 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Reward Was in Your Data All Along: Correcting Flow Matching with Discriminator-Guided RL
Jun 17, 2026Score- and flow-matching models often rely on preference-based reinforcement learning for two purposes: aligning with subjective preferences and, surprisingly, recovering properties such as visual realism and coherent object structure that matching-based training is intended to learn from the data itself. We argue that this reflects a structural mismatch. Matching losses measure $\ell_2$ regression error on the velocity or score field under training-time marginals, a proxy poorly aligned with the visual and semantic properties that determine sample quality at inference. Given a reward aligned with these properties, RL sidesteps the mismatch by evaluating the model on its own samples and following the reward landscape directly. The challenge is to obtain such a reward without relying on human preferences, which are expensive and conflate data realism with annotator inclinations. We propose Discriminator-Guided RL (DRL). DRL trains a discriminator to separate data from base-model samples in a pretrained representation space and uses its logit as the reward in KL-regularized RL. The pretrained space restricts the discriminator to perceptually meaningful directions, and the logit estimates the log-likelihood ratio between data and model, which is the optimal reward for targeting the data distribution. Across SiT, JiT, REPA, and RAE, DRL reduces guidance-free FID (e.g., $9.38 \to 2.62$ on SiT) and semantic-space FD (e.g., $88.2 \to 19.3$ on DINOv3 for SiT), with consistent gains across all backbones, and improves human-preference rewards without training on them. It also yields a better Pareto frontier between preference reward and image fidelity under subsequent preference-based post-training, increasing alignment while reducing low-level artifacts such as oversaturation and excessive brightness.
Inference-time Physics Alignment of Video Generative Models with Latent World Models
Jan 15, 2026State-of-the-art video generative models produce promising visual content yet often violate basic physics principles, limiting their utility. While some attribute this deficiency to insufficient physics understanding from pre-training, we find that the shortfall in physics plausibility also stems from suboptimal inference strategies. We therefore introduce WMReward and treat improving physics plausibility of video generation as an inference-time alignment problem. In particular, we leverage the strong physics prior of a latent world model (here, VJEPA-2) as a reward to search and steer multiple candidate denoising trajectories, enabling scaling test-time compute for better generation performance. Empirically, our approach substantially improves physics plausibility across image-conditioned, multiframe-conditioned, and text-conditioned generation settings, with validation from human preference study. Notably, in the ICCV 2025 Perception Test PhysicsIQ Challenge, we achieve a final score of 62.64%, winning first place and outperforming the previous state of the art by 7.42%. Our work demonstrates the viability of using latent world models to improve physics plausibility of video generation, beyond this specific instantiation or parameterization.
Unified Text-Image Generation with Weakness-Targeted Post-Training
Jan 07, 2026Unified multimodal generation architectures that jointly produce text and images have recently emerged as a promising direction for text-to-image (T2I) synthesis. However, many existing systems rely on explicit modality switching, generating reasoning text before switching manually to image generation. This separate, sequential inference process limits cross-modal coupling and prohibits automatic multimodal generation. This work explores post-training to achieve fully unified text-image generation, where models autonomously transition from textual reasoning to visual synthesis within a single inference process. We examine the impact of joint text-image generation on T2I performance and the relative importance of each modality during post-training. We additionally explore different post-training data strategies, showing that a targeted dataset addressing specific limitations achieves superior results compared to broad image-caption corpora or benchmark-aligned data. Using offline, reward-weighted post-training with fully self-generated synthetic data, our approach enables improvements in multimodal image generation across four diverse T2I benchmarks, demonstrating the effectiveness of reward-weighting both modalities and strategically designed post-training data.
MADFormer: Mixed Autoregressive and Diffusion Transformers for Continuous Image Generation
Jun 09, 2025



Recent progress in multimodal generation has increasingly combined autoregressive (AR) and diffusion-based approaches, leveraging their complementary strengths: AR models capture long-range dependencies and produce fluent, context-aware outputs, while diffusion models operate in continuous latent spaces to refine high-fidelity visual details. However, existing hybrids often lack systematic guidance on how and why to allocate model capacity between these paradigms. In this work, we introduce MADFormer, a Mixed Autoregressive and Diffusion Transformer that serves as a testbed for analyzing AR-diffusion trade-offs. MADFormer partitions image generation into spatial blocks, using AR layers for one-pass global conditioning across blocks and diffusion layers for iterative local refinement within each block. Through controlled experiments on FFHQ-1024 and ImageNet, we identify two key insights: (1) block-wise partitioning significantly improves performance on high-resolution images, and (2) vertically mixing AR and diffusion layers yields better quality-efficiency balances--improving FID by up to 75% under constrained inference compute. Our findings offer practical design principles for future hybrid generative models.
