 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODHSR: Online Dense 3D Reconstruction of Humans and Scenes from Monocular Videos
Apr 18, 2025Creating a photorealistic scene and human reconstruction from a single monocular in-the-wild video figures prominently in the perception of a human-centric 3D world. Recent neural rendering advances have enabled holistic human-scene reconstruction but require pre-calibrated camera and human poses, and days of training time. In this work, we introduce a novel unified framework that simultaneously performs camera tracking, human pose estimation and human-scene reconstruction in an online fashion. 3D Gaussian Splatting is utilized to learn Gaussian primitives for humans and scenes efficiently, and reconstruction-based camera tracking and human pose estimation modules are designed to enable holistic understanding and effective disentanglement of pose and appearance. Specifically, we design a human deformation module to reconstruct the details and enhance generalizability to out-of-distribution poses faithfully. Aiming to learn the spatial correlation between human and scene accurately, we introduce occlusion-aware human silhouette rendering and monocular geometric priors, which further improve reconstruction quality. Experiments on the EMDB and NeuMan datasets demonstrate superior or on-par performance with existing methods in camera tracking, human pose estimation, novel view synthesis and runtime. Our project page is at https://eth-ait.github.io/ODHSR.
WorldPose: A World Cup Dataset for Global 3D Human Pose Estimation
Jan 06, 2025We present WorldPose, a novel dataset for advancing research in multi-person global pose estimation in the wild, featuring footage from the 2022 FIFA World Cup. While previous datasets have primarily focused on local poses, often limited to a single person or in constrained, indoor settings, the infrastructure deployed for this sporting event allows access to multiple fixed and moving cameras in different stadiums. We exploit the static multi-view setup of HD cameras to recover the 3D player poses and motions with unprecedented accuracy given capture areas of more than 1.75 acres. We then leverage the captured players' motions and field markings to calibrate a moving broadcasting camera. The resulting dataset comprises more than 80 sequences with approx 2.5 million 3D poses and a total traveling distance of over 120 km. Subsequently, we conduct an in-depth analysis of the SOTA methods for global pose estimation. Our experiments demonstrate that WorldPose challenges existing multi-person techniques, supporting the potential for new research in this area and others, such as sports analysis. All pose annotations (in SMPL format), broadcasting camera parameters and footage will be released for academic research purposes.
EgoHDM: An Online Egocentric-Inertial Human Motion Capture, Localization, and Dense Mapping System
Aug 31, 2024



We present EgoHDM, an online egocentric-inertial human motion capture (mocap), localization, and dense mapping system. Our system uses 6 inertial measurement units (IMUs) and a commodity head-mounted RGB camera. EgoHDM is the first human mocap system that offers dense scene mapping in near real-time. Further, it is fast and robust to initialize and fully closes the loop between physically plausible map-aware global human motion estimation and mocap-aware 3D scene reconstruction. Our key idea is integrating camera localization and mapping information with inertial human motion capture bidirectionally in our system. To achieve this, we design a tightly coupled mocap-aware dense bundle adjustment and physics-based body pose correction module leveraging a local body-centric elevation map. The latter introduces a novel terrain-aware contact PD controller, which enables characters to physically contact the given local elevation map thereby reducing human floating or penetration. We demonstrate the performance of our system on established synthetic and real-world benchmarks. The results show that our method reduces human localization, camera pose, and mapping accuracy error by 41%, 71%, 46%, respectively, compared to the state of the art. Our qualitative evaluations on newly captured data further demonstrate that EgoHDM can cover challenging scenarios in non-flat terrain including stepping over stairs and outdoor scenes in the wild.
MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild
Jun 03, 2024



We present MultiPly, a novel framework to reconstruct multiple people in 3D from monocular in-the-wild videos. Reconstructing multiple individuals moving and interacting naturally from monocular in-the-wild videos poses a challenging task. Addressing it necessitates precise pixel-level disentanglement of individuals without any prior knowledge about the subjects. Moreover, it requires recovering intricate and complete 3D human shapes from short video sequences, intensifying the level of difficulty. To tackle these challenges, we first define a layered neural representation for the entire scene, composited by individual human and background models. We learn the layered neural representation from videos via our layer-wise differentiable volume rendering. This learning process is further enhanced by our hybrid instance segmentation approach which combines the self-supervised 3D segmentation and the promptable 2D segmentation module, yielding reliable instance segmentation supervision even under close human interaction. A confidence-guided optimization formulation is introduced to optimize the human poses and shape/appearance alternately. We incorporate effective objectives to refine human poses via photometric information and impose physically plausible constraints on human dynamics, leading to temporally consistent 3D reconstructions with high fidelity. The evaluation of our method shows the superiority over prior art on publicly available datasets and in-the-wild videos.
EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild
Aug 31, 2023


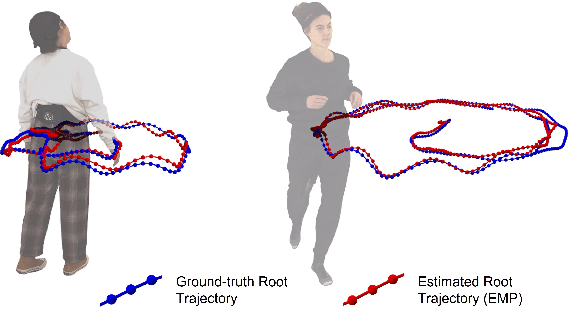
We present EMDB, the Electromagnetic Database of Global 3D Human Pose and Shape in the Wild. EMDB is a novel dataset that contains high-quality 3D SMPL pose and shape parameters with global body and camera trajectories for in-the-wild videos. We use body-worn, wireless electromagnetic (EM) sensors and a hand-held iPhone to record a total of 58 minutes of motion data, distributed over 81 indoor and outdoor sequences and 10 participants. Together with accurate body poses and shapes, we also provide global camera poses and body root trajectories. To construct EMDB, we propose a multi-stage optimization procedure, which first fits SMPL to the 6-DoF EM measurements and then refines the poses via image observations. To achieve high-quality results, we leverage a neural implicit avatar model to reconstruct detailed human surface geometry and appearance, which allows for improved alignment and smoothness via a dense pixel-level objective. Our evaluations, conducted with a multi-view volumetric capture system, indicate that EMDB has an expected accuracy of 2.3 cm positional and 10.6 degrees angular error, surpassing the accuracy of previous in-the-wild datasets. We evaluate existing state-of-the-art monocular RGB methods for camera-relative and global pose estimation on EMDB. EMDB is publicly available under https://ait.ethz.ch/emdb
An Interpretable and Attention-based Method for Gaze Estimation Using Electroencephalography
Aug 09, 2023Eye movements can reveal valuable insights into various aspects of human mental processes, physical well-being, and actions. Recently, several datasets have been made available that simultaneously record EEG activity and eye movements. This has triggered the development of various methods to predict gaze direction based on brain activity. However, most of these methods lack interpretability, which limits their technology acceptance. In this paper, we leverage a large data set of simultaneously measured Electroencephalography (EEG) and Eye tracking, proposing an interpretable model for gaze estimation from EEG data. More specifically, we present a novel attention-based deep learning framework for EEG signal analysis, which allows the network to focus on the most relevant information in the signal and discard problematic channels. Additionally, we provide a comprehensive evaluation of the presented framework, demonstrating its superiority over current methods in terms of accuracy and robustness. Finally, the study presents visualizations that explain the results of the analysis and highlights the potential of attention mechanism for improving the efficiency and effectiveness of EEG data analysis in a variety of applications.
Hi4D: 4D Instance Segmentation of Close Human Interaction
Mar 27, 2023
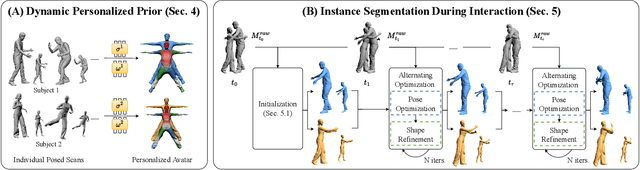
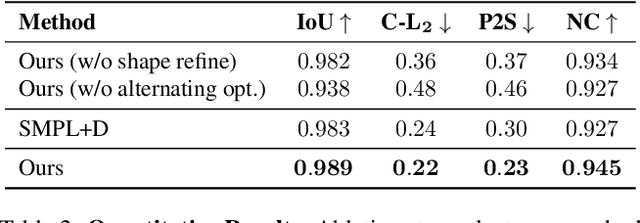
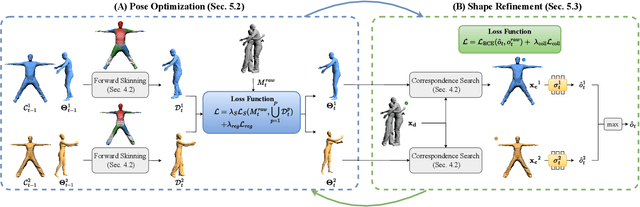
We propose Hi4D, a method and dataset for the automatic analysis of physically close human-human interaction under prolonged contact. Robustly disentangling several in-contact subjects is a challenging task due to occlusions and complex shapes. Hence, existing multi-view systems typically fuse 3D surfaces of close subjects into a single, connected mesh. To address this issue we leverage i) individually fitted neural implicit avatars; ii) an alternating optimization scheme that refines pose and surface through periods of close proximity; and iii) thus segment the fused raw scans into individual instances. From these instances we compile Hi4D dataset of 4D textured scans of 20 subject pairs, 100 sequences, and a total of more than 11K frames. Hi4D contains rich interaction-centric annotations in 2D and 3D alongside accurately registered parametric body models. We define varied human pose and shape estimation tasks on this dataset and provide results from state-of-the-art methods on these benchmarks.
