 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Pseudo-Labeling for Computer Vision
Aug 13, 2024Deep neural models have achieved state of the art performance on a wide range of problems in computer science, especially in computer vision. However, deep neural networks often require large datasets of labeled samples to generalize effectively, and an important area of active research is semi-supervised learning, which attempts to instead utilize large quantities of (easily acquired) unlabeled samples. One family of methods in this space is pseudo-labeling, a class of algorithms that use model outputs to assign labels to unlabeled samples which are then used as labeled samples during training. Such assigned labels, called pseudo-labels, are most commonly associated with the field of semi-supervised learning. In this work we explore a broader interpretation of pseudo-labels within both self-supervised and unsupervised methods. By drawing the connection between these areas we identify new directions when advancements in one area would likely benefit others, such as curriculum learning and self-supervised regularization.
Spherical Feature Pyramid Networks For Semantic Segmentation
Jul 05, 2023

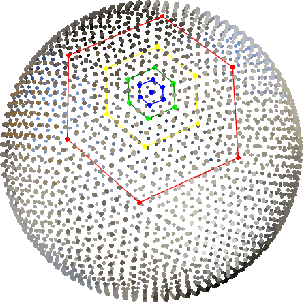

Semantic segmentation for spherical data is a challenging problem in machine learning since conventional planar approaches require projecting the spherical image to the Euclidean plane. Representing the signal on a fundamentally different topology introduces edges and distortions which impact network performance. Recently, graph-based approaches have bypassed these challenges to attain significant improvements by representing the signal on a spherical mesh. Current approaches to spherical segmentation exclusively use variants of the UNet architecture, meaning more successful planar architectures remain unexplored. Inspired by the success of feature pyramid networks (FPNs) in planar image segmentation, we leverage the pyramidal hierarchy of graph-based spherical CNNs to design spherical FPNs. Our spherical FPN models show consistent improvements over spherical UNets, whilst using fewer parameters. On the Stanford 2D-3D-S dataset, our models achieve state-of-the-art performance with an mIOU of 48.75, an improvement of 3.75 IoU points over the previous best spherical CNN.
Class Introspection: A Novel Technique for Detecting Unlabeled Subclasses by Leveraging Classifier Explainability Methods
Jul 04, 2021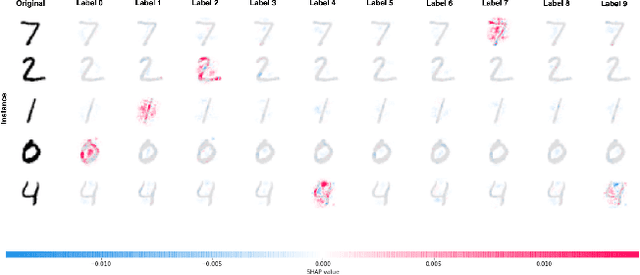