FACTS&EVIDENCE: An Interactive Tool for Transparent Fine-Grained Factual Verification of Machine-Generated Text
Mar 19, 2025



With the widespread consumption of AI-generated content, there has been an increased focus on developing automated tools to verify the factual accuracy of such content. However, prior research and tools developed for fact verification treat it as a binary classification or a linear regression problem. Although this is a useful mechanism as part of automatic guardrails in systems, we argue that such tools lack transparency in the prediction reasoning and diversity in source evidence to provide a trustworthy user experience. We develop Facts&Evidence - an interactive and transparent tool for user-driven verification of complex text. The tool facilitates the intricate decision-making involved in fact-verification, presenting its users a breakdown of complex input texts to visualize the credibility of individual claims along with an explanation of model decisions and attribution to multiple, diverse evidence sources. Facts&Evidence aims to empower consumers of machine-generated text and give them agency to understand, verify, selectively trust and use such text.
When One LLM Drools, Multi-LLM Collaboration Rules
Feb 06, 2025This position paper argues that in many realistic (i.e., complex, contextualized, subjective) scenarios, one LLM is not enough to produce a reliable output. We challenge the status quo of relying solely on a single general-purpose LLM and argue for multi-LLM collaboration to better represent the extensive diversity of data, skills, and people. We first posit that a single LLM underrepresents real-world data distributions, heterogeneous skills, and pluralistic populations, and that such representation gaps cannot be trivially patched by further training a single LLM. We then organize existing multi-LLM collaboration methods into a hierarchy, based on the level of access and information exchange, ranging from API-level, text-level, logit-level, to weight-level collaboration. Based on these methods, we highlight how multi-LLM collaboration addresses challenges that a single LLM struggles with, such as reliability, democratization, and pluralism. Finally, we identify the limitations of existing multi-LLM methods and motivate future work. We envision multi-LLM collaboration as an essential path toward compositional intelligence and collaborative AI development.
LMFusion: Adapting Pretrained Language Models for Multimodal Generation
Dec 26, 2024



We present LMFusion, a framework for empowering pretrained text-only large language models (LLMs) with multimodal generative capabilities, enabling them to understand and generate both text and images in arbitrary sequences. LMFusion leverages existing Llama-3's weights for processing texts autoregressively while introducing additional and parallel transformer modules for processing images with diffusion. During training, the data from each modality is routed to its dedicated modules: modality-specific feedforward layers, query-key-value projections, and normalization layers process each modality independently, while the shared self-attention layers allow interactions across text and image features. By freezing the text-specific modules and only training the image-specific modules, LMFusion preserves the language capabilities of text-only LLMs while developing strong visual understanding and generation abilities. Compared to methods that pretrain multimodal generative models from scratch, our experiments demonstrate that, LMFusion improves image understanding by 20% and image generation by 3.6% using only 50% of the FLOPs while maintaining Llama-3's language capabilities. We also demonstrate that this framework can adapt existing vision-language models with multimodal generation ability. Overall, this framework not only leverages existing computational investments in text-only LLMs but also enables the parallel development of language and vision capabilities, presenting a promising direction for efficient multimodal model development.
LlamaFusion: Adapting Pretrained Language Models for Multimodal Generation
Dec 19, 2024We present LlamaFusion, a framework for empowering pretrained text-only large language models (LLMs) with multimodal generative capabilities, enabling them to understand and generate both text and images in arbitrary sequences. LlamaFusion leverages existing Llama-3's weights for processing texts autoregressively while introducing additional and parallel transformer modules for processing images with diffusion. During training, the data from each modality is routed to its dedicated modules: modality-specific feedforward layers, query-key-value projections, and normalization layers process each modality independently, while the shared self-attention layers allow interactions across text and image features. By freezing the text-specific modules and only training the image-specific modules, LlamaFusion preserves the language capabilities of text-only LLMs while developing strong visual understanding and generation abilities. Compared to methods that pretrain multimodal generative models from scratch, our experiments demonstrate that, LlamaFusion improves image understanding by 20% and image generation by 3.6% using only 50% of the FLOPs while maintaining Llama-3's language capabilities. We also demonstrate that this framework can adapt existing vision-language models with multimodal generation ability. Overall, this framework not only leverages existing computational investments in text-only LLMs but also enables the parallel development of language and vision capabilities, presenting a promising direction for efficient multimodal model development.
JPEG-LM: LLMs as Image Generators with Canonical Codec Representations
Aug 15, 2024Recent work in image and video generation has been adopting the autoregressive LLM architecture due to its generality and potentially easy integration into multi-modal systems. The crux of applying autoregressive training in language generation to visual generation is discretization -- representing continuous data like images and videos as discrete tokens. Common methods of discretizing images and videos include modeling raw pixel values, which are prohibitively lengthy, or vector quantization, which requires convoluted pre-hoc training. In this work, we propose to directly model images and videos as compressed files saved on computers via canonical codecs (e.g., JPEG, AVC/H.264). Using the default Llama architecture without any vision-specific modifications, we pretrain JPEG-LM from scratch to generate images (and AVC-LM to generate videos as a proof of concept), by directly outputting compressed file bytes in JPEG and AVC formats. Evaluation of image generation shows that this simple and straightforward approach is more effective than pixel-based modeling and sophisticated vector quantization baselines (on which our method yields a 31% reduction in FID). Our analysis shows that JPEG-LM has an especial advantage over vector quantization models in generating long-tail visual elements. Overall, we show that using canonical codec representations can help lower the barriers between language generation and visual generation, facilitating future research on multi-modal language/image/video LLMs.
