 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo BERT Embeddings Encode Narrative Dimensions? A Token-Level Probing Analysis of Time, Space, Causality, and Character in Fiction
Apr 12, 2026Narrative understanding requires multidimensional semantic structures. This study investigates whether BERT embeddings encode dimensions of fictional narrative semantics -- time, space, causality, and character. Using an LLM to accelerate annotation, we construct a token-level dataset labeled with these four narrative categories plus "others." A linear probe on BERT embeddings (94% accuracy) significantly outperforms a control probe on variance-matched random embeddings (47%), confirming that BERT encodes meaningful narrative information. With balanced class weighting, the probe achieves a macro-average recall of 0.83, with moderate success on rare categories such as causality (recall = 0.75) and space (recall = 0.66). However, confusion matrix analysis reveals "Boundary Leakage," where rare dimensions are systematically misclassified as "others." Clustering analysis shows that unsupervised clustering aligns near-randomly with predefined categories (ARI = 0.081), suggesting that narrative dimensions are encoded but not as discretely separable clusters. Future work includes a POS-only baseline to disentangle syntactic patterns from narrative encoding, expanded datasets, and layer-wise probing.
Gaussian Wardrobe: Compositional 3D Gaussian Avatars for Free-Form Virtual Try-On
Mar 05, 2026We introduce Gaussian Wardrobe, a novel framework to digitalize compositional 3D neural avatars from multi-view videos. Existing methods for 3D neural avatars typically treat the human body and clothing as an inseparable entity. However, this paradigm fails to capture the dynamics of complex free-form garments and limits the reuse of clothing across different individuals. To overcome these problems, we develop a novel, compositional 3D Gaussian representation to build avatars from multiple layers of free-form garments. The core of our method is decomposing neural avatars into bodies and layers of shape-agnostic neural garments. To achieve this, our framework learns to disentangle each garment layer from multi-view videos and canonicalizes it into a shape-independent space. In experiments, our method models photorealistic avatars with high-fidelity dynamics, achieving new state-of-the-art performance on novel pose synthesis benchmarks. In addition, we demonstrate that the learned compositional garments contribute to a versatile digital wardrobe, enabling a practical virtual try-on application where clothing can be freely transferred to new subjects. Project page: https://ait.ethz.ch/gaussianwardrobe
FlexAvatar: Flexible Large Reconstruction Model for Animatable Gaussian Head Avatars with Detailed Deformation
Dec 19, 2025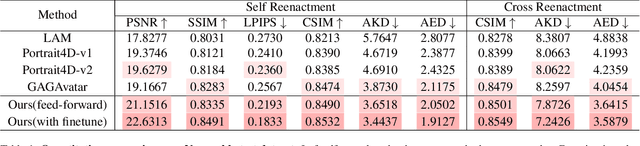
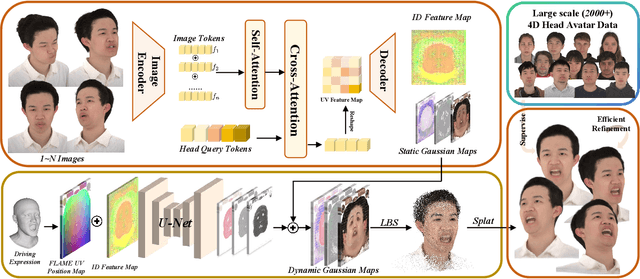
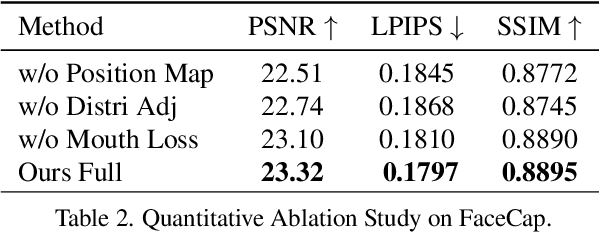

We present FlexAvatar, a flexible large reconstruction model for high-fidelity 3D head avatars with detailed dynamic deformation from single or sparse images, without requiring camera poses or expression labels. It leverages a transformer-based reconstruction model with structured head query tokens as canonical anchor to aggregate flexible input-number-agnostic, camera-pose-free and expression-free inputs into a robust canonical 3D representation. For detailed dynamic deformation, we introduce a lightweight UNet decoder conditioned on UV-space position maps, which can produce detailed expression-dependent deformations in real time. To better capture rare but critical expressions like wrinkles and bared teeth, we also adopt a data distribution adjustment strategy during training to balance the distribution of these expressions in the training set. Moreover, a lightweight 10-second refinement can further enhances identity-specific details in extreme identities without affecting deformation quality. Extensive experiments demonstrate that our FlexAvatar achieves superior 3D consistency, detailed dynamic realism compared with previous methods, providing a practical solution for animatable 3D avatar creation.