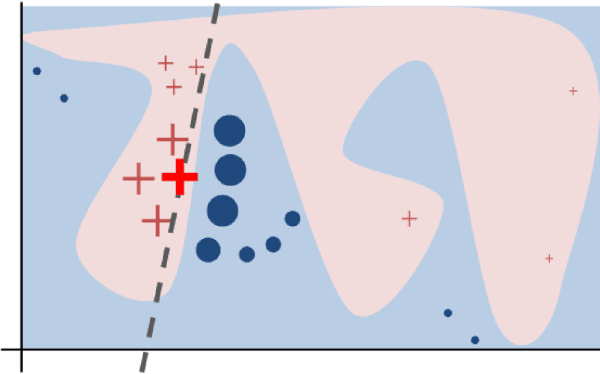

Detecting latent structure within a dataset is a crucial step in performing analysis of a dataset. However, existing state-of-the-art techniques for subclass discovery are limited: either they are limited to detecting very small numbers of outliers or they lack the statistical power to deal with complex data such as image or audio. This paper proposes a solution to this subclass discovery problem: by leveraging instance explanation methods, an existing classifier can be extended to detect latent classes via differences in the classifier's internal decisions about each instance. This works not only with simple classification techniques but also with deep neural networks, allowing for a powerful and flexible approach to detecting latent structure within datasets. Effectively, this represents a projection of the dataset into the classifier's "explanation space," and preliminary results show that this technique outperforms the baseline for the detection of latent classes even with limited processing. This paper also contains a pipeline for analyzing classifiers automatically, and a web application for interactively exploring the results from this technique.
Quantitative Analysis of Image Classification Techniques for Memory-Constrained Devices
May 11, 2020
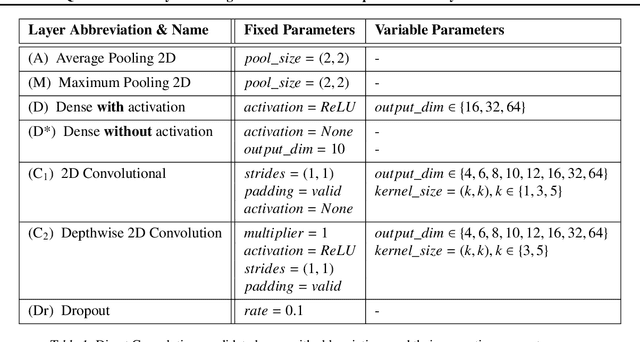
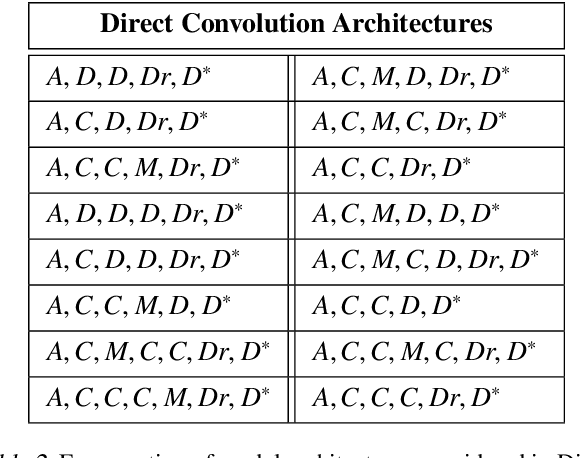
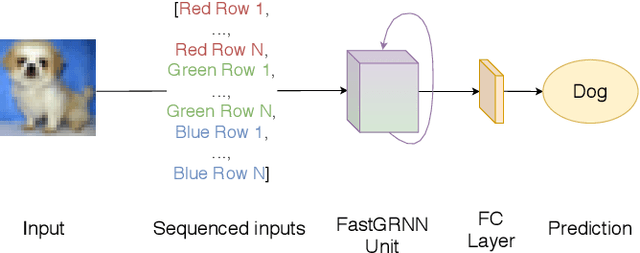
Convolutional Neural Networks, or CNNs, are undoubtedly the state of the art for image classification. However, they typically come with the cost of a large memory footprint. Recently, there has been significant progress in the field of image classification on memory-constrained devices, such as Arduino Unos, with novel contributions like the ProtoNN, Bonsai and FastGRNN models. These methods have been shown to perform excellently on tasks such as speech recognition or optical character recognition using MNIST, but their potential on more complex, multi-channel and multi-class image classification has yet to be determined. This paper presents a comprehensive analysis that shows that even in memory-constrained environments, CNNs implemented memory-optimally using Direct Convolutions outperform ProtoNN, Bonsai and FastGRNN models on 3-channel image classification using CIFAR-10. For our analysis, we propose new methods of adjusting the FastGRNN model to work with multi-channel images and then evaluate each algorithm with a memory size budget of 8KB, 16KB, 32KB, 64KB and 128KB to show quantitatively that CNNs are still state-of-the-art in image classification, even when memory size is constrained.