Can LLM Graph Reasoning Generalize beyond Pattern Memorization?
Jun 23, 2024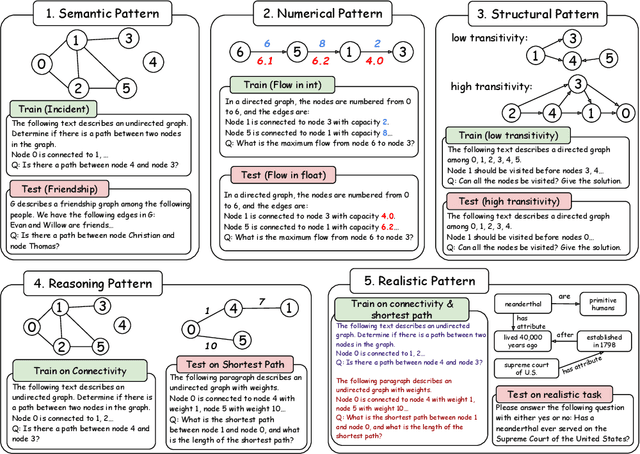
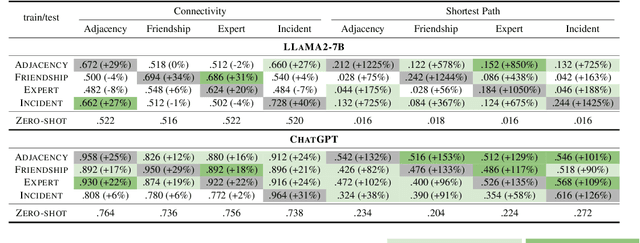
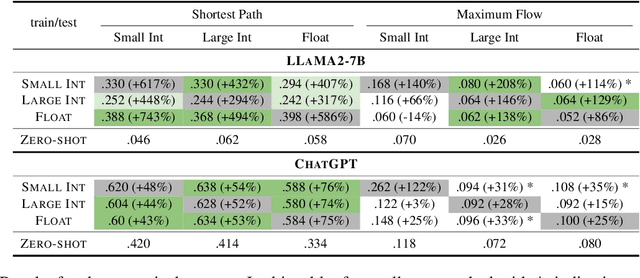
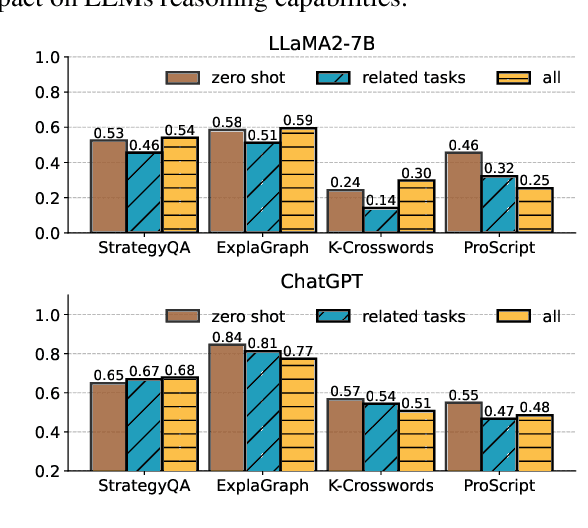
Large language models (LLMs) demonstrate great potential for problems with implicit graphical structures, while recent works seek to enhance the graph reasoning capabilities of LLMs through specialized instruction tuning. The resulting 'graph LLMs' are evaluated with in-distribution settings only, thus it remains underexplored whether LLMs are learning generalizable graph reasoning skills or merely memorizing patterns in the synthetic training data. To this end, we propose the NLGift benchmark, an evaluation suite of LLM graph reasoning generalization: whether LLMs could go beyond semantic, numeric, structural, reasoning patterns in the synthetic training data and improve utility on real-world graph-based tasks. Extensive experiments with two LLMs across four graph reasoning tasks demonstrate that while generalization on simple patterns (semantic, numeric) is somewhat satisfactory, LLMs struggle to generalize across reasoning and real-world patterns, casting doubt on the benefit of synthetic graph tuning for real-world tasks with underlying network structures. We explore three strategies to improve LLM graph reasoning generalization, and we find that while post-training alignment is most promising for real-world tasks, empowering LLM graph reasoning to go beyond pattern memorization remains an open research question.