 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Frames to Sequences: Temporally Consistent Human-Centric Dense Prediction
Feb 03, 2026In this work, we focus on the challenge of temporally consistent human-centric dense prediction across video sequences. Existing models achieve strong per-frame accuracy but often flicker under motion, occlusion, and lighting changes, and they rarely have paired human video supervision for multiple dense tasks. We address this gap with a scalable synthetic data pipeline that generates photorealistic human frames and motion-aligned sequences with pixel-accurate depth, normals, and masks. Unlike prior static data synthetic pipelines, our pipeline provides both frame-level labels for spatial learning and sequence-level supervision for temporal learning. Building on this, we train a unified ViT-based dense predictor that (i) injects an explicit human geometric prior via CSE embeddings and (ii) improves geometry-feature reliability with a lightweight channel reweighting module after feature fusion. Our two-stage training strategy, combining static pretraining with dynamic sequence supervision, enables the model first to acquire robust spatial representations and then refine temporal consistency across motion-aligned sequences. Extensive experiments show that we achieve state-of-the-art performance on THuman2.1 and Hi4D and generalize effectively to in-the-wild videos.
A Visual Semantic Adaptive Watermark grounded by Prefix-Tuning for Large Vision-Language Model
Jan 12, 2026Watermarking has emerged as a pivotal solution for content traceability and intellectual property protection in Large Vision-Language Models (LVLMs). However, vision-agnostic watermarks introduce visually irrelevant tokens and disrupt visual grounding by enforcing indiscriminate pseudo-random biases, while some semantic-aware methods incur prohibitive inference latency due to rejection sampling. In this paper, we propose the VIsual Semantic Adaptive Watermark (VISA-Mark), a novel framework that embeds detectable signals while strictly preserving visual fidelity. Our approach employs a lightweight, efficiently trained prefix-tuner to extract dynamic Visual-Evidence Weights, which quantify the evidentiary support for candidate tokens based on the visual input. These weights guide an adaptive vocabulary partitioning and logits perturbation mechanism, concentrating watermark strength specifically on visually-supported tokens. By actively aligning the watermark with visual evidence, VISA-Mark effectively maintains visual fidelity. Empirical results confirm that VISA-Mark outperforms conventional methods with a 7.8% improvement in visual consistency (Chair-I) and superior semantic fidelity. The framework maintains highly competitive detection accuracy (96.88% AUC) and robust attack resilience (99.3%) without sacrificing inference efficiency, effectively establishing a new standard for reliability-preserving multimodal watermarking.
SYNAPSE: Empowering LLM Agents with Episodic-Semantic Memory via Spreading Activation
Jan 06, 2026While Large Language Models (LLMs) excel at generalized reasoning, standard retrieval-augmented approaches fail to address the disconnected nature of long-term agentic memory. To bridge this gap, we introduce Synapse (Synergistic Associative Processing Semantic Encoding), a unified memory architecture that transcends static vector similarity. Drawing from cognitive science, Synapse models memory as a dynamic graph where relevance emerges from spreading activation rather than pre-computed links. By integrating lateral inhibition and temporal decay, the system dynamically highlights relevant sub-graphs while filtering interference. We implement a Triple Hybrid Retrieval strategy that fuses geometric embeddings with activation-based graph traversal. Comprehensive evaluations on the LoCoMo benchmark show that Synapse significantly outperforms state-of-the-art methods in complex temporal and multi-hop reasoning tasks, offering a robust solution to the "Contextual Tunneling" problem. Our code and data will be made publicly available upon acceptance.
Achieving Fine-grained Cross-modal Understanding through Brain-inspired Hierarchical Representation Learning
Jan 04, 2026Understanding neural responses to visual stimuli remains challenging due to the inherent complexity of brain representations and the modality gap between neural data and visual inputs. Existing methods, mainly based on reducing neural decoding to generation tasks or simple correlations, fail to reflect the hierarchical and temporal processes of visual processing in the brain. To address these limitations, we present NeuroAlign, a novel framework for fine-grained fMRI-video alignment inspired by the hierarchical organization of the human visual system. Our framework implements a two-stage mechanism that mirrors biological visual pathways: global semantic understanding through Neural-Temporal Contrastive Learning (NTCL) and fine-grained pattern matching through enhanced vector quantization. NTCL explicitly models temporal dynamics through bidirectional prediction between modalities, while our DynaSyncMM-EMA approach enables dynamic multi-modal fusion with adaptive weighting. Experiments demonstrate that NeuroAlign significantly outperforms existing methods in cross-modal retrieval tasks, establishing a new paradigm for understanding visual cognitive mechanisms.
