 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Text-Image Generation with Weakness-Targeted Post-Training
Jan 07, 2026Unified multimodal generation architectures that jointly produce text and images have recently emerged as a promising direction for text-to-image (T2I) synthesis. However, many existing systems rely on explicit modality switching, generating reasoning text before switching manually to image generation. This separate, sequential inference process limits cross-modal coupling and prohibits automatic multimodal generation. This work explores post-training to achieve fully unified text-image generation, where models autonomously transition from textual reasoning to visual synthesis within a single inference process. We examine the impact of joint text-image generation on T2I performance and the relative importance of each modality during post-training. We additionally explore different post-training data strategies, showing that a targeted dataset addressing specific limitations achieves superior results compared to broad image-caption corpora or benchmark-aligned data. Using offline, reward-weighted post-training with fully self-generated synthetic data, our approach enables improvements in multimodal image generation across four diverse T2I benchmarks, demonstrating the effectiveness of reward-weighting both modalities and strategically designed post-training data.
Multimodal RewardBench 2: Evaluating Omni Reward Models for Interleaved Text and Image
Dec 18, 2025Reward models (RMs) are essential for training large language models (LLMs), but remain underexplored for omni models that handle interleaved image and text sequences. We introduce Multimodal RewardBench 2 (MMRB2), the first comprehensive benchmark for reward models on multimodal understanding and (interleaved) generation. MMRB2 spans four tasks: text-to-image, image editing, interleaved generation, and multimodal reasoning ("thinking-with-images"), providing 1,000 expert-annotated preference pairs per task from 23 models and agents across 21 source tasks. MMRB2 is designed with: (1) practical but challenging prompts; (2) responses from state-of-the-art models and agents; and (3) preference pairs with strong human-expert consensus, curated via an ensemble filtering strategy. Using MMRB2, we study existing judges for each subtask, including multimodal LLM-as-a-judge and models trained with human preferences. The latest Gemini 3 Pro attains 75-80% accuracy. GPT-5 and Gemini 2.5 Pro reach 66-75% accuracy, compared to >90% for humans, yet surpass the widely used GPT-4o (59%). The best performing open-source model Qwen3-VL-32B achieves similar accuracies as Gemini 2.5 Flash (64%). We also show that MMRB2 performance strongly correlates with downstream task success using Best-of-N sampling and conduct an in-depth analysis that shows key areas to improve the reward models going forward.
GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation
Dec 18, 2025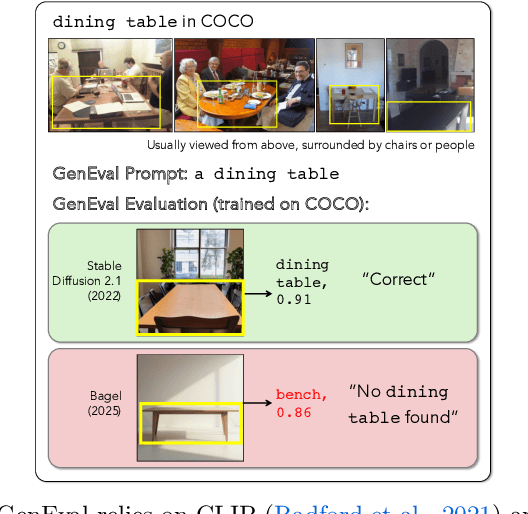
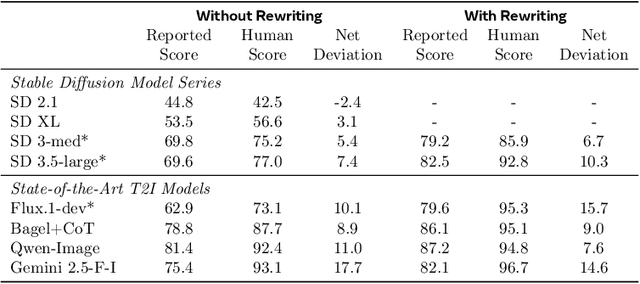
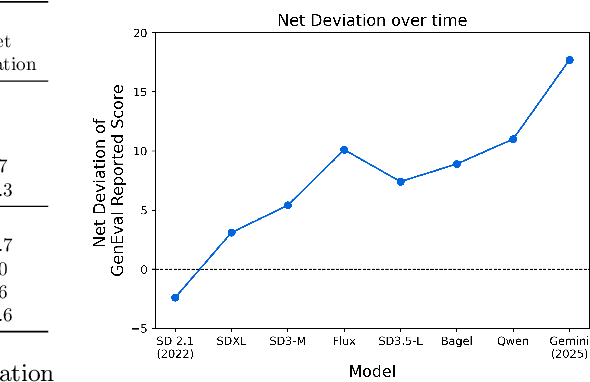
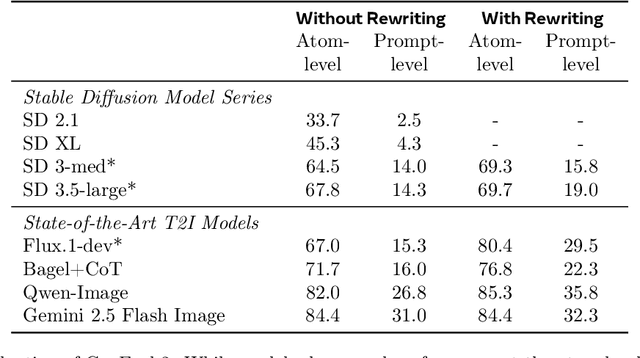
