of computational resources that resulted in exponential data growth. However, because of the insufficient amount of data in some cases, employing machine learning in solving complex tasks is not straightforward or even possible. As a result, machine learning with small data experiences rising importance in data science and application in several fields. The authors focus on interpreting the general term of "small data" and their engineering and industrial application role. They give a brief overview of the most important industrial applications of machine learning and small data. Small data is defined in terms of various characteristics compared to big data, and a machine learning formalism was introduced. Five critical challenges of machine learning with small data in industrial applications are presented: unlabeled data, imbalanced data, missing data, insufficient data, and rare events. Based on those definitions, an overview of the considerations in domain representation and data acquisition is given along with a taxonomy of machine learning approaches in the context of small data.
Minimalist Grammar: Construction without Overgeneration
Nov 03, 2023In this paper we give instructions on how to write a minimalist grammar (MG). In order to present the instructions as an algorithm, we use a variant of context free grammars (CFG) as an input format. We can exclude overgeneration, if the CFG has no recursion, i.e. no non-terminal can (indirectly) derive to a right-hand side containing itself. The constructed MGs utilize licensors/-ees as a special way of exception handling. A CFG format for a derivation $A\_eats\_B\mapsto^* peter\_eats\_apples$, where $A$ and $B$ generate noun phrases, normally leads to overgeneration, e.\,g., $i\_eats\_apples$. In order to avoid overgeneration, a CFG would need many non-terminal symbols and rules, that mainly produce the same word, just to handle exceptions. In our MGs however, we can summarize CFG rules that produce the same word in one item and handle exceptions by a proper distribution of licensees/-ors. The difficulty with this technique is that in most generations the majority of licensees/-ors is not needed, but still has to be triggered somehow. We solve this problem with $\epsilon$-items called \emph{adapters}.
Reinforcement learning of minimalist grammars
Apr 30, 2020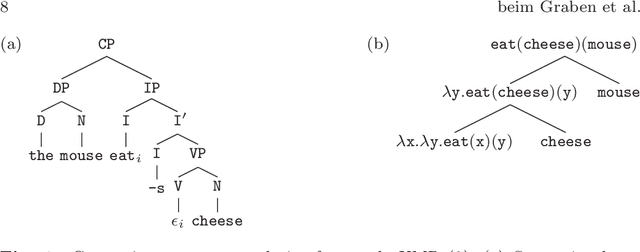
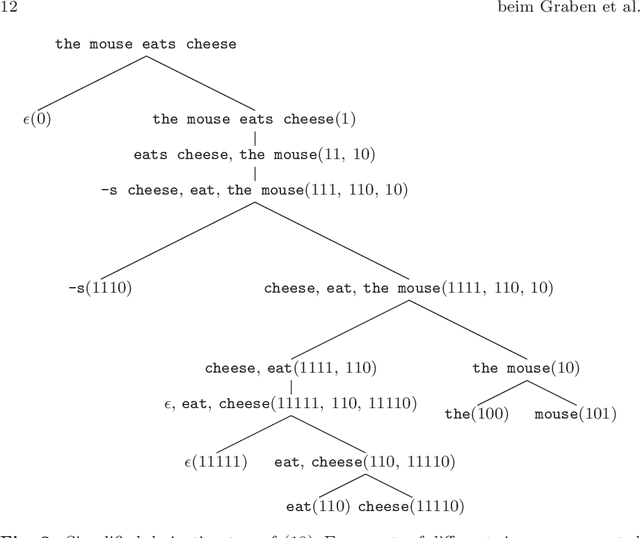
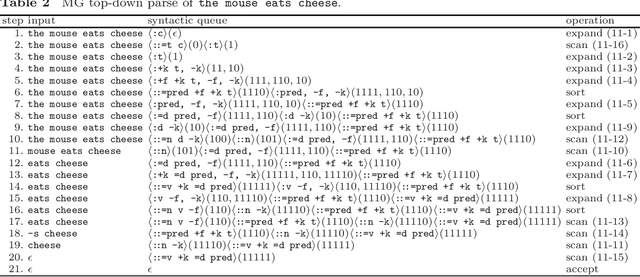

Speech-controlled user interfaces facilitate the operation of devices and household functions to laymen. State-of-the-art language technology scans the acoustically analyzed speech signal for relevant keywords that are subsequently inserted into semantic slots to interpret the user's intent. In order to develop proper cognitive information and communication technologies, simple slot-filling should be replaced by utterance meaning transducers (UMT) that are based on semantic parsers and a mental lexicon, comprising syntactic, phonetic and semantic features of the language under consideration. This lexicon must be acquired by a cognitive agent during interaction with its users. We outline a reinforcement learning algorithm for the acquisition of syntax and semantics of English utterances, based on minimalist grammar (MG), a recent computational implementation of generative linguistics. English declarative sentences are presented to the agent by a teacher in form of utterance meaning pairs (UMP) where the meanings are encoded as formulas of predicate logic. Since MG codifies universal linguistic competence through inference rules, thereby separating innate linguistic knowledge from the contingently acquired lexicon, our approach unifies generative grammar and reinforcement learning, hence potentially resolving the still pending Chomsky-Skinner controversy.
