 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Driven Semantic Scattering Structure Understanding of Aircraft Target in SAR Images
Jun 05, 2026Synthetic aperture radar (SAR) has become indispensable for target interpretation owing to its all-day and all-weather observation capability. In SAR target interpretation, electromagnetic scattering information provides a physically grounded cue beyond visual texture and has been widely exploited for target interpretation. However, existing methods remain dominated by local scattering center representations. Such unordered and component-agnostic representations are highly unstable for aircraft targets. As a result, physically existing components with weak scattering responses are often missed, resulting in the incomplete reconstructed topology structure. To address this limitation, we establish Semantic Scattering Structure Understanding as a new paradigm for SAR aircraft interpretation. Semantic scattering keypoints are defined to associate local electromagnetic responses with physically meaningful aircraft components, while visibility-aware attributes are introduced to retain weakly observable yet physically existed components. The keypoints are further organized into a stable semantic scattering structure. Build upon this, we propose S3U-SAR, a physics-driven framework to localize semantic scattering keypoints and construct the complete representation constrained by multi-dimensional physical priors containing scattering heterogeneity, rigid-body topology, speckle uncertainty. A confidence-gated joint supervision strategy is further introduced to alleviate optimization conflicts. We construct KP-SAR-Aircraft-1.0, the first fine-grained benchmark for semantic scattering structure understanding. Extensive experiments demonstrate that S3U-SAR achieves the best performance compared with baselines. Cross-category and cross-dataset evaluations further verify its robustness and transferability.
EmoWear: Exploring Emotional Teasers for Voice Message Interaction on Smartwatches
Feb 11, 2024Voice messages, by nature, prevent users from gauging the emotional tone without fully diving into the audio content. This hinders the shared emotional experience at the pre-retrieval stage. Research scarcely explored "Emotional Teasers"-pre-retrieval cues offering a glimpse into an awaiting message's emotional tone without disclosing its content. We introduce EmoWear, a smartwatch voice messaging system enabling users to apply 30 animation teasers on message bubbles to reflect emotions. EmoWear eases senders' choice by prioritizing emotions based on semantic and acoustic processing. EmoWear was evaluated in comparison with a mirroring system using color-coded message bubbles as emotional cues (N=24). Results showed EmoWear significantly enhanced emotional communication experience in both receiving and sending messages. The animated teasers were considered intuitive and valued for diverse expressions. Desirable interaction qualities and practical implications are distilled for future design. We thereby contribute both a novel system and empirical knowledge concerning emotional teasers for voice messaging.
A Self-supervised SAR Image Despeckling Strategy Based on Parameter-sharing Convolutional Neural Networks
Aug 11, 2023Speckle noise is generated due to the SAR imaging mechanism, which brings difficulties in SAR image interpretation. Hence, despeckling is a helpful step in SAR pre-processing. Nowadays, deep learning has been proved to be a progressive method for SAR image despeckling. Most deep learning methods for despeckling are based on supervised learning, which needs original SAR images and speckle-free SAR images to train the network. However, the speckle-free SAR images are generally not available. So, this issue was tackled by adding multiplicative noise to optical images synthetically for simulating speckled image. Therefore, there are following challenges in SAR image despeckling: (1) lack of speckle-free SAR image; (2) difficulty in keeping details such as edges and textures in heterogeneous areas. To address these issues, we propose a self-supervised SAR despeckling strategy that can be trained without speckle-free images. Firstly, the feasibility of SAR image despeckling without speckle-free images is proved theoretically. Then, the sub-sampler based on the adjacent-syntropy criteria is proposed. The training image pairs are generated by the sub-sampler from real-word SAR image to estimate the noise distribution. Furthermore, to make full use of training pairs, the parameter sharing convolutional neural networks are adopted. Finally, according to the characteristics of SAR images, a multi-feature loss function is proposed. The proposed loss function is composed of despeckling term, regular term and perception term, to constrain the gap between the generated paired images. The ability of edge and texture feature preserving is improved simultaneously. Finally, qualitative and quantitative experiments are validated on real-world SAR images, showing better performances than several advanced SAR image despeckling methods.