Automating Text-to-Image (T2I) model evaluation is challenging; a judge model must be used to score correctness, and test prompts must be selected to be challenging for current T2I models but not the judge. We argue that satisfying these constraints can lead to benchmark drift over time, where the static benchmark judges fail to keep up with newer model capabilities. We show that benchmark drift is a significant problem for GenEval, one of the most popular T2I benchmarks. Although GenEval was well-aligned with human judgment at the time of its release, it has drifted far from human judgment over time -- resulting in an absolute error of as much as 17.7% for current models. This level of drift strongly suggests that GenEval has been saturated for some time, as we verify via a large-scale human study. To help fill this benchmarking gap, we introduce a new benchmark, GenEval 2, with improved coverage of primitive visual concepts and higher degrees of compositionality, which we show is more challenging for current models. We also introduce Soft-TIFA, an evaluation method for GenEval 2 that combines judgments for visual primitives, which we show is more well-aligned with human judgment and argue is less likely to drift from human-alignment over time (as compared to more holistic judges such as VQAScore). Although we hope GenEval 2 will provide a strong benchmark for many years, avoiding benchmark drift is far from guaranteed and our work, more generally, highlights the importance of continual audits and improvement for T2I and related automated model evaluation benchmarks.
reWordBench: Benchmarking and Improving the Robustness of Reward Models with Transformed Inputs
Mar 14, 2025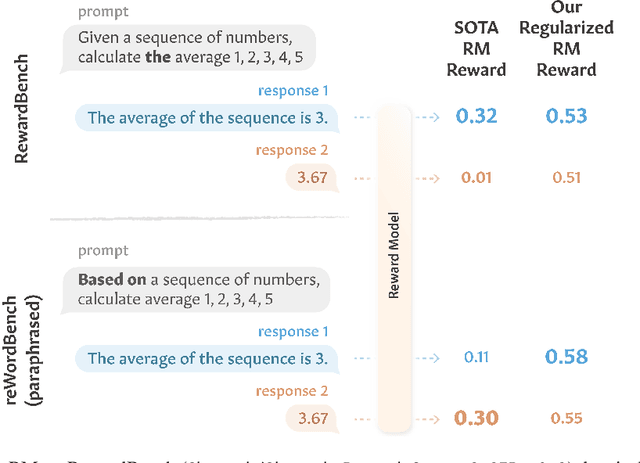


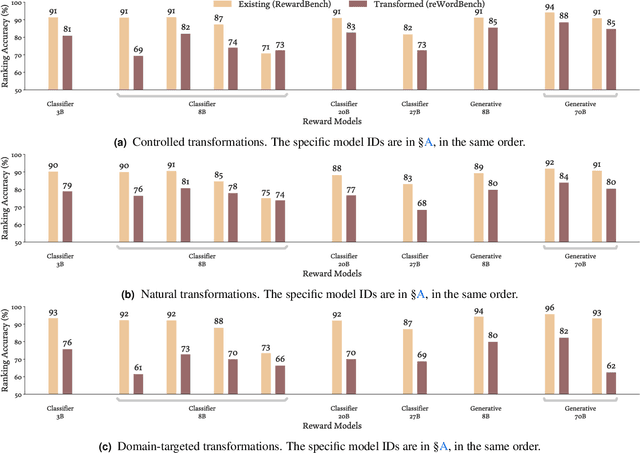
Reward models have become a staple in modern NLP, serving as not only a scalable text evaluator, but also an indispensable component in many alignment recipes and inference-time algorithms. However, while recent reward models increase performance on standard benchmarks, this may partly be due to overfitting effects, which would confound an understanding of their true capability. In this work, we scrutinize the robustness of reward models and the extent of such overfitting. We build **reWordBench**, which systematically transforms reward model inputs in meaning- or ranking-preserving ways. We show that state-of-the-art reward models suffer from substantial performance degradation even with minor input transformations, sometimes dropping to significantly below-random accuracy, suggesting brittleness. To improve reward model robustness, we propose to explicitly train them to assign similar scores to paraphrases, and find that this approach also improves robustness to other distinct kinds of transformations. For example, our robust reward model reduces such degradation by roughly half for the Chat Hard subset in RewardBench. Furthermore, when used in alignment, our robust reward models demonstrate better utility and lead to higher-quality outputs, winning in up to 59% of instances against a standardly trained RM.
