 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Autoencoders for Human Motion Infilling
Oct 22, 2020
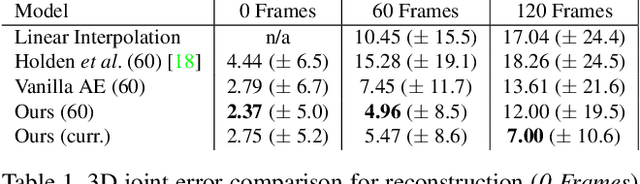
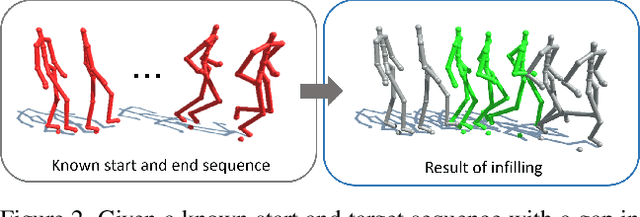
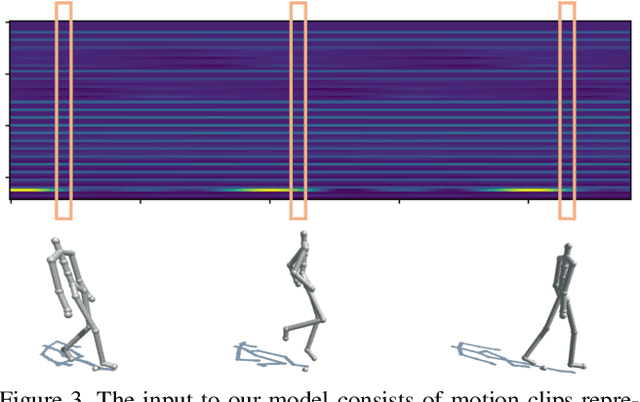
In this paper we propose a convolutional autoencoder to address the problem of motion infilling for 3D human motion data. Given a start and end sequence, motion infilling aims to complete the missing gap in between, such that the filled in poses plausibly forecast the start sequence and naturally transition into the end sequence. To this end, we propose a single, end-to-end trainable convolutional autoencoder. We show that a single model can be used to create natural transitions between different types of activities. Furthermore, our method is not only able to fill in entire missing frames, but it can also be used to complete gaps where partial poses are available (e.g. from end effectors), or to clean up other forms of noise (e.g. Gaussian). Also, the model can fill in an arbitrary number of gaps that potentially vary in length. In addition, no further post-processing on the model's outputs is necessary such as smoothing or closing discontinuities at the end of the gap. At the heart of our approach lies the idea to cast motion infilling as an inpainting problem and to train a convolutional de-noising autoencoder on image-like representations of motion sequences. At training time, blocks of columns are removed from such images and we ask the model to fill in the gaps. We demonstrate the versatility of the approach via a number of complex motion sequences and report on thorough evaluations performed to better understand the capabilities and limitations of the proposed approach.
DeepWriting: Making Digital Ink Editable via Deep Generative Modeling
Jan 25, 2018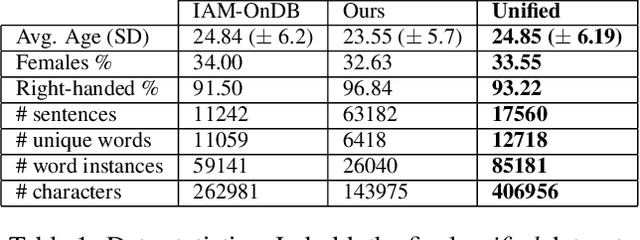
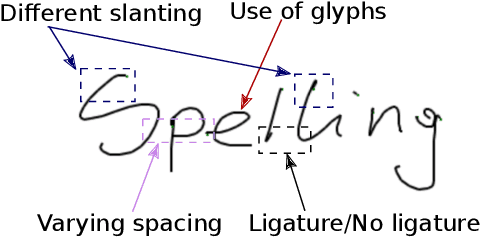
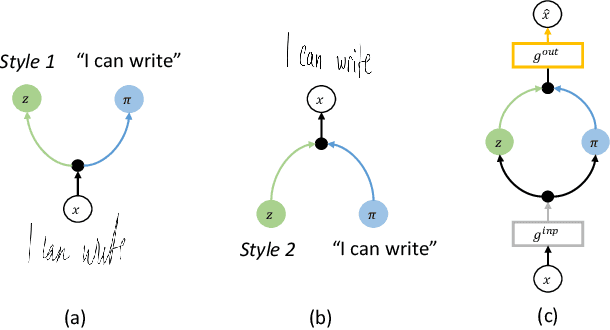

Digital ink promises to combine the flexibility and aesthetics of handwriting and the ability to process, search and edit digital text. Character recognition converts handwritten text into a digital representation, albeit at the cost of losing personalized appearance due to the technical difficulties of separating the interwoven components of content and style. In this paper, we propose a novel generative neural network architecture that is capable of disentangling style from content and thus making digital ink editable. Our model can synthesize arbitrary text, while giving users control over the visual appearance (style). For example, allowing for style transfer without changing the content, editing of digital ink at the word level and other application scenarios such as spell-checking and correction of handwritten text. We furthermore contribute a new dataset of handwritten text with fine-grained annotations at the character level and report results from an initial user evaluation.