 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Wardrobe: Compositional 3D Gaussian Avatars for Free-Form Virtual Try-On
Mar 05, 2026We introduce Gaussian Wardrobe, a novel framework to digitalize compositional 3D neural avatars from multi-view videos. Existing methods for 3D neural avatars typically treat the human body and clothing as an inseparable entity. However, this paradigm fails to capture the dynamics of complex free-form garments and limits the reuse of clothing across different individuals. To overcome these problems, we develop a novel, compositional 3D Gaussian representation to build avatars from multiple layers of free-form garments. The core of our method is decomposing neural avatars into bodies and layers of shape-agnostic neural garments. To achieve this, our framework learns to disentangle each garment layer from multi-view videos and canonicalizes it into a shape-independent space. In experiments, our method models photorealistic avatars with high-fidelity dynamics, achieving new state-of-the-art performance on novel pose synthesis benchmarks. In addition, we demonstrate that the learned compositional garments contribute to a versatile digital wardrobe, enabling a practical virtual try-on application where clothing can be freely transferred to new subjects. Project page: https://ait.ethz.ch/gaussianwardrobe
WorldPose: A World Cup Dataset for Global 3D Human Pose Estimation
Jan 06, 2025We present WorldPose, a novel dataset for advancing research in multi-person global pose estimation in the wild, featuring footage from the 2022 FIFA World Cup. While previous datasets have primarily focused on local poses, often limited to a single person or in constrained, indoor settings, the infrastructure deployed for this sporting event allows access to multiple fixed and moving cameras in different stadiums. We exploit the static multi-view setup of HD cameras to recover the 3D player poses and motions with unprecedented accuracy given capture areas of more than 1.75 acres. We then leverage the captured players' motions and field markings to calibrate a moving broadcasting camera. The resulting dataset comprises more than 80 sequences with approx 2.5 million 3D poses and a total traveling distance of over 120 km. Subsequently, we conduct an in-depth analysis of the SOTA methods for global pose estimation. Our experiments demonstrate that WorldPose challenges existing multi-person techniques, supporting the potential for new research in this area and others, such as sports analysis. All pose annotations (in SMPL format), broadcasting camera parameters and footage will be released for academic research purposes.
MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild
Jun 03, 2024



We present MultiPly, a novel framework to reconstruct multiple people in 3D from monocular in-the-wild videos. Reconstructing multiple individuals moving and interacting naturally from monocular in-the-wild videos poses a challenging task. Addressing it necessitates precise pixel-level disentanglement of individuals without any prior knowledge about the subjects. Moreover, it requires recovering intricate and complete 3D human shapes from short video sequences, intensifying the level of difficulty. To tackle these challenges, we first define a layered neural representation for the entire scene, composited by individual human and background models. We learn the layered neural representation from videos via our layer-wise differentiable volume rendering. This learning process is further enhanced by our hybrid instance segmentation approach which combines the self-supervised 3D segmentation and the promptable 2D segmentation module, yielding reliable instance segmentation supervision even under close human interaction. A confidence-guided optimization formulation is introduced to optimize the human poses and shape/appearance alternately. We incorporate effective objectives to refine human poses via photometric information and impose physically plausible constraints on human dynamics, leading to temporally consistent 3D reconstructions with high fidelity. The evaluation of our method shows the superiority over prior art on publicly available datasets and in-the-wild videos.
EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild
Aug 31, 2023


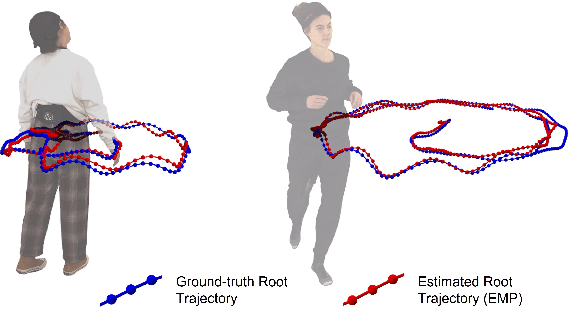
We present EMDB, the Electromagnetic Database of Global 3D Human Pose and Shape in the Wild. EMDB is a novel dataset that contains high-quality 3D SMPL pose and shape parameters with global body and camera trajectories for in-the-wild videos. We use body-worn, wireless electromagnetic (EM) sensors and a hand-held iPhone to record a total of 58 minutes of motion data, distributed over 81 indoor and outdoor sequences and 10 participants. Together with accurate body poses and shapes, we also provide global camera poses and body root trajectories. To construct EMDB, we propose a multi-stage optimization procedure, which first fits SMPL to the 6-DoF EM measurements and then refines the poses via image observations. To achieve high-quality results, we leverage a neural implicit avatar model to reconstruct detailed human surface geometry and appearance, which allows for improved alignment and smoothness via a dense pixel-level objective. Our evaluations, conducted with a multi-view volumetric capture system, indicate that EMDB has an expected accuracy of 2.3 cm positional and 10.6 degrees angular error, surpassing the accuracy of previous in-the-wild datasets. We evaluate existing state-of-the-art monocular RGB methods for camera-relative and global pose estimation on EMDB. EMDB is publicly available under https://ait.ethz.ch/emdb
Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition
Feb 22, 2023



