 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEGA: Drivable 3D Gaussian Head Avatar from a Single Image
Apr 19, 2025Creating photorealistic 3D head avatars from limited input has become increasingly important for applications in virtual reality, telepresence, and digital entertainment. While recent advances like neural rendering and 3D Gaussian splatting have enabled high-quality digital human avatar creation and animation, most methods rely on multiple images or multi-view inputs, limiting their practicality for real-world use. In this paper, we propose SEGA, a novel approach for Single-imagE-based 3D drivable Gaussian head Avatar creation that combines generalized prior models with a new hierarchical UV-space Gaussian Splatting framework. SEGA seamlessly combines priors derived from large-scale 2D datasets with 3D priors learned from multi-view, multi-expression, and multi-ID data, achieving robust generalization to unseen identities while ensuring 3D consistency across novel viewpoints and expressions. We further present a hierarchical UV-space Gaussian Splatting framework that leverages FLAME-based structural priors and employs a dual-branch architecture to disentangle dynamic and static facial components effectively. The dynamic branch encodes expression-driven fine details, while the static branch focuses on expression-invariant regions, enabling efficient parameter inference and precomputation. This design maximizes the utility of limited 3D data and achieves real-time performance for animation and rendering. Additionally, SEGA performs person-specific fine-tuning to further enhance the fidelity and realism of the generated avatars. Experiments show our method outperforms state-of-the-art approaches in generalization ability, identity preservation, and expression realism, advancing one-shot avatar creation for practical applications.
EnvPoser: Environment-aware Realistic Human Motion Estimation from Sparse Observations with Uncertainty Modeling
Dec 13, 2024



Estimating full-body motion using the tracking signals of head and hands from VR devices holds great potential for various applications. However, the sparsity and unique distribution of observations present a significant challenge, resulting in an ill-posed problem with multiple feasible solutions (i.e., hypotheses). This amplifies uncertainty and ambiguity in full-body motion estimation, especially for the lower-body joints. Therefore, we propose a new method, EnvPoser, that employs a two-stage framework to perform full-body motion estimation using sparse tracking signals and pre-scanned environment from VR devices. EnvPoser models the multi-hypothesis nature of human motion through an uncertainty-aware estimation module in the first stage. In the second stage, we refine these multi-hypothesis estimates by integrating semantic and geometric environmental constraints, ensuring that the final motion estimation aligns realistically with both the environmental context and physical interactions. Qualitative and quantitative experiments on two public datasets demonstrate that our method achieves state-of-the-art performance, highlighting significant improvements in human motion estimation within motion-environment interaction scenarios.
EMHI: A Multimodal Egocentric Human Motion Dataset with HMD and Body-Worn IMUs
Aug 30, 2024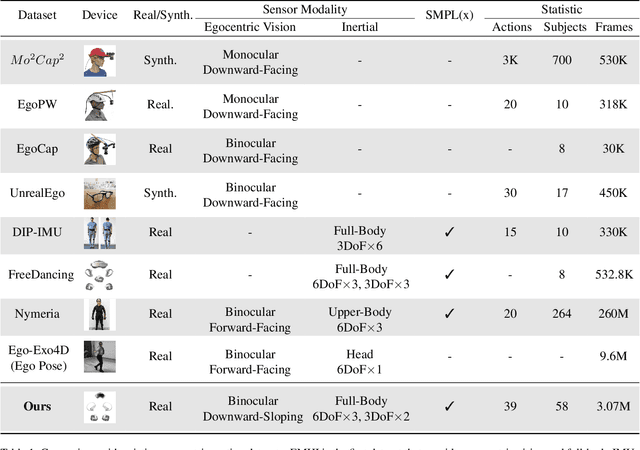
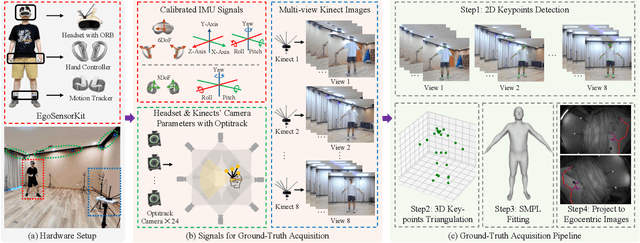
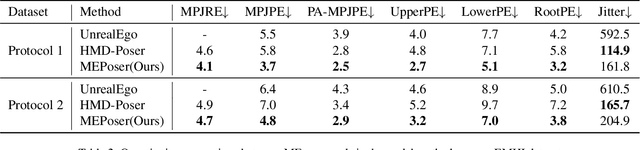
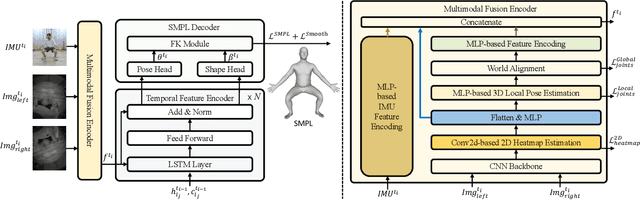
