 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D-DRESS: A 4D Dataset of Real-world Human Clothing with Semantic Annotations
Apr 29, 2024



The studies of human clothing for digital avatars have predominantly relied on synthetic datasets. While easy to collect, synthetic data often fall short in realism and fail to capture authentic clothing dynamics. Addressing this gap, we introduce 4D-DRESS, the first real-world 4D dataset advancing human clothing research with its high-quality 4D textured scans and garment meshes. 4D-DRESS captures 64 outfits in 520 human motion sequences, amounting to 78k textured scans. Creating a real-world clothing dataset is challenging, particularly in annotating and segmenting the extensive and complex 4D human scans. To address this, we develop a semi-automatic 4D human parsing pipeline. We efficiently combine a human-in-the-loop process with automation to accurately label 4D scans in diverse garments and body movements. Leveraging precise annotations and high-quality garment meshes, we establish several benchmarks for clothing simulation and reconstruction. 4D-DRESS offers realistic and challenging data that complements synthetic sources, paving the way for advancements in research of lifelike human clothing. Website: https://ait.ethz.ch/4d-dress.
Hi4D: 4D Instance Segmentation of Close Human Interaction
Mar 27, 2023
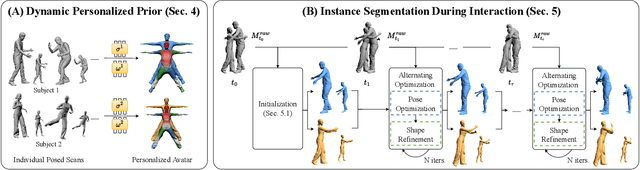
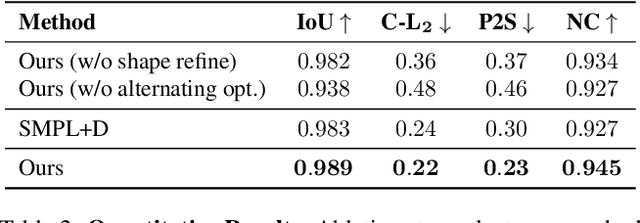
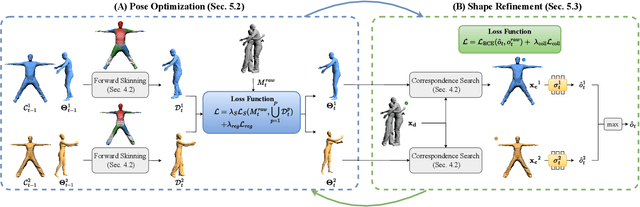
We propose Hi4D, a method and dataset for the automatic analysis of physically close human-human interaction under prolonged contact. Robustly disentangling several in-contact subjects is a challenging task due to occlusions and complex shapes. Hence, existing multi-view systems typically fuse 3D surfaces of close subjects into a single, connected mesh. To address this issue we leverage i) individually fitted neural implicit avatars; ii) an alternating optimization scheme that refines pose and surface through periods of close proximity; and iii) thus segment the fused raw scans into individual instances. From these instances we compile Hi4D dataset of 4D textured scans of 20 subject pairs, 100 sequences, and a total of more than 11K frames. Hi4D contains rich interaction-centric annotations in 2D and 3D alongside accurately registered parametric body models. We define varied human pose and shape estimation tasks on this dataset and provide results from state-of-the-art methods on these benchmarks.
X-Avatar: Expressive Human Avatars
Mar 09, 2023



We present X-Avatar, a novel avatar model that captures the full expressiveness of digital humans to bring about life-like experiences in telepresence, AR/VR and beyond. Our method models bodies, hands, facial expressions and appearance in a holistic fashion and can be learned from either full 3D scans or RGB-D data. To achieve this, we propose a part-aware learned forward skinning module that can be driven by the parameter space of SMPL-X, allowing for expressive animation of X-Avatars. To efficiently learn the neural shape and deformation fields, we propose novel part-aware sampling and initialization strategies. This leads to higher fidelity results, especially for smaller body parts while maintaining efficient training despite increased number of articulated bones. To capture the appearance of the avatar with high-frequency details, we extend the geometry and deformation fields with a texture network that is conditioned on pose, facial expression, geometry and the normals of the deformed surface. We show experimentally that our method outperforms strong baselines in both data domains both quantitatively and qualitatively on the animation task. To facilitate future research on expressive avatars we contribute a new dataset, called X-Humans, containing 233 sequences of high-quality textured scans from 20 participants, totalling 35,500 data frames.