We present Vid2Avatar, a method to learn human avatars from monocular in-the-wild videos. Reconstructing humans that move naturally from monocular in-the-wild videos is difficult. Solving it requires accurately separating humans from arbitrary backgrounds. Moreover, it requires reconstructing detailed 3D surface from short video sequences, making it even more challenging. Despite these challenges, our method does not require any groundtruth supervision or priors extracted from large datasets of clothed human scans, nor do we rely on any external segmentation modules. Instead, it solves the tasks of scene decomposition and surface reconstruction directly in 3D by modeling both the human and the background in the scene jointly, parameterized via two separate neural fields. Specifically, we define a temporally consistent human representation in canonical space and formulate a global optimization over the background model, the canonical human shape and texture, and per-frame human pose parameters. A coarse-to-fine sampling strategy for volume rendering and novel objectives are introduced for a clean separation of dynamic human and static background, yielding detailed and robust 3D human geometry reconstructions. We evaluate our methods on publicly available datasets and show improvements over prior art.
InstantAvatar: Learning Avatars from Monocular Video in 60 Seconds
Dec 20, 2022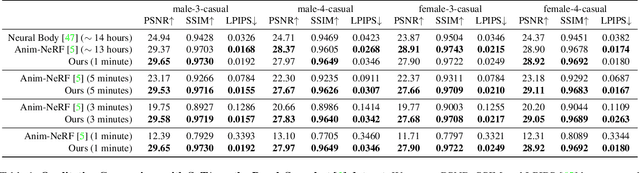
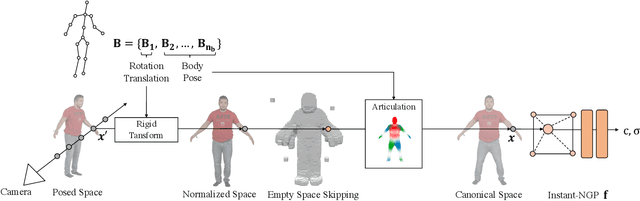
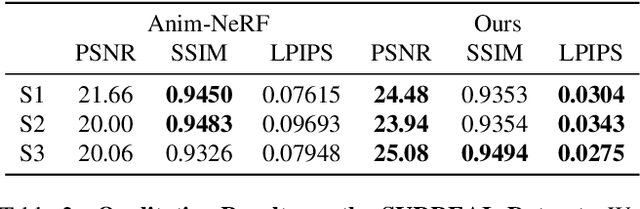
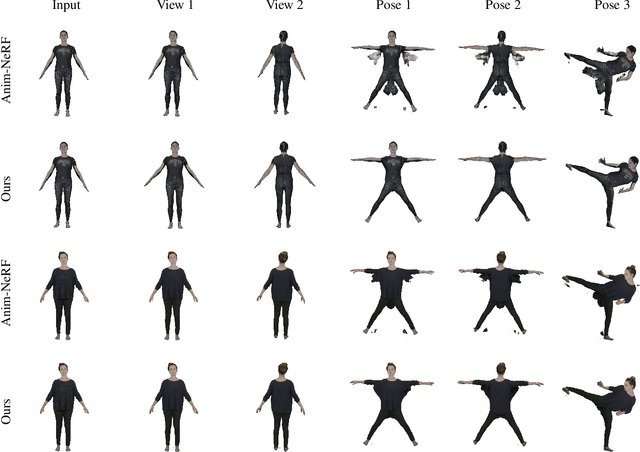
In this paper, we take a significant step towards real-world applicability of monocular neural avatar reconstruction by contributing InstantAvatar, a system that can reconstruct human avatars from a monocular video within seconds, and these avatars can be animated and rendered at an interactive rate. To achieve this efficiency we propose a carefully designed and engineered system, that leverages emerging acceleration structures for neural fields, in combination with an efficient empty space-skipping strategy for dynamic scenes. We also contribute an efficient implementation that we will make available for research purposes. Compared to existing methods, InstantAvatar converges 130x faster and can be trained in minutes instead of hours. It achieves comparable or even better reconstruction quality and novel pose synthesis results. When given the same time budget, our method significantly outperforms SoTA methods. InstantAvatar can yield acceptable visual quality in as little as 10 seconds training time.
Fast-SNARF: A Fast Deformer for Articulated Neural Fields
Dec 01, 2022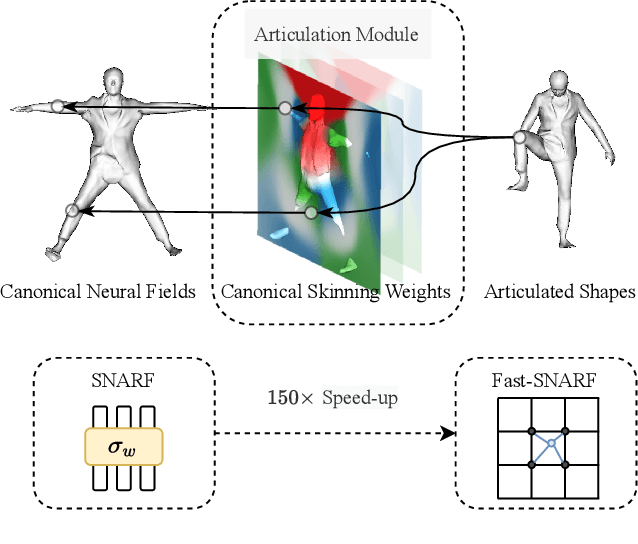

