 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLottieGPT: Tokenizing Vector Animation for Autoregressive Generation
Apr 13, 2026Despite rapid progress in video generation, existing models are incapable of producing vector animation, a dominant and highly expressive form of multimedia on the Internet. Vector animations offer resolution-independence, compactness, semantic structure, and editable parametric motion representations, yet current generative models operate exclusively in raster space and thus cannot synthesize them. Meanwhile, recent advances in large multimodal models demonstrate strong capabilities in generating structured data such as slides, 3D meshes, LEGO sequences, and indoor layouts, suggesting that native vector animation generation may be achievable. In this work, we present the first framework for tokenizing and autoregressively generating vector animations. We adopt Lottie, a widely deployed JSON-based animation standard, and design a tailored Lottie Tokenizer that encodes layered geometric primitives, transforms, and keyframe-based motion into a compact and semantically aligned token sequence. To support large-scale training, we also construct LottieAnimation-660K, the largest and most diverse vector animation dataset to date, consisting of 660k real-world Lottie animation and 15M static Lottie image files curated from broad Internet sources. Building upon these components, we finetune Qwen-VL to create LottieGPT, a native multimodal model capable of generating coherent, editable vector animations directly from natural language or visual prompts. Experiments show that our tokenizer dramatically reduces sequence length while preserving structural fidelity, enabling effective autoregressive learning of dynamic vector content. LottieGPT exhibits strong generalization across diverse animation styles and outperforms previous state-of-the-art models on SVG generation (a special case of single-frame vector animation).
SynthVerse: A Large-Scale Diverse Synthetic Dataset for Point Tracking
Feb 04, 2026Point tracking aims to follow visual points through complex motion, occlusion, and viewpoint changes, and has advanced rapidly with modern foundation models. Yet progress toward general point tracking remains constrained by limited high-quality data, as existing datasets often provide insufficient diversity and imperfect trajectory annotations. To this end, we introduce SynthVerse, a large-scale, diverse synthetic dataset specifically designed for point tracking. SynthVerse includes several new domains and object types missing from existing synthetic datasets, such as animated-film-style content, embodied manipulation, scene navigation, and articulated objects. SynthVerse substantially expands dataset diversity by covering a broader range of object categories and providing high-quality dynamic motions and interactions, enabling more robust training and evaluation for general point tracking. In addition, we establish a highly diverse point tracking benchmark to systematically evaluate state-of-the-art methods under broader domain shifts. Extensive experiments and analyses demonstrate that training with SynthVerse yields consistent improvements in generalization and reveal limitations of existing trackers under diverse settings.
Topology-Agnostic Animal Motion Generation from Text Prompt
Dec 11, 2025Motion generation is fundamental to computer animation and widely used across entertainment, robotics, and virtual environments. While recent methods achieve impressive results, most rely on fixed skeletal templates, which prevent them from generalizing to skeletons with different or perturbed topologies. We address the core limitation of current motion generation methods - the combined lack of large-scale heterogeneous animal motion data and unified generative frameworks capable of jointly modeling arbitrary skeletal topologies and textual conditions. To this end, we introduce OmniZoo, a large-scale animal motion dataset spanning 140 species and 32,979 sequences, enriched with multimodal annotations. Building on OmniZoo, we propose a generalized autoregressive motion generation framework capable of producing text-driven motions for arbitrary skeletal topologies. Central to our model is a Topology-aware Skeleton Embedding Module that encodes geometric and structural properties of any skeleton into a shared token space, enabling seamless fusion with textual semantics. Given a text prompt and a target skeleton, our method generates temporally coherent, physically plausible, and semantically aligned motions, and further enables cross-species motion style transfer.
SIFThinker: Spatially-Aware Image Focus for Visual Reasoning
Aug 08, 2025Current multimodal large language models (MLLMs) still face significant challenges in complex visual tasks (e.g., spatial understanding, fine-grained perception). Prior methods have tried to incorporate visual reasoning, however, they fail to leverage attention correction with spatial cues to iteratively refine their focus on prompt-relevant regions. In this paper, we introduce SIFThinker, a spatially-aware "think-with-images" framework that mimics human visual perception. Specifically, SIFThinker enables attention correcting and image region focusing by interleaving depth-enhanced bounding boxes and natural language. Our contributions are twofold: First, we introduce a reverse-expansion-forward-inference strategy that facilitates the generation of interleaved image-text chains of thought for process-level supervision, which in turn leads to the construction of the SIF-50K dataset. Besides, we propose GRPO-SIF, a reinforced training paradigm that integrates depth-informed visual grounding into a unified reasoning pipeline, teaching the model to dynamically correct and focus on prompt-relevant regions. Extensive experiments demonstrate that SIFThinker outperforms state-of-the-art methods in spatial understanding and fine-grained visual perception, while maintaining strong general capabilities, highlighting the effectiveness of our method.