Hi4D: 4D Instance Segmentation of Close Human Interaction
Mar 27, 2023
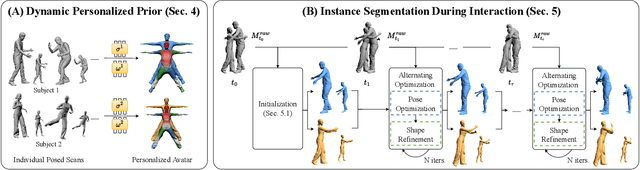
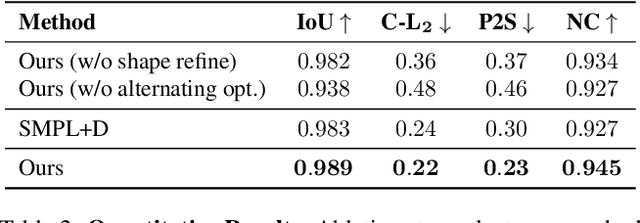
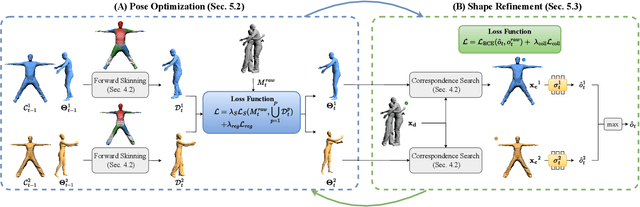
We propose Hi4D, a method and dataset for the automatic analysis of physically close human-human interaction under prolonged contact. Robustly disentangling several in-contact subjects is a challenging task due to occlusions and complex shapes. Hence, existing multi-view systems typically fuse 3D surfaces of close subjects into a single, connected mesh. To address this issue we leverage i) individually fitted neural implicit avatars; ii) an alternating optimization scheme that refines pose and surface through periods of close proximity; and iii) thus segment the fused raw scans into individual instances. From these instances we compile Hi4D dataset of 4D textured scans of 20 subject pairs, 100 sequences, and a total of more than 11K frames. Hi4D contains rich interaction-centric annotations in 2D and 3D alongside accurately registered parametric body models. We define varied human pose and shape estimation tasks on this dataset and provide results from state-of-the-art methods on these benchmarks.
Meta-Learning via Classifier(-free) Guidance
Oct 17, 2022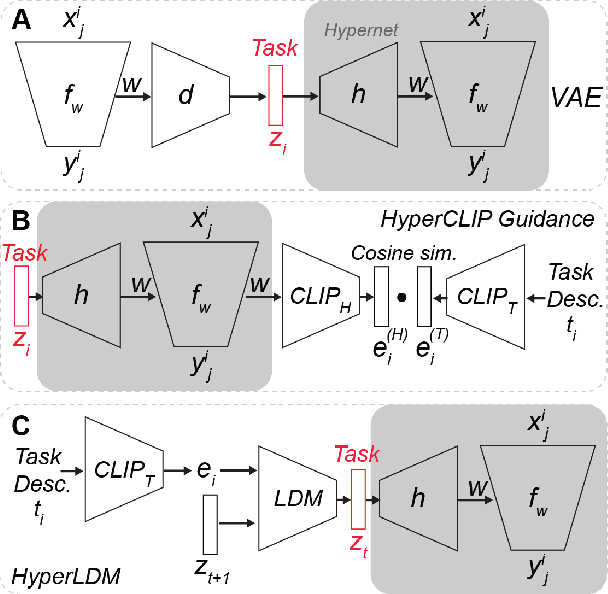
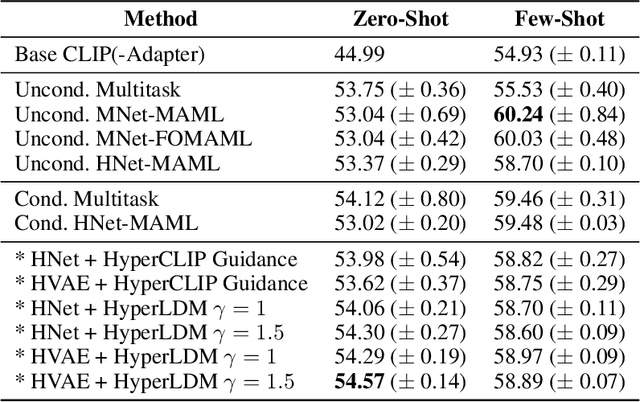


State-of-the-art meta-learning techniques do not optimize for zero-shot adaptation to unseen tasks, a setting in which humans excel. On the contrary, meta-learning algorithms learn hyperparameters and weight initializations that explicitly optimize for few-shot learning performance. In this work, we take inspiration from recent advances in generative modeling and language-conditioned image synthesis to propose meta-learning techniques that use natural language guidance to achieve higher zero-shot performance compared to the state-of-the-art. We do so by recasting the meta-learning problem as a multi-modal generative modeling problem: given a task, we consider its adapted neural network weights and its natural language description as equivalent multi-modal task representations. We first train an unconditional generative hypernetwork model to produce neural network weights; then we train a second "guidance" model that, given a natural language task description, traverses the hypernetwork latent space