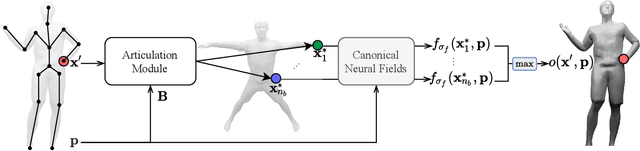
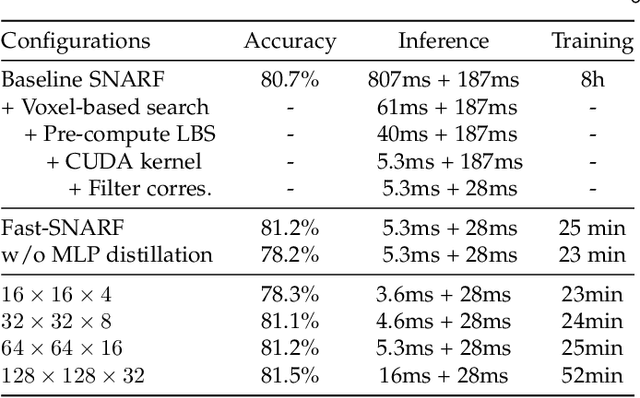
Neural fields have revolutionized the area of 3D reconstruction and novel view synthesis of rigid scenes. A key challenge in making such methods applicable to articulated objects, such as the human body, is to model the deformation of 3D locations between the rest pose (a canonical space) and the deformed space. We propose a new articulation module for neural fields, Fast-SNARF, which finds accurate correspondences between canonical space and posed space via iterative root finding. Fast-SNARF is a drop-in replacement in functionality to our previous work, SNARF, while significantly improving its computational efficiency. We contribute several algorithmic and implementation improvements over SNARF, yielding a speed-up of $150\times$. These improvements include voxel-based correspondence search, pre-computing the linear blend skinning function, and an efficient software implementation with CUDA kernels. Fast-SNARF enables efficient and simultaneous optimization of shape and skinning weights given deformed observations without correspondences (e.g. 3D meshes). Because learning of deformation maps is a crucial component in many 3D human avatar methods and since Fast-SNARF provides a computationally efficient solution, we believe that this work represents a significant step towards the practical creation of 3D virtual humans.
gDNA: Towards Generative Detailed Neural Avatars
Jan 11, 2022
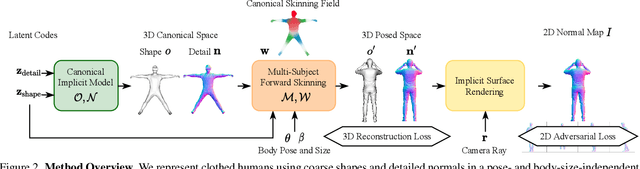


To make 3D human avatars widely available, we must be able to generate a variety of 3D virtual humans with varied identities and shapes in arbitrary poses. This task is challenging due to the diversity of clothed body shapes, their complex articulations, and the resulting rich, yet stochastic geometric detail in clothing. Hence, current methods to represent 3D people do not provide a full generative model of people in clothing. In this paper, we propose a novel method that learns to generate detailed 3D shapes of people in a variety of garments with corresponding skinning weights. Specifically, we devise a multi-subject forward skinning module that is learned from only a few posed, un-rigged scans per subject. To capture the stochastic nature of high-frequency details in garments, we leverage an adversarial loss formulation that encourages the model to capture the underlying statistics. We provide empirical evidence that this leads to realistic generation of local details such as wrinkles. We show that our model is able to generate natural human avatars wearing diverse and detailed clothing. Furthermore, we show that our method can be used on the task of fitting human models to raw scans, outperforming the previous state-of-the-art.