 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-DMesh: Video-Guided 3D Animation via Rectified Dynamic Mesh Flow
May 14, 2026Video-guided 3D animation holds immense potential for content creation, offering intuitive and precise control over dynamic assets. However, practical deployment faces a critical yet frequently overlooked hurdle: the pose misalignment dilemma. In real-world scenarios, the initial pose of a user-provided static mesh rarely aligns with the starting frame of a reference video. Naively forcing a mesh to follow a mismatched trajectory inevitably leads to severe geometric distortion or animation failure. To address this, we present Rectified Dynamic Mesh (R-DMesh), a unified framework designed to generate high-fidelity 4D meshes that are ``rectified'' to align with video context. Unlike standard motion transfer approaches, our method introduces a novel VAE that explicitly disentangles the input into a conditional base mesh, relative motion trajectories, and a crucial rectification jump offset. This offset is learned to automatically transform the arbitrary pose of the input mesh to match the video's initial state before animation begins. We process these components via a Triflow Attention mechanism, which leverages vertex-wise geometric features to modulate the three orthogonal flows, ensuring physical consistency and local rigidity during the rectification and animation process. For generation, we employ a Rectified Flow-based Diffusion Transformer conditioned on pre-trained video latents, effectively transferring rich spatio-temporal priors to the 3D domain. To support this task, we construct Video-RDMesh, a large-scale dataset of over 500k dynamic mesh sequences specifically curated to simulate pose misalignment. Extensive experiments demonstrate that R-DMesh not only solves the alignment problem but also enables robust downstream applications, including pose retargeting and holistic 4D generation.
Improving Multi-View Reconstruction via Texture-Guided Gaussian-Mesh Joint Optimization
Nov 06, 2025Reconstructing real-world objects from multi-view images is essential for applications in 3D editing, AR/VR, and digital content creation. Existing methods typically prioritize either geometric accuracy (Multi-View Stereo) or photorealistic rendering (Novel View Synthesis), often decoupling geometry and appearance optimization, which hinders downstream editing tasks. This paper advocates an unified treatment on geometry and appearance optimization for seamless Gaussian-mesh joint optimization. More specifically, we propose a novel framework that simultaneously optimizes mesh geometry (vertex positions and faces) and vertex colors via Gaussian-guided mesh differentiable rendering, leveraging photometric consistency from input images and geometric regularization from normal and depth maps. The obtained high-quality 3D reconstruction can be further exploit in down-stream editing tasks, such as relighting and shape deformation. The code will be publicly available upon acceptance.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Auto-Connect: Connectivity-Preserving RigFormer with Direct Preference Optimization
Jun 13, 2025



We introduce Auto-Connect, a novel approach for automatic rigging that explicitly preserves skeletal connectivity through a connectivity-preserving tokenization scheme. Unlike previous methods that predict bone positions represented as two joints or first predict points before determining connectivity, our method employs special tokens to define endpoints for each joint's children and for each hierarchical layer, effectively automating connectivity relationships. This approach significantly enhances topological accuracy by integrating connectivity information directly into the prediction framework. To further guarantee high-quality topology, we implement a topology-aware reward function that quantifies topological correctness, which is then utilized in a post-training phase through reward-guided Direct Preference Optimization. Additionally, we incorporate implicit geodesic features for latent top-k bone selection, which substantially improves skinning quality. By leveraging geodesic distance information within the model's latent space, our approach intelligently determines the most influential bones for each vertex, effectively mitigating common skinning artifacts. This combination of connectivity-preserving tokenization, reward-guided fine-tuning, and geodesic-aware bone selection enables our model to consistently generate more anatomically plausible skeletal structures with superior deformation properties.
