 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTripartite: Tackle Noisy Labels by a More Precise Partition
Feb 19, 2022



Samples in large-scale datasets may be mislabeled due to various reasons, and Deep Neural Networks can easily over-fit to the noisy label data. To tackle this problem, the key point is to alleviate the harm of these noisy labels. Many existing methods try to divide training data into clean and noisy subsets in terms of loss values, and then process the noisy label data varied. One of the reasons hindering a better performance is the hard samples. As hard samples always have relatively large losses whether their labels are clean or noisy, these methods could not divide them precisely. Instead, we propose a Tripartite solution to partition training data more precisely into three subsets: hard, noisy, and clean. The partition criteria are based on the inconsistent predictions of two networks, and the inconsistency between the prediction of a network and the given label. To minimize the harm of noisy labels but maximize the value of noisy label data, we apply a low-weight learning on hard data and a self-supervised learning on noisy label data without using the given labels. Extensive experiments demonstrate that Tripartite can filter out noisy label data more precisely, and outperforms most state-of-the-art methods on five benchmark datasets, especially on real-world datasets.
Multi-Classifier Interactive Learning for Ambiguous Speech Emotion Recognition
Dec 12, 2020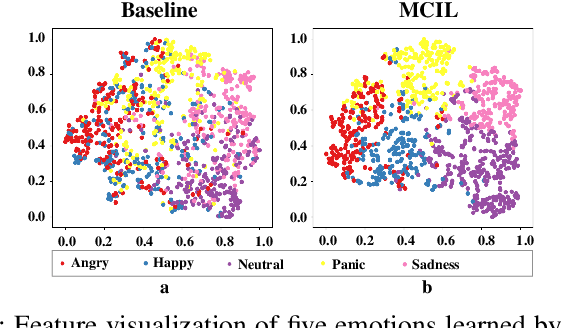
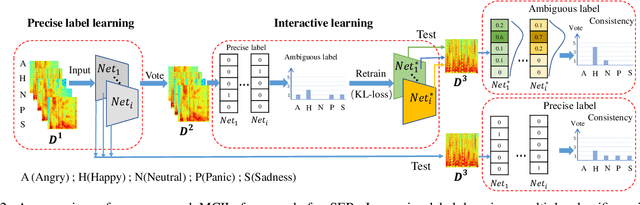
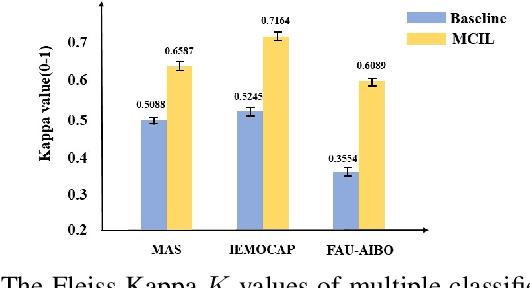
In recent years, speech emotion recognition technology is of great significance in industrial applications such as call centers, social robots and health care. The combination of speech recognition and speech emotion recognition can improve the feedback efficiency and the quality of service. Thus, the speech emotion recognition has been attracted much attention in both industry and academic. Since emotions existing in an entire utterance may have varied probabilities, speech emotion is likely to be ambiguous, which poses great challenges to recognition tasks. However, previous studies commonly assigned a single-label or multi-label to each utterance in certain. Therefore, their algorithms result in low accuracies because of the inappropriate representation. Inspired by the optimally interacting theory, we address the ambiguous speech emotions by proposing a novel multi-classifier interactive learning (MCIL) method. In MCIL, multiple different classifiers first mimic several individuals, who have inconsistent cognitions of ambiguous emotions, and construct new ambiguous labels (the emotion probability distribution). Then, they are retrained with the new labels to interact with their cognitions. This procedure enables each classifier to learn better representations of ambiguous data from others, and further improves the recognition ability. The experiments on three benchmark corpora (MAS, IEMOCAP, and FAU-AIBO) demonstrate that MCIL does not only improve each classifier's performance, but also raises their recognition consistency from moderate to substantial.