Egocentric human pose estimation (HPE) using wearable sensors is essential for VR/AR applications. Most methods rely solely on either egocentric-view images or sparse Inertial Measurement Unit (IMU) signals, leading to inaccuracies due to self-occlusion in images or the sparseness and drift of inertial sensors. Most importantly, the lack of real-world datasets containing both modalities is a major obstacle to progress in this field. To overcome the barrier, we propose EMHI, a multimodal \textbf{E}gocentric human \textbf{M}otion dataset with \textbf{H}ead-Mounted Display (HMD) and body-worn \textbf{I}MUs, with all data collected under the real VR product suite. Specifically, EMHI provides synchronized stereo images from downward-sloping cameras on the headset and IMU data from body-worn sensors, along with pose annotations in SMPL format. This dataset consists of 885 sequences captured by 58 subjects performing 39 actions, totaling about 28.5 hours of recording. We evaluate the annotations by comparing them with optical marker-based SMPL fitting results. To substantiate the reliability of our dataset, we introduce MEPoser, a new baseline method for multimodal egocentric HPE, which employs a multimodal fusion encoder, temporal feature encoder, and MLP-based regression heads. The experiments on EMHI show that MEPoser outperforms existing single-modal methods and demonstrates the value of our dataset in solving the problem of egocentric HPE. We believe the release of EMHI and the method could advance the research of egocentric HPE and expedite the practical implementation of this technology in VR/AR products.
HeadGAP: Few-shot 3D Head Avatar via Generalizable Gaussian Priors
Aug 12, 2024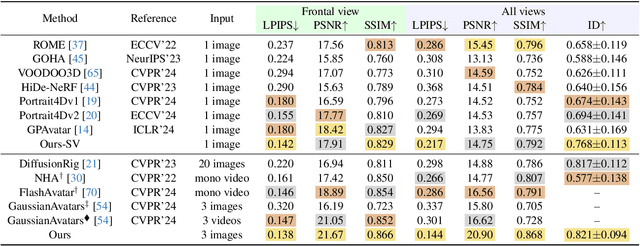

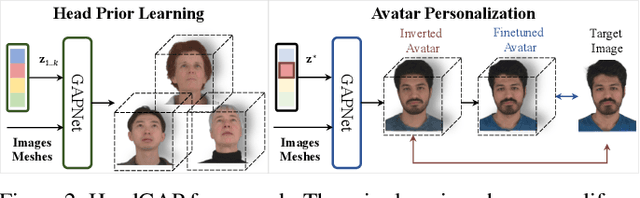
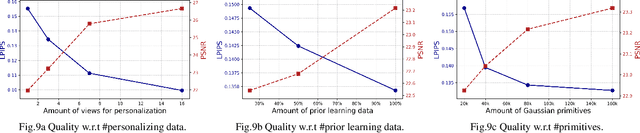
In this paper, we present a novel 3D head avatar creation approach capable of generalizing from few-shot in-the-wild data with high-fidelity and animatable robustness. Given the underconstrained nature of this problem, incorporating prior knowledge is essential. Therefore, we propose a framework comprising prior learning and avatar creation phases. The prior learning phase leverages 3D head priors derived from a large-scale multi-view dynamic dataset, and the avatar creation phase applies these priors for few-shot personalization. Our approach effectively captures these priors by utilizing a Gaussian Splatting-based auto-decoder network with part-based dynamic modeling. Our method employs identity-shared encoding with personalized latent codes for individual identities to learn the attributes of Gaussian primitives. During the avatar creation phase, we achieve fast head avatar personalization by leveraging inversion and fine-tuning strategies. Extensive experiments demonstrate that our model effectively exploits head priors and successfully generalizes them to few-shot personalization, achieving photo-realistic rendering quality, multi-view consistency, and stable animation.
SchurVINS: Schur Complement-Based Lightweight Visual Inertial Navigation System
Dec 04, 2023Accuracy and computational efficiency are the most important metrics to Visual Inertial Navigation System (VINS). The existing VINS algorithms with either high accuracy or low computational complexity, are difficult to provide the high precision localization in resource-constrained devices. To this end, we propose a novel filter-based VINS framework named SchurVINS, which could guarantee both high accuracy by building a complete residual model and low computational complexity with Schur complement. Technically, we first formulate the full residual model where Gradient, Hessian and observation covariance are explicitly modeled. Then Schur complement is employed to decompose the full model into ego-motion residual model and landmark residual model. Finally, Extended Kalman Filter (EKF) update is implemented in these two models with high efficiency. Experiments on EuRoC and TUM-VI datasets show that our method notably outperforms state-of-the-art (SOTA) methods in both accuracy and computational complexity. We will open source our experimental code to benefit the community.