 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Wardrobe: Compositional 3D Gaussian Avatars for Free-Form Virtual Try-On
Mar 05, 2026We introduce Gaussian Wardrobe, a novel framework to digitalize compositional 3D neural avatars from multi-view videos. Existing methods for 3D neural avatars typically treat the human body and clothing as an inseparable entity. However, this paradigm fails to capture the dynamics of complex free-form garments and limits the reuse of clothing across different individuals. To overcome these problems, we develop a novel, compositional 3D Gaussian representation to build avatars from multiple layers of free-form garments. The core of our method is decomposing neural avatars into bodies and layers of shape-agnostic neural garments. To achieve this, our framework learns to disentangle each garment layer from multi-view videos and canonicalizes it into a shape-independent space. In experiments, our method models photorealistic avatars with high-fidelity dynamics, achieving new state-of-the-art performance on novel pose synthesis benchmarks. In addition, we demonstrate that the learned compositional garments contribute to a versatile digital wardrobe, enabling a practical virtual try-on application where clothing can be freely transferred to new subjects. Project page: https://ait.ethz.ch/gaussianwardrobe
4D-DRESS: A 4D Dataset of Real-world Human Clothing with Semantic Annotations
Apr 29, 2024



The studies of human clothing for digital avatars have predominantly relied on synthetic datasets. While easy to collect, synthetic data often fall short in realism and fail to capture authentic clothing dynamics. Addressing this gap, we introduce 4D-DRESS, the first real-world 4D dataset advancing human clothing research with its high-quality 4D textured scans and garment meshes. 4D-DRESS captures 64 outfits in 520 human motion sequences, amounting to 78k textured scans. Creating a real-world clothing dataset is challenging, particularly in annotating and segmenting the extensive and complex 4D human scans. To address this, we develop a semi-automatic 4D human parsing pipeline. We efficiently combine a human-in-the-loop process with automation to accurately label 4D scans in diverse garments and body movements. Leveraging precise annotations and high-quality garment meshes, we establish several benchmarks for clothing simulation and reconstruction. 4D-DRESS offers realistic and challenging data that complements synthetic sources, paving the way for advancements in research of lifelike human clothing. Website: https://ait.ethz.ch/4d-dress.
SiTH: Single-view Textured Human Reconstruction with Image-Conditioned Diffusion
Nov 27, 2023A long-standing goal of 3D human reconstruction is to create lifelike and fully detailed 3D humans from single images. The main challenge lies in inferring unknown human shapes, clothing, and texture information in areas not visible in the images. To address this, we propose SiTH, a novel pipeline that uniquely integrates an image-conditioned diffusion model into a 3D mesh reconstruction workflow. At the core of our method lies the decomposition of the ill-posed single-view reconstruction problem into hallucination and reconstruction subproblems. For the former, we employ a powerful generative diffusion model to hallucinate back appearances from the input images. For the latter, we leverage skinned body meshes as guidance to recover full-body texture meshes from the input and back-view images. Our designs enable training of the pipeline with only about 500 3D human scans while maintaining its generality and robustness. Extensive experiments and user studies on two 3D reconstruction benchmarks demonstrated the efficacy of our method in generating realistic, fully textured 3D humans from a diverse range of unseen images.
