 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild
Aug 31, 2023


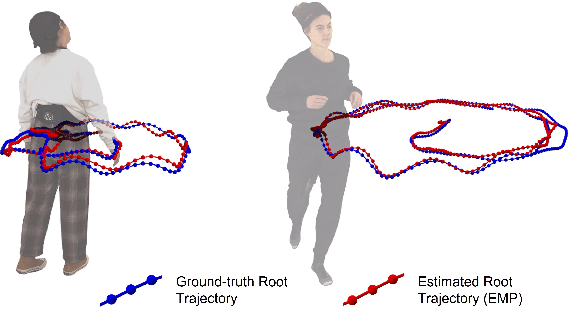
We present EMDB, the Electromagnetic Database of Global 3D Human Pose and Shape in the Wild. EMDB is a novel dataset that contains high-quality 3D SMPL pose and shape parameters with global body and camera trajectories for in-the-wild videos. We use body-worn, wireless electromagnetic (EM) sensors and a hand-held iPhone to record a total of 58 minutes of motion data, distributed over 81 indoor and outdoor sequences and 10 participants. Together with accurate body poses and shapes, we also provide global camera poses and body root trajectories. To construct EMDB, we propose a multi-stage optimization procedure, which first fits SMPL to the 6-DoF EM measurements and then refines the poses via image observations. To achieve high-quality results, we leverage a neural implicit avatar model to reconstruct detailed human surface geometry and appearance, which allows for improved alignment and smoothness via a dense pixel-level objective. Our evaluations, conducted with a multi-view volumetric capture system, indicate that EMDB has an expected accuracy of 2.3 cm positional and 10.6 degrees angular error, surpassing the accuracy of previous in-the-wild datasets. We evaluate existing state-of-the-art monocular RGB methods for camera-relative and global pose estimation on EMDB. EMDB is publicly available under https://ait.ethz.ch/emdb
X-Avatar: Expressive Human Avatars
Mar 09, 2023We present X-Avatar, a novel avatar model that captures the full expressiveness of digital humans to bring about life-like experiences in telepresence, AR/VR and beyond. Our method models bodies, hands, facial expressions and appearance in a holistic fashion and can be learned from either full 3D scans or RGB-D data. To achieve this, we propose a part-aware learned forward skinning module that can be driven by the parameter space of SMPL-X, allowing for expressive animation of X-Avatars. To efficiently learn the neural shape and deformation fields, we propose novel part-aware sampling and initialization strategies. This leads to higher fidelity results, especially for smaller body parts while maintaining efficient training despite increased number of articulated bones. To capture the appearance of the avatar with high-frequency details, we extend the geometry and deformation fields with a texture network that is conditioned on pose, facial expression, geometry and the normals of the deformed surface. We show experimentally that our method outperforms strong baselines in both data domains both quantitatively and qualitatively on the animation task. To facilitate future research on expressive avatars we contribute a new dataset, called X-Humans, containing 233 sequences of high-quality textured scans from 20 participants, totalling 35,500 data frames.