NFR: Neural Feature-Guided Non-Rigid Shape Registration
May 28, 2025In this paper, we propose a novel learning-based framework for 3D shape registration, which overcomes the challenges of significant non-rigid deformation and partiality undergoing among input shapes, and, remarkably, requires no correspondence annotation during training. Our key insight is to incorporate neural features learned by deep learning-based shape matching networks into an iterative, geometric shape registration pipeline. The advantage of our approach is two-fold -- On one hand, neural features provide more accurate and semantically meaningful correspondence estimation than spatial features (e.g., coordinates), which is critical in the presence of large non-rigid deformations; On the other hand, the correspondences are dynamically updated according to the intermediate registrations and filtered by consistency prior, which prominently robustify the overall pipeline. Empirical results show that, with as few as dozens of training shapes of limited variability, our pipeline achieves state-of-the-art results on several benchmarks of non-rigid point cloud matching and partial shape matching across varying settings, but also delivers high-quality correspondences between unseen challenging shape pairs that undergo both significant extrinsic and intrinsic deformations, in which case neither traditional registration methods nor intrinsic methods work.
DanceTogether! Identity-Preserving Multi-Person Interactive Video Generation
May 23, 2025Controllable video generation (CVG) has advanced rapidly, yet current systems falter when more than one actor must move, interact, and exchange positions under noisy control signals. We address this gap with DanceTogether, the first end-to-end diffusion framework that turns a single reference image plus independent pose-mask streams into long, photorealistic videos while strictly preserving every identity. A novel MaskPoseAdapter binds "who" and "how" at every denoising step by fusing robust tracking masks with semantically rich-but noisy-pose heat-maps, eliminating the identity drift and appearance bleeding that plague frame-wise pipelines. To train and evaluate at scale, we introduce (i) PairFS-4K, 26 hours of dual-skater footage with 7,000+ distinct IDs, (ii) HumanRob-300, a one-hour humanoid-robot interaction set for rapid cross-domain transfer, and (iii) TogetherVideoBench, a three-track benchmark centered on the DanceTogEval-100 test suite covering dance, boxing, wrestling, yoga, and figure skating. On TogetherVideoBench, DanceTogether outperforms the prior arts by a significant margin. Moreover, we show that a one-hour fine-tune yields convincing human-robot videos, underscoring broad generalization to embodied-AI and HRI tasks. Extensive ablations confirm that persistent identity-action binding is critical to these gains. Together, our model, datasets, and benchmark lift CVG from single-subject choreography to compositionally controllable, multi-actor interaction, opening new avenues for digital production, simulation, and embodied intelligence. Our video demos and code are available at https://DanceTog.github.io/.
DRiVE: Diffusion-based Rigging Empowers Generation of Versatile and Expressive Characters
Nov 26, 2024


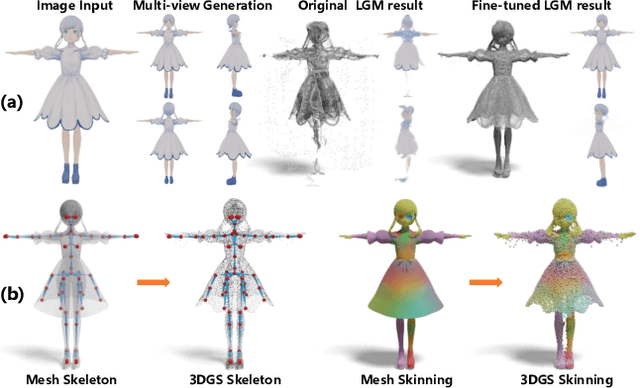
Recent advances in generative models have enabled high-quality 3D character reconstruction from multi-modal. However, animating these generated characters remains a challenging task, especially for complex elements like garments and hair, due to the lack of large-scale datasets and effective rigging methods. To address this gap, we curate AnimeRig, a large-scale dataset with detailed skeleton and skinning annotations. Building upon this, we propose DRiVE, a novel framework for generating and rigging 3D human characters with intricate structures. Unlike existing methods, DRiVE utilizes a 3D Gaussian representation, facilitating efficient animation and high-quality rendering. We further introduce GSDiff, a 3D Gaussian-based diffusion module that predicts joint positions as spatial distributions, overcoming the limitations of regression-based approaches. Extensive experiments demonstrate that DRiVE achieves precise rigging results, enabling realistic dynamics for clothing and hair, and surpassing previous methods in both quality and versatility. The code and dataset will be made public for academic use upon acceptance.