X-Avatar: Expressive Human Avatars
Mar 09, 2023We present X-Avatar, a novel avatar model that captures the full expressiveness of digital humans to bring about life-like experiences in telepresence, AR/VR and beyond. Our method models bodies, hands, facial expressions and appearance in a holistic fashion and can be learned from either full 3D scans or RGB-D data. To achieve this, we propose a part-aware learned forward skinning module that can be driven by the parameter space of SMPL-X, allowing for expressive animation of X-Avatars. To efficiently learn the neural shape and deformation fields, we propose novel part-aware sampling and initialization strategies. This leads to higher fidelity results, especially for smaller body parts while maintaining efficient training despite increased number of articulated bones. To capture the appearance of the avatar with high-frequency details, we extend the geometry and deformation fields with a texture network that is conditioned on pose, facial expression, geometry and the normals of the deformed surface. We show experimentally that our method outperforms strong baselines in both data domains both quantitatively and qualitatively on the animation task. To facilitate future research on expressive avatars we contribute a new dataset, called X-Humans, containing 233 sequences of high-quality textured scans from 20 participants, totalling 35,500 data frames.
Articulated Objects in Free-form Hand Interaction
Apr 28, 2022



We use our hands to interact with and to manipulate objects. Articulated objects are especially interesting since they often require the full dexterity of human hands to manipulate them. To understand, model, and synthesize such interactions, automatic and robust methods that reconstruct hands and articulated objects in 3D from a color image are needed. Existing methods for estimating 3D hand and object pose from images focus on rigid objects. In part, because such methods rely on training data and no dataset of articulated object manipulation exists. Consequently, we introduce ARCTIC - the first dataset of free-form interactions of hands and articulated objects. ARCTIC has 1.2M images paired with accurate 3D meshes for both hands and for objects that move and deform over time. The dataset also provides hand-object contact information. To show the value of our dataset, we perform two novel tasks on ARCTIC: (1) 3D reconstruction of two hands and an articulated object in interaction; (2) an estimation of dense hand-object relative distances, which we call interaction field estimation. For the first task, we present ArcticNet, a baseline method for the task of jointly reconstructing two hands and an articulated object from an RGB image. For interaction field estimation, we predict the relative distances from each hand vertex to the object surface, and vice versa. We introduce InterField, the first method that estimates such distances from a single RGB image. We provide qualitative and quantitative experiments for both tasks, and provide detailed analysis on the data. Code and data will be available at https://arctic.is.tue.mpg.de.
Convolutional Autoencoders for Human Motion Infilling
Oct 22, 2020
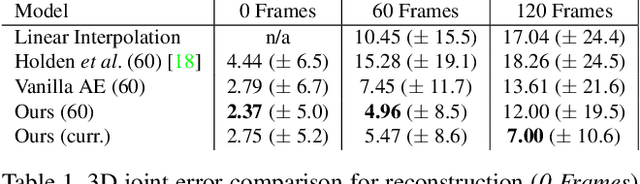
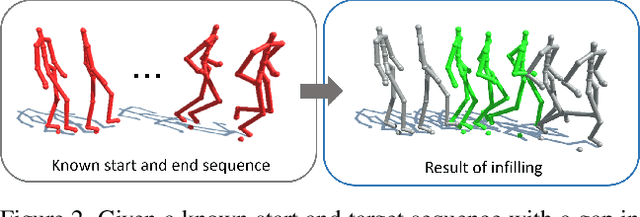
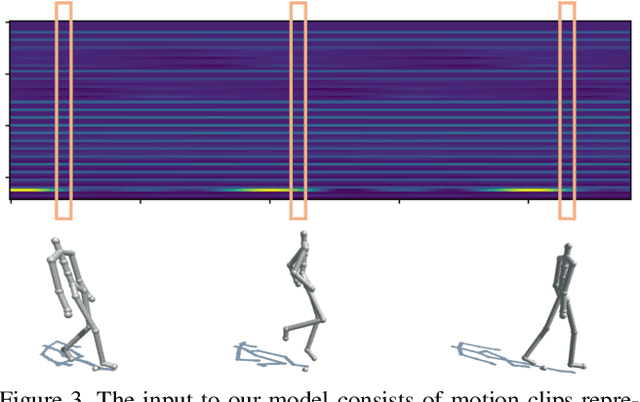
In this paper we propose a convolutional autoencoder to address the problem of motion infilling for 3D human motion data. Given a start and end sequence, motion infilling aims to complete the missing gap in between, such that the filled in poses plausibly forecast the start sequence and naturally transition into the end sequence. To this end, we propose a single, end-to-end trainable convolutional autoencoder. We show that a single model can be used to create natural transitions between different types of activities. Furthermore, our method is not only able to fill in entire missing frames, but it can also be used to complete gaps where partial poses are available (e.g. from end effectors), or to clean up other forms of noise (e.g. Gaussian). Also, the model can fill in an arbitrary number of gaps that potentially vary in length. In addition, no further post-processing on the model's outputs is necessary such as smoothing or closing discontinuities at the end of the gap. At the heart of our approach lies the idea to cast motion infilling as an inpainting problem and to train a convolutional de-noising autoencoder on image-like representations of motion sequences. At training time, blocks of columns are removed from such images and we ask the model to fill in the gaps. We demonstrate the versatility of the approach via a number of complex motion sequences and report on thorough evaluations performed to better understand the capabilities and limitations of the proposed approach.