to find high-performance task-adapted weights in a zero-shot manner. We explore two alternative approaches for latent space guidance: "HyperCLIP"-based classifier guidance and a conditional Hypernetwork Latent Diffusion Model ("HyperLDM"), which we show to benefit from the classifier-free guidance technique common in image generation. Finally, we demonstrate that our approaches outperform existing meta-learning methods with zero-shot learning experiments on our Meta-VQA dataset, which we specifically constructed to reflect the multi-modal meta-learning setting.
Multi-Classifier Interactive Learning for Ambiguous Speech Emotion Recognition
Dec 12, 2020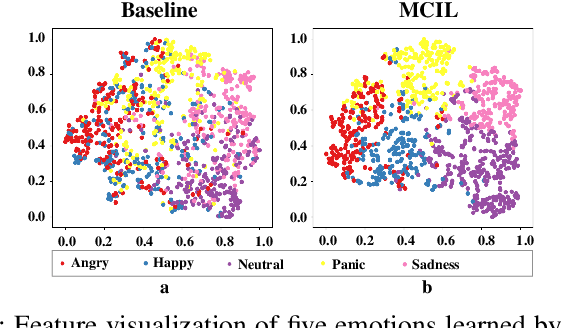
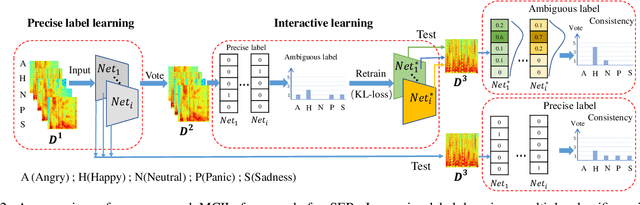
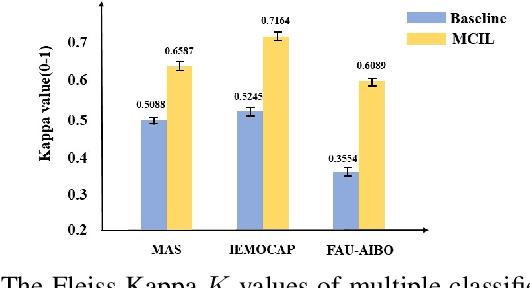
In recent years, speech emotion recognition technology is of great significance in industrial applications such as call centers, social robots and health care. The combination of speech recognition and speech emotion recognition can improve the feedback efficiency and the quality of service. Thus, the speech emotion recognition has been attracted much attention in both industry and academic. Since emotions existing in an entire utterance may have varied probabilities, speech emotion is likely to be ambiguous, which poses great challenges to recognition tasks. However, previous studies commonly assigned a single-label or multi-label to each utterance in certain. Therefore, their algorithms result in low accuracies because of the inappropriate representation. Inspired by the optimally interacting theory, we address the ambiguous speech emotions by proposing a novel multi-classifier interactive learning (MCIL) method. In MCIL, multiple different classifiers first mimic several individuals, who have inconsistent cognitions of ambiguous emotions, and construct new ambiguous labels (the emotion probability distribution). Then, they are retrained with the new labels to interact with their cognitions. This procedure enables each classifier to learn better representations of ambiguous data from others, and further improves the recognition ability. The experiments on three benchmark corpora (MAS, IEMOCAP, and FAU-AIBO) demonstrate that MCIL does not only improve each classifier's performance, but also raises their recognition consistency from moderate to substantial.