Vector symbolic architectures for context-free grammars
Mar 11, 2020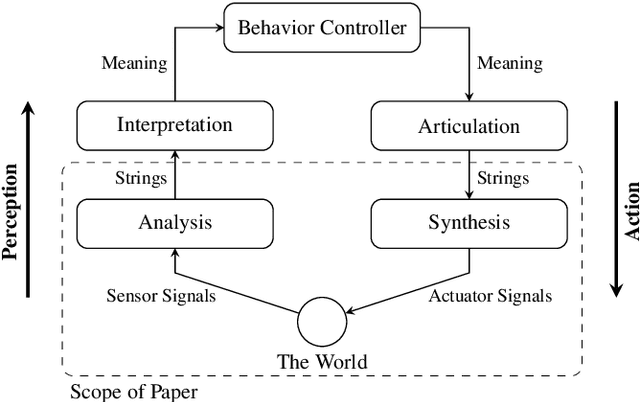
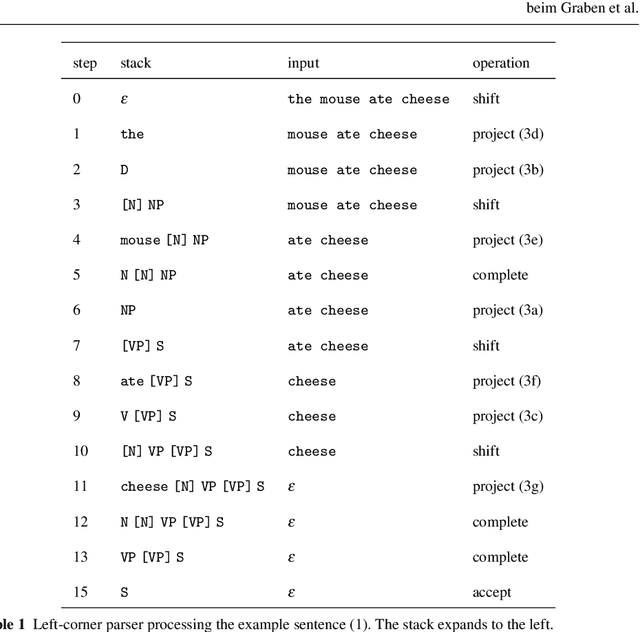
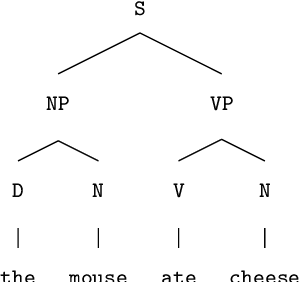

Background / introduction. Vector symbolic architectures (VSA) are a viable approach for the hyperdimensional representation of symbolic data, such as documents, syntactic structures, or semantic frames. Methods. We present a rigorous mathematical framework for the representation of phrase structure trees and parse-trees of context-free grammars (CFG) in Fock space, i.e. infinite-dimensional Hilbert space as being used in quantum field theory. We define a novel normal form for CFG by means of term algebras. Using a recently developed software toolbox, called FockBox, we construct Fock space representations for the trees built up by a CFG left-corner (LC) parser. Results. We prove a universal representation theorem for CFG term algebras in Fock space and illustrate our findings through a low-dimensional principal component projection of the LC parser states. Conclusions. Our approach could leverage the development of VSA for explainable artificial intelligence (XAI) by means of hyperdimensional deep neural computation. It could be of significance for the improvement of cognitive user interfaces and other applications of VSA in machine learning.
Reinforcement Learning of Minimalist Numeral Grammars
Jun 11, 2019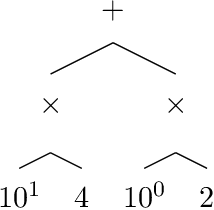
Speech-controlled user interfaces facilitate the operation of devices and household functions to laymen. State-of-the-art language technology scans the acoustically analyzed speech signal for relevant keywords that are subsequently inserted into semantic slots to interpret the user's intent. In order to develop proper cognitive information and communication technologies, simple slot-filling should be replaced by utterance meaning transducers (UMT) that are based on semantic parsers and a \emph{mental lexicon}, comprising syntactic, phonetic and semantic features of the language under consideration. This lexicon must be acquired by a cognitive agent during interaction with its users. We outline a reinforcement learning algorithm for the acquisition of the syntactic morphology and arithmetic semantics of English numerals, based on minimalist grammar (MG), a recent computational implementation of generative linguistics. Number words are presented to the agent by a teacher in form of utterance meaning pairs (UMP) where the meanings are encoded as arithmetic terms from a suitable term algebra. Since MG encodes universal linguistic competence through inference rules, thereby separating innate linguistic knowledge from the contingently acquired lexicon, our approach unifies generative grammar and reinforcement learning, hence potentially resolving the still pending Chomsky-Skinner controversy.