Interpreting Fedspeak with Confidence: A LLM-Based Uncertainty-Aware Framework Guided by Monetary Policy Transmission Paths
Aug 12, 2025"Fedspeak", the stylized and often nuanced language used by the U.S. Federal Reserve, encodes implicit policy signals and strategic stances. The Federal Open Market Committee strategically employs Fedspeak as a communication tool to shape market expectations and influence both domestic and global economic conditions. As such, automatically parsing and interpreting Fedspeak presents a high-impact challenge, with significant implications for financial forecasting, algorithmic trading, and data-driven policy analysis. In this paper, we propose an LLM-based, uncertainty-aware framework for deciphering Fedspeak and classifying its underlying monetary policy stance. Technically, to enrich the semantic and contextual representation of Fedspeak texts, we incorporate domain-specific reasoning grounded in the monetary policy transmission mechanism. We further introduce a dynamic uncertainty decoding module to assess the confidence of model predictions, thereby enhancing both classification accuracy and model reliability. Experimental results demonstrate that our framework achieves state-of-the-art performance on the policy stance analysis task. Moreover, statistical analysis reveals a significant positive correlation between perceptual uncertainty and model error rates, validating the effectiveness of perceptual uncertainty as a diagnostic signal.
Survey of HPC in US Research Institutions
Jun 23, 2025

The rapid growth of AI, data-intensive science, and digital twin technologies has driven an unprecedented demand for high-performance computing (HPC) across the research ecosystem. While national laboratories and industrial hyperscalers have invested heavily in exascale and GPU-centric architectures, university-operated HPC systems remain comparatively under-resourced. This survey presents a comprehensive assessment of the HPC landscape across U.S. universities, benchmarking their capabilities against Department of Energy (DOE) leadership-class systems and industrial AI infrastructures. We examine over 50 premier research institutions, analyzing compute capacity, architectural design, governance models, and energy efficiency. Our findings reveal that university clusters, though vital for academic research, exhibit significantly lower growth trajectories (CAGR $\approx$ 18%) than their national ($\approx$ 43%) and industrial ($\approx$ 78%) counterparts. The increasing skew toward GPU-dense AI workloads has widened the capability gap, highlighting the need for federated computing, idle-GPU harvesting, and cost-sharing models. We also identify emerging paradigms, such as decentralized reinforcement learning, as promising opportunities for democratizing AI training within campus environments. Ultimately, this work provides actionable insights for academic leaders, funding agencies, and technology partners to ensure more equitable and sustainable HPC access in support of national research priorities.
MADFormer: Mixed Autoregressive and Diffusion Transformers for Continuous Image Generation
Jun 09, 2025



Recent progress in multimodal generation has increasingly combined autoregressive (AR) and diffusion-based approaches, leveraging their complementary strengths: AR models capture long-range dependencies and produce fluent, context-aware outputs, while diffusion models operate in continuous latent spaces to refine high-fidelity visual details. However, existing hybrids often lack systematic guidance on how and why to allocate model capacity between these paradigms. In this work, we introduce MADFormer, a Mixed Autoregressive and Diffusion Transformer that serves as a testbed for analyzing AR-diffusion trade-offs. MADFormer partitions image generation into spatial blocks, using AR layers for one-pass global conditioning across blocks and diffusion layers for iterative local refinement within each block. Through controlled experiments on FFHQ-1024 and ImageNet, we identify two key insights: (1) block-wise partitioning significantly improves performance on high-resolution images, and (2) vertically mixing AR and diffusion layers yields better quality-efficiency balances--improving FID by up to 75% under constrained inference compute. Our findings offer practical design principles for future hybrid generative models.
