 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldPose: A World Cup Dataset for Global 3D Human Pose Estimation
Jan 06, 2025We present WorldPose, a novel dataset for advancing research in multi-person global pose estimation in the wild, featuring footage from the 2022 FIFA World Cup. While previous datasets have primarily focused on local poses, often limited to a single person or in constrained, indoor settings, the infrastructure deployed for this sporting event allows access to multiple fixed and moving cameras in different stadiums. We exploit the static multi-view setup of HD cameras to recover the 3D player poses and motions with unprecedented accuracy given capture areas of more than 1.75 acres. We then leverage the captured players' motions and field markings to calibrate a moving broadcasting camera. The resulting dataset comprises more than 80 sequences with approx 2.5 million 3D poses and a total traveling distance of over 120 km. Subsequently, we conduct an in-depth analysis of the SOTA methods for global pose estimation. Our experiments demonstrate that WorldPose challenges existing multi-person techniques, supporting the potential for new research in this area and others, such as sports analysis. All pose annotations (in SMPL format), broadcasting camera parameters and footage will be released for academic research purposes.
Quantitative Analysis of Image Classification Techniques for Memory-Constrained Devices
May 11, 2020
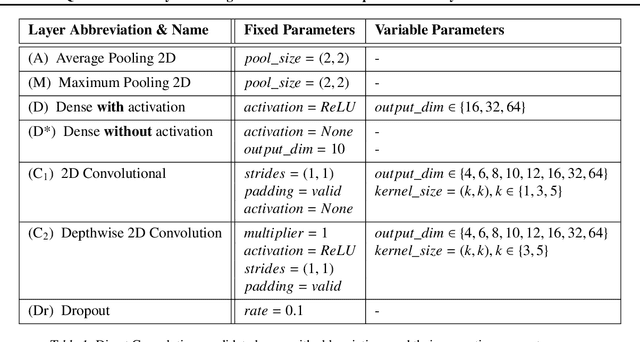
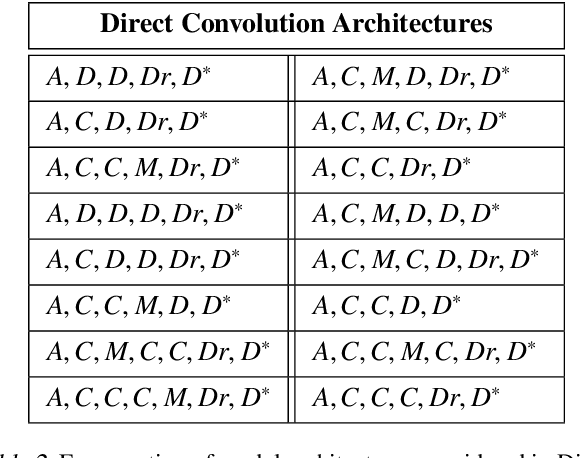
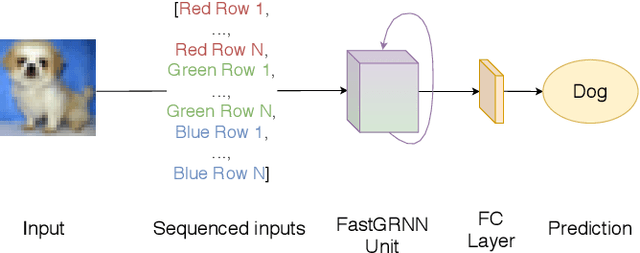
Convolutional Neural Networks, or CNNs, are undoubtedly the state of the art for image classification. However, they typically come with the cost of a large memory footprint. Recently, there has been significant progress in the field of image classification on memory-constrained devices, such as Arduino Unos, with novel contributions like the ProtoNN, Bonsai and FastGRNN models. These methods have been shown to perform excellently on tasks such as speech recognition or optical character recognition using MNIST, but their potential on more complex, multi-channel and multi-class image classification has yet to be determined. This paper presents a comprehensive analysis that shows that even in memory-constrained environments, CNNs implemented memory-optimally using Direct Convolutions outperform ProtoNN, Bonsai and FastGRNN models on 3-channel image classification using CIFAR-10. For our analysis, we propose new methods of adjusting the FastGRNN model to work with multi-channel images and then evaluate each algorithm with a memory size budget of 8KB, 16KB, 32KB, 64KB and 128KB to show quantitatively that CNNs are still state-of-the-art in image classification, even when memory size is constrained.