SRIF: Semantic Shape Registration Empowered by Diffusion-based Image Morphing and Flow Estimation
Sep 18, 2024
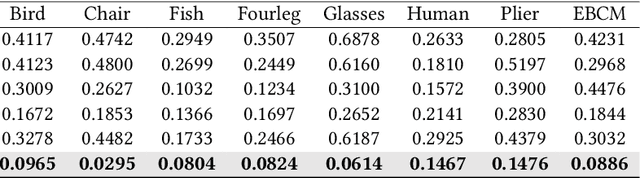
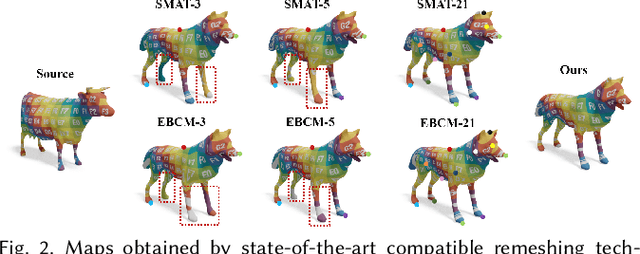
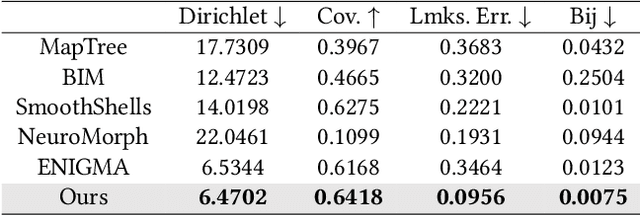
In this paper, we propose SRIF, a novel Semantic shape Registration framework based on diffusion-based Image morphing and Flow estimation. More concretely, given a pair of extrinsically aligned shapes, we first render them from multi-views, and then utilize an image interpolation framework based on diffusion models to generate sequences of intermediate images between them. The images are later fed into a dynamic 3D Gaussian splatting framework, with which we reconstruct and post-process for intermediate point clouds respecting the image morphing processing. In the end, tailored for the above, we propose a novel registration module to estimate continuous normalizing flow, which deforms source shape consistently towards the target, with intermediate point clouds as weak guidance. Our key insight is to leverage large vision models (LVMs) to associate shapes and therefore obtain much richer semantic information on the relationship between shapes than the ad-hoc feature extraction and alignment. As a consequence, SRIF achieves high-quality dense correspondences on challenging shape pairs, but also delivers smooth, semantically meaningful interpolation in between. Empirical evidence justifies the effectiveness and superiority of our method as well as specific design choices. The code is released at https://github.com/rqhuang88/SRIF.
Unsupervised Non-Rigid Point Cloud Matching through Large Vision Models
Aug 16, 2024



In this paper, we propose a novel learning-based framework for non-rigid point cloud matching, which can be trained purely on point clouds without any correspondence annotation but also be extended naturally to partial-to-full matching. Our key insight is to incorporate semantic features derived from large vision models (LVMs) to geometry-based shape feature learning. Our framework effectively leverages the structural information contained in the semantic features to address ambiguities arise from self-similarities among local geometries. Furthermore, our framework also enjoys the strong generalizability and robustness regarding partial observations of LVMs, leading to improvements in the regarding point cloud matching tasks. In order to achieve the above, we propose a pixel-to-point feature aggregation module, a local and global attention network as well as a geometrical similarity loss function. Experimental results show that our method achieves state-of-the-art results in matching non-rigid point clouds in both near-isometric and heterogeneous shape collection as well as more realistic partial and noisy data.