 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarizing First-Person Videos from Third Persons' Points of Views
Paper and Code
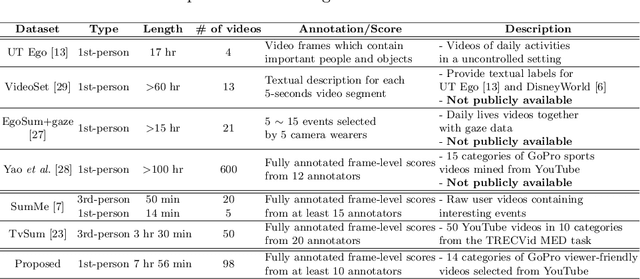
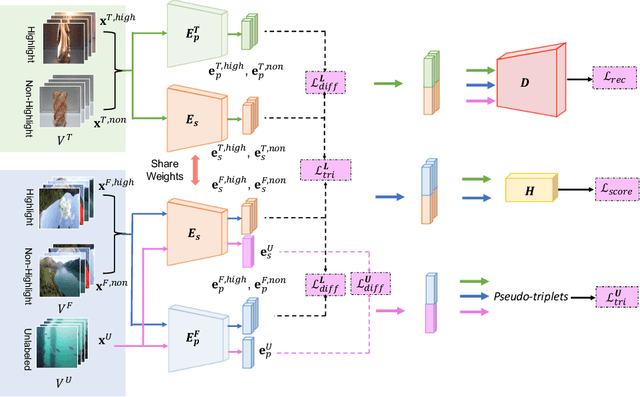
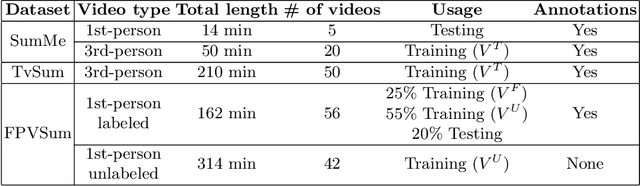
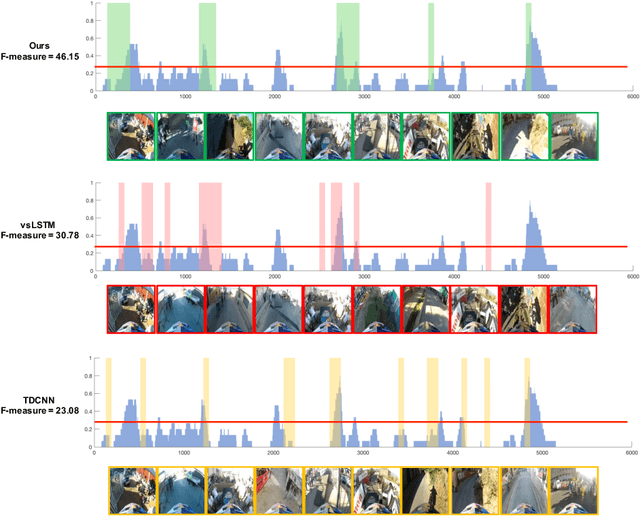
Video highlight or summarization is among interesting topics in computer vision, which benefits a variety of applications like viewing, searching, or storage. However, most existing studies rely on training data of third-person videos, which cannot easily generalize to highlight the first-person ones. With the goal of deriving an effective model to summarize first-person videos, we propose a novel deep neural network architecture for describing and discriminating vital spatiotemporal information across videos with different points of view. Our proposed model is realized in a semi-supervised setting, in which fully annotated third-person videos, unlabeled first-person videos, and a small number of annotated first-person ones are presented during training. In our experiments, qualitative and quantitative evaluations on both benchmarks and our collected first-person video datasets are presented.