NFR: Neural Feature-Guided Non-Rigid Shape Registration
May 28, 2025In this paper, we propose a novel learning-based framework for 3D shape registration, which overcomes the challenges of significant non-rigid deformation and partiality undergoing among input shapes, and, remarkably, requires no correspondence annotation during training. Our key insight is to incorporate neural features learned by deep learning-based shape matching networks into an iterative, geometric shape registration pipeline. The advantage of our approach is two-fold -- On one hand, neural features provide more accurate and semantically meaningful correspondence estimation than spatial features (e.g., coordinates), which is critical in the presence of large non-rigid deformations; On the other hand, the correspondences are dynamically updated according to the intermediate registrations and filtered by consistency prior, which prominently robustify the overall pipeline. Empirical results show that, with as few as dozens of training shapes of limited variability, our pipeline achieves state-of-the-art results on several benchmarks of non-rigid point cloud matching and partial shape matching across varying settings, but also delivers high-quality correspondences between unseen challenging shape pairs that undergo both significant extrinsic and intrinsic deformations, in which case neither traditional registration methods nor intrinsic methods work.
DanceTogether! Identity-Preserving Multi-Person Interactive Video Generation
May 23, 2025Controllable video generation (CVG) has advanced rapidly, yet current systems falter when more than one actor must move, interact, and exchange positions under noisy control signals. We address this gap with DanceTogether, the first end-to-end diffusion framework that turns a single reference image plus independent pose-mask streams into long, photorealistic videos while strictly preserving every identity. A novel MaskPoseAdapter binds "who" and "how" at every denoising step by fusing robust tracking masks with semantically rich-but noisy-pose heat-maps, eliminating the identity drift and appearance bleeding that plague frame-wise pipelines. To train and evaluate at scale, we introduce (i) PairFS-4K, 26 hours of dual-skater footage with 7,000+ distinct IDs, (ii) HumanRob-300, a one-hour humanoid-robot interaction set for rapid cross-domain transfer, and (iii) TogetherVideoBench, a three-track benchmark centered on the DanceTogEval-100 test suite covering dance, boxing, wrestling, yoga, and figure skating. On TogetherVideoBench, DanceTogether outperforms the prior arts by a significant margin. Moreover, we show that a one-hour fine-tune yields convincing human-robot videos, underscoring broad generalization to embodied-AI and HRI tasks. Extensive ablations confirm that persistent identity-action binding is critical to these gains. Together, our model, datasets, and benchmark lift CVG from single-subject choreography to compositionally controllable, multi-actor interaction, opening new avenues for digital production, simulation, and embodied intelligence. Our video demos and code are available at https://DanceTog.github.io/.
ARMO: Autoregressive Rigging for Multi-Category Objects
Mar 26, 2025Recent advancements in large-scale generative models have significantly improved the quality and diversity of 3D shape generation. However, most existing methods focus primarily on generating static 3D models, overlooking the potentially dynamic nature of certain shapes, such as humanoids, animals, and insects. To address this gap, we focus on rigging, a fundamental task in animation that establishes skeletal structures and skinning for 3D models. In this paper, we introduce OmniRig, the first large-scale rigging dataset, comprising 79,499 meshes with detailed skeleton and skinning information. Unlike traditional benchmarks that rely on predefined standard poses (e.g., A-pose, T-pose), our dataset embraces diverse shape categories, styles, and poses. Leveraging this rich dataset, we propose ARMO, a novel rigging framework that utilizes an autoregressive model to predict both joint positions and connectivity relationships in a unified manner. By treating the skeletal structure as a complete graph and discretizing it into tokens, we encode the joints using an auto-encoder to obtain a latent embedding and an autoregressive model to predict the tokens. A mesh-conditioned latent diffusion model is used to predict the latent embedding for conditional skeleton generation. Our method addresses the limitations of regression-based approaches, which often suffer from error accumulation and suboptimal connectivity estimation. Through extensive experiments on the OmniRig dataset, our approach achieves state-of-the-art performance in skeleton prediction, demonstrating improved generalization across diverse object categories. The code and dataset will be made public for academic use upon acceptance.
MOAT: Evaluating LMMs for Capability Integration and Instruction Grounding
Mar 12, 2025Large multimodal models (LMMs) have demonstrated significant potential as generalists in vision-language (VL) tasks. However, there remains a significant gap between state-of-the-art LMMs and human performance when it comes to complex tasks that require a combination of fundamental VL capabilities, as well as tasks involving the grounding of complex instructions. To thoroughly investigate the human-LMM gap and its underlying causes, we propose MOAT, a diverse benchmark with complex real-world VL tasks that are challenging for LMMs. Specifically, the tasks in MOAT require LMMs to engage in generalist problem solving by integrating fundamental VL capabilities such as reading text, counting, understanding spatial relations, grounding textual and visual instructions, etc. All these abilities fit into a taxonomy proposed by us that contains 10 fundamental VL capabilities, enabling MOAT to provide a fine-grained view of LMMs' strengths and weaknesses. Besides, MOAT is the first benchmark to explicitly evaluate LMMs' ability to ground complex text and visual instructions, which is essential to many real-world applications. We evaluate over 20 proprietary and open source LMMs, as well as humans, on MOAT, and found that humans achieved 82.7% accuracy while the best performing LMM (OpenAI o1) achieved only 38.8%. To guide future model development, we analyze common trends in our results and discuss the underlying causes of observed performance gaps between LMMs and humans, focusing on which VL capability forms the bottleneck in complex tasks, whether test time scaling improves performance on MOAT, and how tiling harms LMMs' capability to count. Code and data are available at https://cambrian-yzt.github.io/MOAT.
