 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRender In-between: Motion Guided Video Synthesis for Action Interpolation
Paper and Code
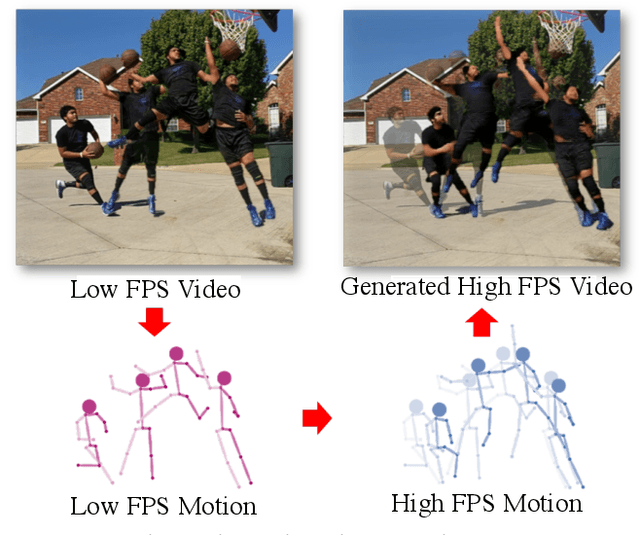
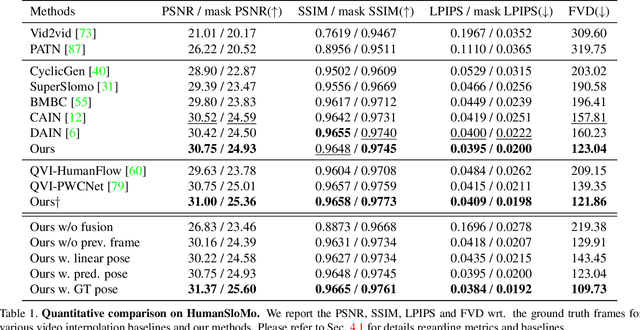
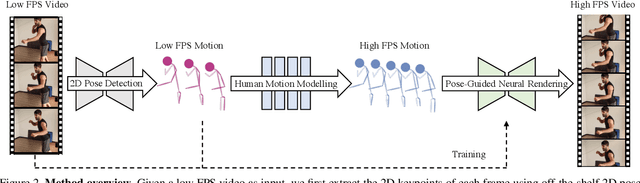
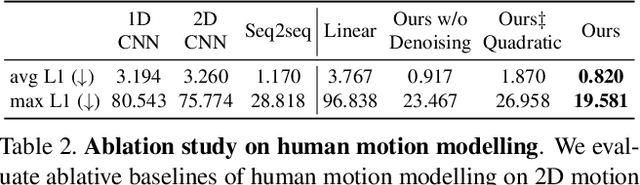
Upsampling videos of human activity is an interesting yet challenging task with many potential applications ranging from gaming to entertainment and sports broadcasting. The main difficulty in synthesizing video frames in this setting stems from the highly complex and non-linear nature of human motion and the complex appearance and texture of the body. We propose to address these issues in a motion-guided frame-upsampling framework that is capable of producing realistic human motion and appearance. A novel motion model is trained to inference the non-linear skeletal motion between frames by leveraging a large-scale motion-capture dataset (AMASS). The high-frame-rate pose predictions are then used by a neural rendering pipeline to produce the full-frame output, taking the pose and background consistency into consideration. Our pipeline only requires low-frame-rate videos and unpaired human motion data but does not require high-frame-rate videos for training. Furthermore, we contribute the first evaluation dataset that consists of high-quality and high-frame-rate videos of human activities for this task. Compared with state-of-the-art video interpolation techniques, our method produces in-between frames with better quality and accuracy, which is evident by state-of-the-art results on pixel-level, distributional metrics and comparative user evaluations. Our code and the collected dataset are available at https://git.io/Render-In-Between.