SEGA: Drivable 3D Gaussian Head Avatar from a Single Image
Apr 19, 2025Creating photorealistic 3D head avatars from limited input has become increasingly important for applications in virtual reality, telepresence, and digital entertainment. While recent advances like neural rendering and 3D Gaussian splatting have enabled high-quality digital human avatar creation and animation, most methods rely on multiple images or multi-view inputs, limiting their practicality for real-world use. In this paper, we propose SEGA, a novel approach for Single-imagE-based 3D drivable Gaussian head Avatar creation that combines generalized prior models with a new hierarchical UV-space Gaussian Splatting framework. SEGA seamlessly combines priors derived from large-scale 2D datasets with 3D priors learned from multi-view, multi-expression, and multi-ID data, achieving robust generalization to unseen identities while ensuring 3D consistency across novel viewpoints and expressions. We further present a hierarchical UV-space Gaussian Splatting framework that leverages FLAME-based structural priors and employs a dual-branch architecture to disentangle dynamic and static facial components effectively. The dynamic branch encodes expression-driven fine details, while the static branch focuses on expression-invariant regions, enabling efficient parameter inference and precomputation. This design maximizes the utility of limited 3D data and achieves real-time performance for animation and rendering. Additionally, SEGA performs person-specific fine-tuning to further enhance the fidelity and realism of the generated avatars. Experiments show our method outperforms state-of-the-art approaches in generalization ability, identity preservation, and expression realism, advancing one-shot avatar creation for practical applications.
Vid2Avatar-Pro: Authentic Avatar from Videos in the Wild via Universal Prior
Mar 03, 2025We present Vid2Avatar-Pro, a method to create photorealistic and animatable 3D human avatars from monocular in-the-wild videos. Building a high-quality avatar that supports animation with diverse poses from a monocular video is challenging because the observation of pose diversity and view points is inherently limited. The lack of pose variations typically leads to poor generalization to novel poses, and avatars can easily overfit to limited input view points, producing artifacts and distortions from other views. In this work, we address these limitations by leveraging a universal prior model (UPM) learned from a large corpus of multi-view clothed human performance capture data. We build our representation on top of expressive 3D Gaussians with canonical front and back maps shared across identities. Once the UPM is learned to accurately reproduce the large-scale multi-view human images, we fine-tune the model with an in-the-wild video via inverse rendering to obtain a personalized photorealistic human avatar that can be faithfully animated to novel human motions and rendered from novel views. The experiments show that our approach based on the learned universal prior sets a new state-of-the-art in monocular avatar reconstruction by substantially outperforming existing approaches relying only on heuristic regularization or a shape prior of minimally clothed bodies (e.g., SMPL) on publicly available datasets.