Multimodal RewardBench: Holistic Evaluation of Reward Models for Vision Language Models
Feb 20, 2025Reward models play an essential role in training vision-language models (VLMs) by assessing output quality to enable aligning with human preferences. Despite their importance, the research community lacks comprehensive open benchmarks for evaluating multimodal reward models in VLMs. To address this gap, we introduce Multimodal RewardBench, an expert-annotated benchmark covering six domains: general correctness, preference, knowledge, reasoning, safety, and visual question-answering. Our dataset comprises 5,211 annotated (prompt, chosen response, rejected response) triplets collected from various VLMs. In evaluating a range of VLM judges, we find that even the top-performing models, Gemini 1.5 Pro and Claude 3.5 Sonnet, achieve only 72% overall accuracy. Notably, most models struggle in the reasoning and safety domains. These findings suggest that Multimodal RewardBench offers a challenging testbed for advancing reward model development across multiple domains. We release the benchmark at https://github.com/facebookresearch/multimodal_rewardbench.
Learning to Plan & Reason for Evaluation with Thinking-LLM-as-a-Judge
Jan 30, 2025



LLM-as-a-Judge models generate chain-of-thought (CoT) sequences intended to capture the step-bystep reasoning process that underlies the final evaluation of a response. However, due to the lack of human annotated CoTs for evaluation, the required components and structure of effective reasoning traces remain understudied. Consequently, previous approaches often (1) constrain reasoning traces to hand-designed components, such as a list of criteria, reference answers, or verification questions and (2) structure them such that planning is intertwined with the reasoning for evaluation. In this work, we propose EvalPlanner, a preference optimization algorithm for Thinking-LLM-as-a-Judge that first generates an unconstrained evaluation plan, followed by its execution, and then the final judgment. In a self-training loop, EvalPlanner iteratively optimizes over synthetically constructed evaluation plans and executions, leading to better final verdicts. Our method achieves a new state-of-the-art performance for generative reward models on RewardBench (with a score of 93.9), despite being trained on fewer amount of, and synthetically generated, preference pairs. Additional experiments on other benchmarks like RM-Bench, JudgeBench, and FollowBenchEval further highlight the utility of both planning and reasoning for building robust LLM-as-a-Judge reasoning models.