Learning Locally Editable Virtual Humans
Apr 28, 2023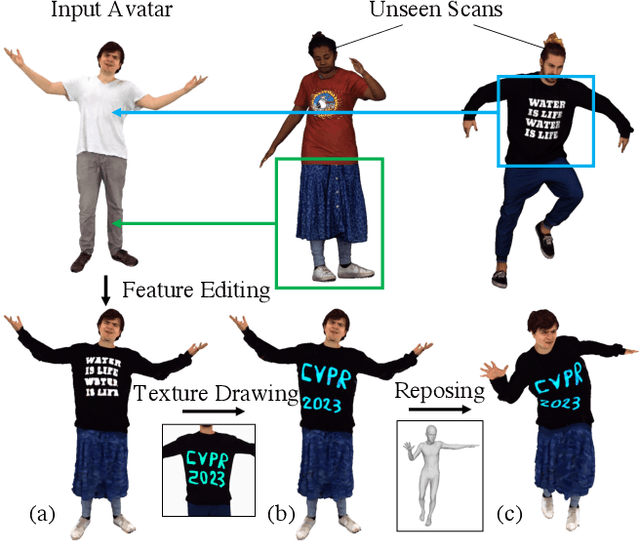
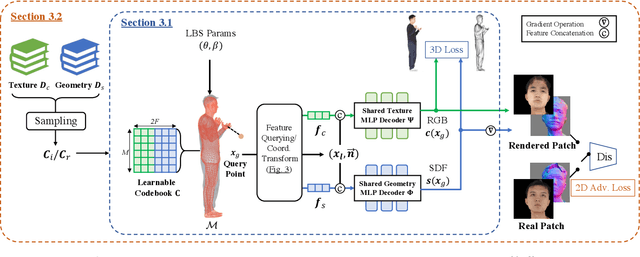
In this paper, we propose a novel hybrid representation and end-to-end trainable network architecture to model fully editable and customizable neural avatars. At the core of our work lies a representation that combines the modeling power of neural fields with the ease of use and inherent 3D consistency of skinned meshes. To this end, we construct a trainable feature codebook to store local geometry and texture features on the vertices of a deformable body model, thus exploiting its consistent topology under articulation. This representation is then employed in a generative auto-decoder architecture that admits fitting to unseen scans and sampling of realistic avatars with varied appearances and geometries. Furthermore, our representation allows local editing by swapping local features between 3D assets. To verify our method for avatar creation and editing, we contribute a new high-quality dataset, dubbed CustomHumans, for training and evaluation. Our experiments quantitatively and qualitatively show that our method generates diverse detailed avatars and achieves better model fitting performance compared to state-of-the-art methods. Our code and dataset are available at https://custom-humans.github.io/.
Render In-between: Motion Guided Video Synthesis for Action Interpolation
Nov 01, 2021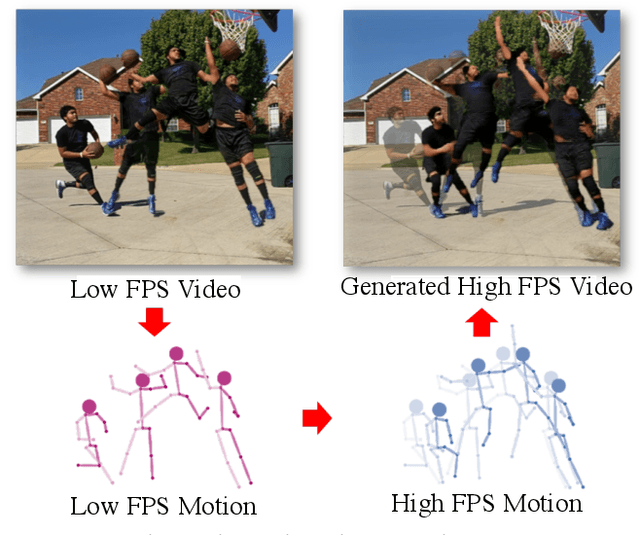
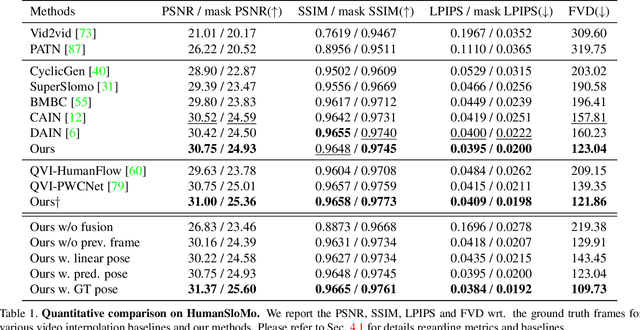
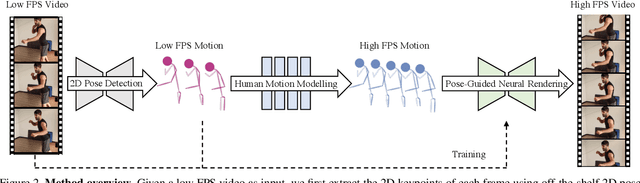
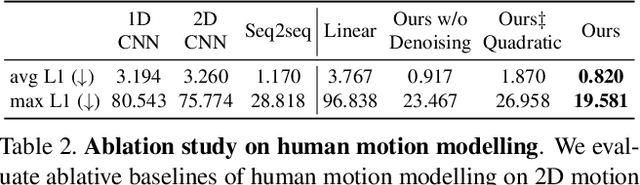
Upsampling videos of human activity is an interesting yet challenging task with many potential applications ranging from gaming to entertainment and sports broadcasting. The main difficulty in synthesizing video frames in this setting stems from the highly complex and non-linear nature of human motion and the complex appearance and texture of the body. We propose to address these issues in a motion-guided frame-upsampling framework that is capable of producing realistic human motion and appearance. A novel motion model is trained to inference the non-linear skeletal motion between frames by leveraging a large-scale motion-capture dataset (AMASS). The high-frame-rate pose predictions are then used by a neural rendering pipeline to produce the full-frame output, taking the pose and background consistency into consideration. Our pipeline only requires low-frame-rate videos and unpaired human motion data but does not require high-frame-rate videos for training. Furthermore, we contribute the first evaluation dataset that consists of high-quality and high-frame-rate videos of human activities for this task. Compared with state-of-the-art video interpolation techniques, our method produces in-between frames with better quality and accuracy, which is evident by state-of-the-art results on pixel-level, distributional metrics and comparative user evaluations. Our code and the collected dataset are available at https://git.io/Render-In-Between.