Packing Analysis: Packing Is More Appropriate for Large Models or Datasets in Supervised Fine-tuning
Oct 10, 2024



Packing, initially utilized in the pre-training phase, is an optimization technique designed to maximize hardware resource efficiency by combining different training sequences to fit the model's maximum input length. Although it has demonstrated effectiveness during pre-training, there remains a lack of comprehensive analysis for the supervised fine-tuning (SFT) stage on the following points: (1) whether packing can effectively enhance training efficiency while maintaining performance, (2) the suitable size of the model and dataset for fine-tuning with the packing method, and (3) whether packing unrelated or related training samples might cause the model to either excessively disregard or over-rely on the context. In this paper, we perform extensive comparisons between SFT methods using padding and packing, covering SFT datasets ranging from 69K to 1.2M and models from 8B to 70B. This provides the first comprehensive analysis of the advantages and limitations of packing versus padding, as well as practical considerations for implementing packing in various training scenarios. Our analysis covers various benchmarks, including knowledge, reasoning, and coding, as well as GPT-based evaluations, time efficiency, and other fine-tuning parameters. We also open-source our code for fine-tuning and evaluation and provide checkpoints fine-tuned on datasets of different sizes, aiming to advance future research on packing methods. Code is available at: https://github.com/ShuheWang1998/Packing-Analysis?tab=readme-ov-file.
SRIF: Semantic Shape Registration Empowered by Diffusion-based Image Morphing and Flow Estimation
Sep 18, 2024
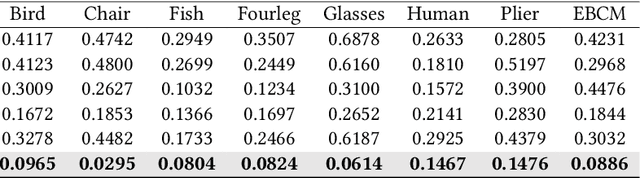
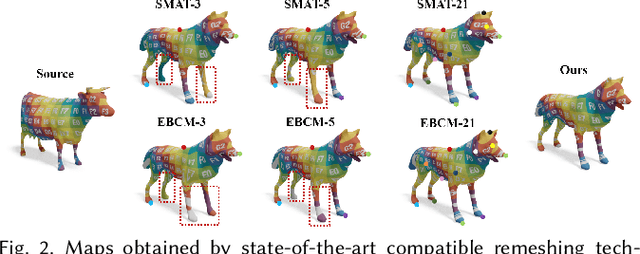
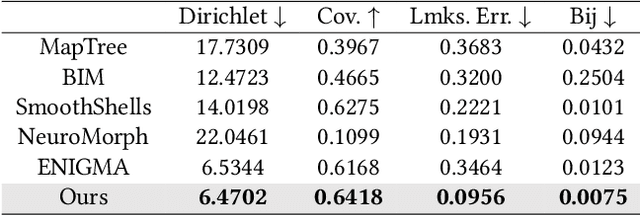
In this paper, we propose SRIF, a novel Semantic shape Registration framework based on diffusion-based Image morphing and Flow estimation. More concretely, given a pair of extrinsically aligned shapes, we first render them from multi-views, and then utilize an image interpolation framework based on diffusion models to generate sequences of intermediate images between them. The images are later fed into a dynamic 3D Gaussian splatting framework, with which we reconstruct and post-process for intermediate point clouds respecting the image morphing processing. In the end, tailored for the above, we propose a novel registration module to estimate continuous normalizing flow, which deforms source shape consistently towards the target, with intermediate point clouds as weak guidance. Our key insight is to leverage large vision models (LVMs) to associate shapes and therefore obtain much richer semantic information on the relationship between shapes than the ad-hoc feature extraction and alignment. As a consequence, SRIF achieves high-quality dense correspondences on challenging shape pairs, but also delivers smooth, semantically meaningful interpolation in between. Empirical evidence justifies the effectiveness and superiority of our method as well as specific design choices. The code is released at https://github.com/rqhuang88/SRIF.
MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild
Jun 03, 2024



We present MultiPly, a novel framework to reconstruct multiple people in 3D from monocular in-the-wild videos. Reconstructing multiple individuals moving and interacting naturally from monocular in-the-wild videos poses a challenging task. Addressing it necessitates precise pixel-level disentanglement of individuals without any prior knowledge about the subjects. Moreover, it requires recovering intricate and complete 3D human shapes from short video sequences, intensifying the level of difficulty. To tackle these challenges, we first define a layered neural representation for the entire scene, composited by individual human and background models. We learn the layered neural representation from videos via our layer-wise differentiable volume rendering. This learning process is further enhanced by our hybrid instance segmentation approach which combines the self-supervised 3D segmentation and the promptable 2D segmentation module, yielding reliable instance segmentation supervision even under close human interaction. A confidence-guided optimization formulation is introduced to optimize the human poses and shape/appearance alternately. We incorporate effective objectives to refine human poses via photometric information and impose physically plausible constraints on human dynamics, leading to temporally consistent 3D reconstructions with high fidelity. The evaluation of our method shows the superiority over prior art on publicly available datasets and in-the-wild videos.
4D-DRESS: A 4D Dataset of Real-world Human Clothing with Semantic Annotations
Apr 29, 2024



The studies of human clothing for digital avatars have predominantly relied on synthetic datasets. While easy to collect, synthetic data often fall short in realism and fail to capture authentic clothing dynamics. Addressing this gap, we introduce 4D-DRESS, the first real-world 4D dataset advancing human clothing research with its high-quality 4D textured scans and garment meshes. 4D-DRESS captures 64 outfits in 520 human motion sequences, amounting to 78k textured scans. Creating a real-world clothing dataset is challenging, particularly in annotating and segmenting the extensive and complex 4D human scans. To address this, we develop a semi-automatic 4D human parsing pipeline. We efficiently combine a human-in-the-loop process with automation to accurately label 4D scans in diverse garments and body movements. Leveraging precise annotations and high-quality garment meshes, we establish several benchmarks for clothing simulation and reconstruction. 4D-DRESS offers realistic and challenging data that complements synthetic sources, paving the way for advancements in research of lifelike human clothing. Website: https://ait.ethz.ch/4d-dress.
EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild
Aug 31, 2023


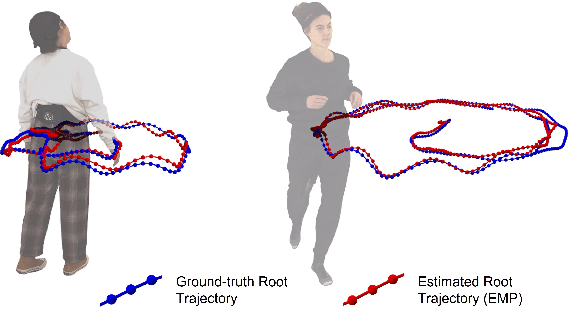
We present EMDB, the Electromagnetic Database of Global 3D Human Pose and Shape in the Wild. EMDB is a novel dataset that contains high-quality 3D SMPL pose and shape parameters with global body and camera trajectories for in-the-wild videos. We use body-worn, wireless electromagnetic (EM) sensors and a hand-held iPhone to record a total of 58 minutes of motion data, distributed over 81 indoor and outdoor sequences and 10 participants. Together with accurate body poses and shapes, we also provide global camera poses and body root trajectories. To construct EMDB, we propose a multi-stage optimization procedure, which first fits SMPL to the 6-DoF EM measurements and then refines the poses via image observations. To achieve high-quality results, we leverage a neural implicit avatar model to reconstruct detailed human surface geometry and appearance, which allows for improved alignment and smoothness via a dense pixel-level objective. Our evaluations, conducted with a multi-view volumetric capture system, indicate that EMDB has an expected accuracy of 2.3 cm positional and 10.6 degrees angular error, surpassing the accuracy of previous in-the-wild datasets. We evaluate existing state-of-the-art monocular RGB methods for camera-relative and global pose estimation on EMDB. EMDB is publicly available under https://ait.ethz.ch/emdb