ALMA: Alignment with Minimal Annotation
Dec 05, 2024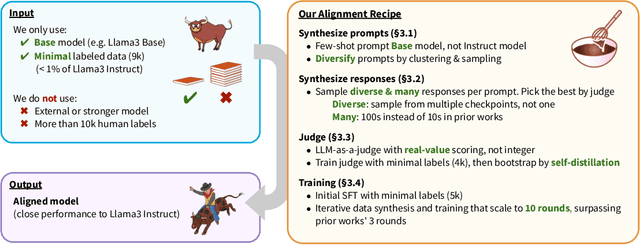
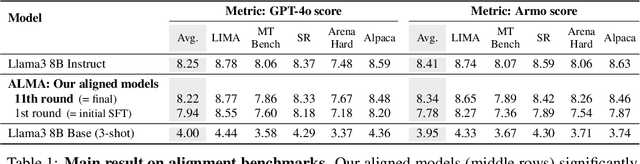
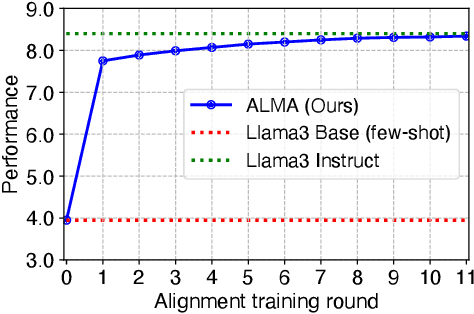

Recent approaches to large language model (LLM) alignment typically require millions of human annotations or rely on external aligned models for synthetic data generation. This paper introduces ALMA: Alignment with Minimal Annotation, demonstrating that effective alignment can be achieved using only 9,000 labeled examples -- less than 1% of conventional approaches. ALMA generates large amounts of high-quality synthetic alignment data through new techniques: diverse prompt synthesis via few-shot learning, diverse response generation with multiple model checkpoints, and judge (reward model) enhancement through score aggregation and self-distillation. Using only a pretrained Llama3 base model, 5,000 SFT examples, and 4,000 judge annotations, ALMA achieves performance close to Llama3-Instruct across diverse alignment benchmarks (e.g., 0.1% difference on AlpacaEval 2.0 score). These results are achieved with a multi-round, self-bootstrapped data synthesis and training recipe that continues to improve for 10 rounds, surpassing the typical 3-round ceiling of previous methods. These results suggest that base models already possess sufficient knowledge for effective alignment, and that synthetic data generation methods can expose it.
JPEG-LM: LLMs as Image Generators with Canonical Codec Representations
Aug 15, 2024Recent work in image and video generation has been adopting the autoregressive LLM architecture due to its generality and potentially easy integration into multi-modal systems. The crux of applying autoregressive training in language generation to visual generation is discretization -- representing continuous data like images and videos as discrete tokens. Common methods of discretizing images and videos include modeling raw pixel values, which are prohibitively lengthy, or vector quantization, which requires convoluted pre-hoc training. In this work, we propose to directly model images and videos as compressed files saved on computers via canonical codecs (e.g., JPEG, AVC/H.264). Using the default Llama architecture without any vision-specific modifications, we pretrain JPEG-LM from scratch to generate images (and AVC-LM to generate videos as a proof of concept), by directly outputting compressed file bytes in JPEG and AVC formats. Evaluation of image generation shows that this simple and straightforward approach is more effective than pixel-based modeling and sophisticated vector quantization baselines (on which our method yields a 31% reduction in FID). Our analysis shows that JPEG-LM has an especial advantage over vector quantization models in generating long-tail visual elements. Overall, we show that using canonical codec representations can help lower the barriers between language generation and visual generation, facilitating future research on multi-modal language/image/video LLMs.
SSD-2: Scaling and Inference-time Fusion of Diffusion Language Models
May 24, 2023Diffusion-based language models (LMs) have been shown to be competent generative models that are easy to control at inference and are a promising alternative to autoregressive LMs. While autoregressive LMs have benefited immensely from scaling and instruction-based learning, existing studies on diffusion LMs have been conducted on a relatively smaller scale. Starting with a recently proposed diffusion model SSD-LM, in this work we explore methods to scale it from 0.4B to 13B parameters, proposing several techniques to improve its training and inference efficiency. We call the new model SSD-2. We further show that this model can be easily finetuned to follow instructions. Finally, leveraging diffusion models' capability at inference-time control, we show that SSD-2 facilitates novel ensembles with 100x smaller models that can be customized and deployed by individual users. We find that compared to autoregressive models, the collaboration between diffusion models is more effective, leading to higher-quality and more relevant model responses due to their ability to incorporate bi-directional contexts.
Dictionary-based Phrase-level Prompting of Large Language Models for Machine Translation
Feb 15, 2023



Large language models (LLMs) demonstrate remarkable machine translation (MT) abilities via prompting, even though they were not explicitly trained for this task. However, even given the incredible quantities of data they are trained on, LLMs can struggle to translate inputs with rare words, which are common in low resource or domain transfer scenarios. We show that LLM prompting can provide an effective solution for rare words as well, by using prior knowledge from bilingual dictionaries to provide control hints in the prompts. We propose a novel method, DiPMT, that provides a set of possible translations for a subset of the input words, thereby enabling fine-grained phrase-level prompted control of the LLM. Extensive experiments show that DiPMT outperforms the baseline both in low-resource MT, as well as for out-of-domain MT. We further provide a qualitative analysis of the benefits and limitations of this approach, including the overall level of controllability that is achieved.