Multimodal LLM-Guided Semantic Correction in Text-to-Image Diffusion
May 26, 2025



Diffusion models have become the mainstream architecture for text-to-image generation, achieving remarkable progress in visual quality and prompt controllability. However, current inference pipelines generally lack interpretable semantic supervision and correction mechanisms throughout the denoising process. Most existing approaches rely solely on post-hoc scoring of the final image, prompt filtering, or heuristic resampling strategies-making them ineffective in providing actionable guidance for correcting the generative trajectory. As a result, models often suffer from object confusion, spatial errors, inaccurate counts, and missing semantic elements, severely compromising prompt-image alignment and image quality. To tackle these challenges, we propose MLLM Semantic-Corrected Ping-Pong-Ahead Diffusion (PPAD), a novel framework that, for the first time, introduces a Multimodal Large Language Model (MLLM) as a semantic observer during inference. PPAD performs real-time analysis on intermediate generations, identifies latent semantic inconsistencies, and translates feedback into controllable signals that actively guide the remaining denoising steps. The framework supports both inference-only and training-enhanced settings, and performs semantic correction at only extremely few diffusion steps, offering strong generality and scalability. Extensive experiments demonstrate PPAD's significant improvements.
DanceTogether! Identity-Preserving Multi-Person Interactive Video Generation
May 23, 2025Controllable video generation (CVG) has advanced rapidly, yet current systems falter when more than one actor must move, interact, and exchange positions under noisy control signals. We address this gap with DanceTogether, the first end-to-end diffusion framework that turns a single reference image plus independent pose-mask streams into long, photorealistic videos while strictly preserving every identity. A novel MaskPoseAdapter binds "who" and "how" at every denoising step by fusing robust tracking masks with semantically rich-but noisy-pose heat-maps, eliminating the identity drift and appearance bleeding that plague frame-wise pipelines. To train and evaluate at scale, we introduce (i) PairFS-4K, 26 hours of dual-skater footage with 7,000+ distinct IDs, (ii) HumanRob-300, a one-hour humanoid-robot interaction set for rapid cross-domain transfer, and (iii) TogetherVideoBench, a three-track benchmark centered on the DanceTogEval-100 test suite covering dance, boxing, wrestling, yoga, and figure skating. On TogetherVideoBench, DanceTogether outperforms the prior arts by a significant margin. Moreover, we show that a one-hour fine-tune yields convincing human-robot videos, underscoring broad generalization to embodied-AI and HRI tasks. Extensive ablations confirm that persistent identity-action binding is critical to these gains. Together, our model, datasets, and benchmark lift CVG from single-subject choreography to compositionally controllable, multi-actor interaction, opening new avenues for digital production, simulation, and embodied intelligence. Our video demos and code are available at https://DanceTog.github.io/.
Large Language Models for Bioinformatics
Jan 10, 2025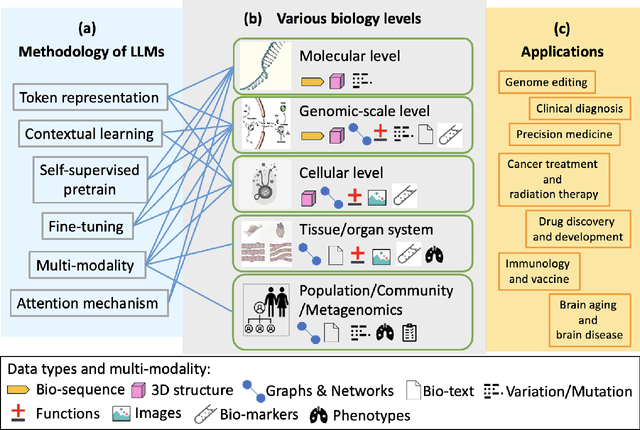
With the rapid advancements in large language model (LLM) technology and the emergence of bioinformatics-specific language models (BioLMs), there is a growing need for a comprehensive analysis of the current landscape, computational characteristics, and diverse applications. This survey aims to address this need by providing a thorough review of BioLMs, focusing on their evolution, classification, and distinguishing features, alongside a detailed examination of training methodologies, datasets, and evaluation frameworks. We explore the wide-ranging applications of BioLMs in critical areas such as disease diagnosis, drug discovery, and vaccine development, highlighting their impact and transformative potential in bioinformatics. We identify key challenges and limitations inherent in BioLMs, including data privacy and security concerns, interpretability issues, biases in training data and model outputs, and domain adaptation complexities. Finally, we highlight emerging trends and future directions, offering valuable insights to guide researchers and clinicians toward advancing BioLMs for increasingly sophisticated biological and clinical applications.