Summarizing First-Person Videos from Third Persons' Points of Views
Jul 26, 2018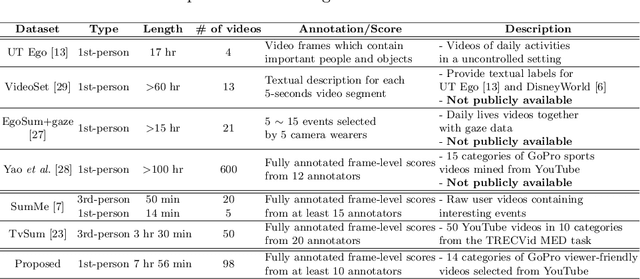
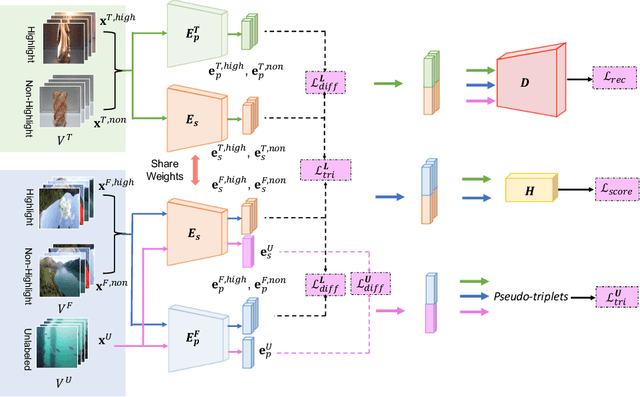
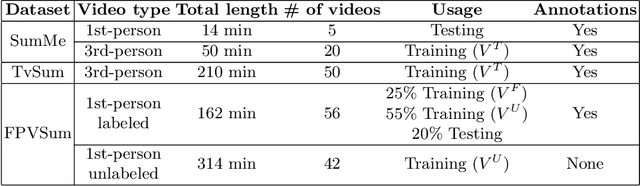
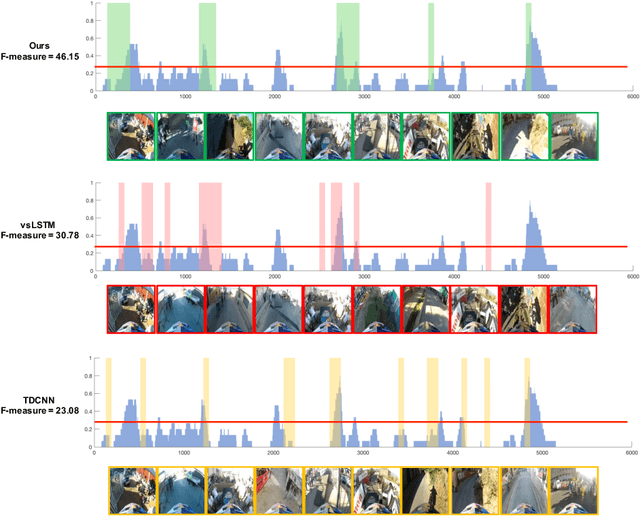
Video highlight or summarization is among interesting topics in computer vision, which benefits a variety of applications like viewing, searching, or storage. However, most existing studies rely on training data of third-person videos, which cannot easily generalize to highlight the first-person ones. With the goal of deriving an effective model to summarize first-person videos, we propose a novel deep neural network architecture for describing and discriminating vital spatiotemporal information across videos with different points of view. Our proposed model is realized in a semi-supervised setting, in which fully annotated third-person videos, unlabeled first-person videos, and a small number of annotated first-person ones are presented during training. In our experiments, qualitative and quantitative evaluations on both benchmarks and our collected first-person video datasets are presented.