DRiVE: Diffusion-based Rigging Empowers Generation of Versatile and Expressive Characters
Nov 26, 2024


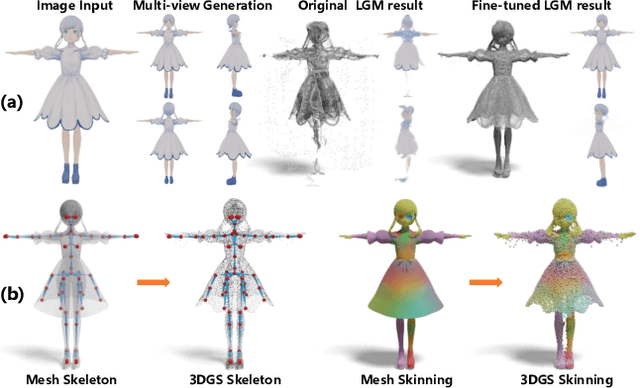
Recent advances in generative models have enabled high-quality 3D character reconstruction from multi-modal. However, animating these generated characters remains a challenging task, especially for complex elements like garments and hair, due to the lack of large-scale datasets and effective rigging methods. To address this gap, we curate AnimeRig, a large-scale dataset with detailed skeleton and skinning annotations. Building upon this, we propose DRiVE, a novel framework for generating and rigging 3D human characters with intricate structures. Unlike existing methods, DRiVE utilizes a 3D Gaussian representation, facilitating efficient animation and high-quality rendering. We further introduce GSDiff, a 3D Gaussian-based diffusion module that predicts joint positions as spatial distributions, overcoming the limitations of regression-based approaches. Extensive experiments demonstrate that DRiVE achieves precise rigging results, enabling realistic dynamics for clothing and hair, and surpassing previous methods in both quality and versatility. The code and dataset will be made public for academic use upon acceptance.
SRIF: Semantic Shape Registration Empowered by Diffusion-based Image Morphing and Flow Estimation
Sep 18, 2024
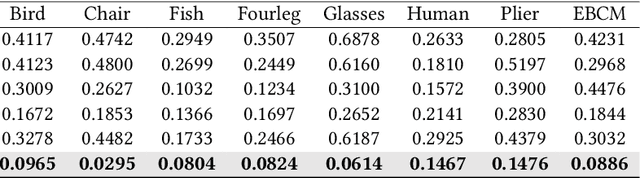
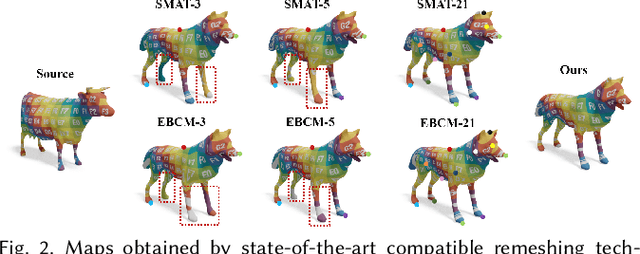
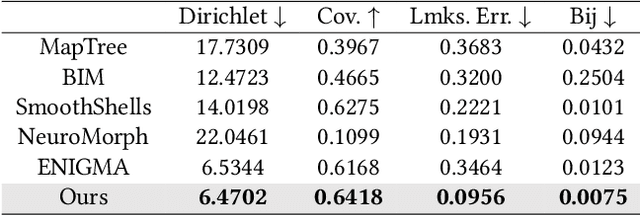
In this paper, we propose SRIF, a novel Semantic shape Registration framework based on diffusion-based Image morphing and Flow estimation. More concretely, given a pair of extrinsically aligned shapes, we first render them from multi-views, and then utilize an image interpolation framework based on diffusion models to generate sequences of intermediate images between them. The images are later fed into a dynamic 3D Gaussian splatting framework, with which we reconstruct and post-process for intermediate point clouds respecting the image morphing processing. In the end, tailored for the above, we propose a novel registration module to estimate continuous normalizing flow, which deforms source shape consistently towards the target, with intermediate point clouds as weak guidance. Our key insight is to leverage large vision models (LVMs) to associate shapes and therefore obtain much richer semantic information on the relationship between shapes than the ad-hoc feature extraction and alignment. As a consequence, SRIF achieves high-quality dense correspondences on challenging shape pairs, but also delivers smooth, semantically meaningful interpolation in between. Empirical evidence justifies the effectiveness and superiority of our method as well as specific design choices. The code is released at https://github.com/rqhuang88/SRIF.