 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025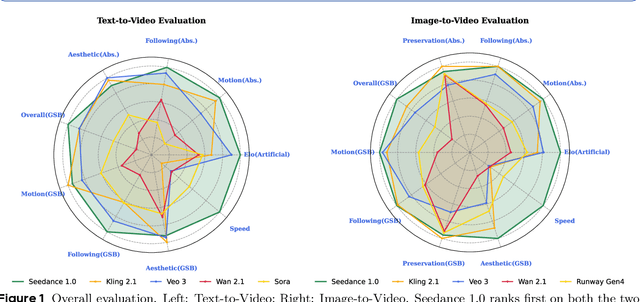
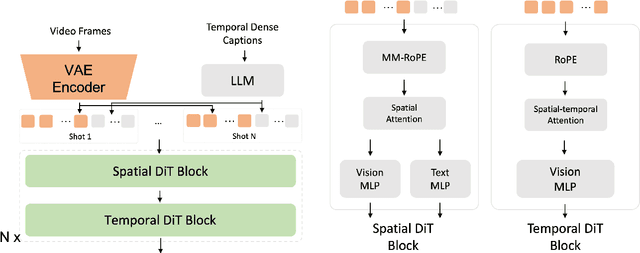
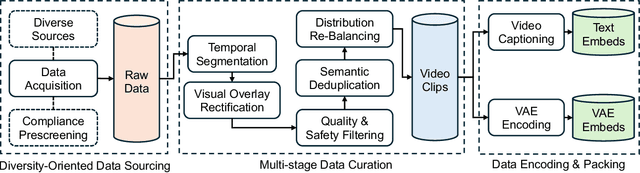
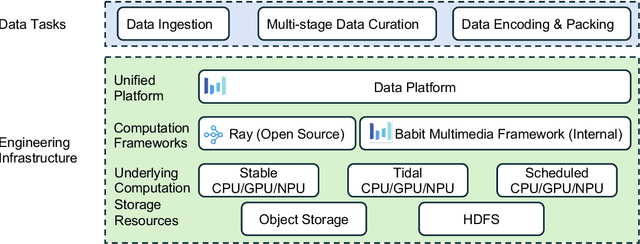
Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
EnvPoser: Environment-aware Realistic Human Motion Estimation from Sparse Observations with Uncertainty Modeling
Dec 13, 2024



Estimating full-body motion using the tracking signals of head and hands from VR devices holds great potential for various applications. However, the sparsity and unique distribution of observations present a significant challenge, resulting in an ill-posed problem with multiple feasible solutions (i.e., hypotheses). This amplifies uncertainty and ambiguity in full-body motion estimation, especially for the lower-body joints. Therefore, we propose a new method, EnvPoser, that employs a two-stage framework to perform full-body motion estimation using sparse tracking signals and pre-scanned environment from VR devices. EnvPoser models the multi-hypothesis nature of human motion through an uncertainty-aware estimation module in the first stage. In the second stage, we refine these multi-hypothesis estimates by integrating semantic and geometric environmental constraints, ensuring that the final motion estimation aligns realistically with both the environmental context and physical interactions. Qualitative and quantitative experiments on two public datasets demonstrate that our method achieves state-of-the-art performance, highlighting significant improvements in human motion estimation within motion-environment interaction scenarios.
HeadGAP: Few-shot 3D Head Avatar via Generalizable Gaussian Priors
Aug 12, 2024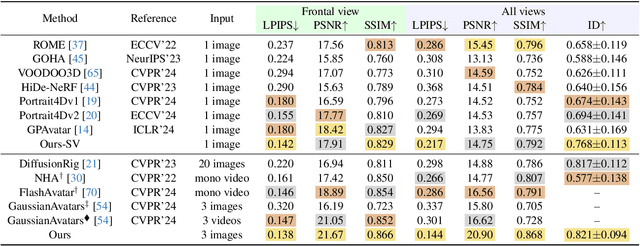

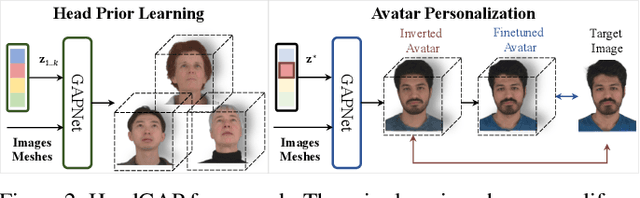
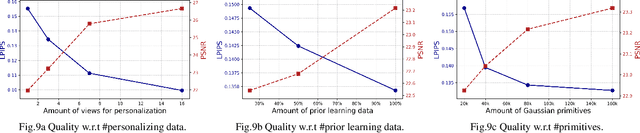
In this paper, we present a novel 3D head avatar creation approach capable of generalizing from few-shot in-the-wild data with high-fidelity and animatable robustness. Given the underconstrained nature of this problem, incorporating prior knowledge is essential. Therefore, we propose a framework comprising prior learning and avatar creation phases. The prior learning phase leverages 3D head priors derived from a large-scale multi-view dynamic dataset, and the avatar creation phase applies these priors for few-shot personalization. Our approach effectively captures these priors by utilizing a Gaussian Splatting-based auto-decoder network with part-based dynamic modeling. Our method employs identity-shared encoding with personalized latent codes for individual identities to learn the attributes of Gaussian primitives. During the avatar creation phase, we achieve fast head avatar personalization by leveraging inversion and fine-tuning strategies. Extensive experiments demonstrate that our model effectively exploits head priors and successfully generalizes them to few-shot personalization, achieving photo-realistic rendering quality, multi-view consistency, and stable animation.
HMD-Poser: On-Device Real-time Human Motion Tracking from Scalable Sparse Observations
Mar 06, 2024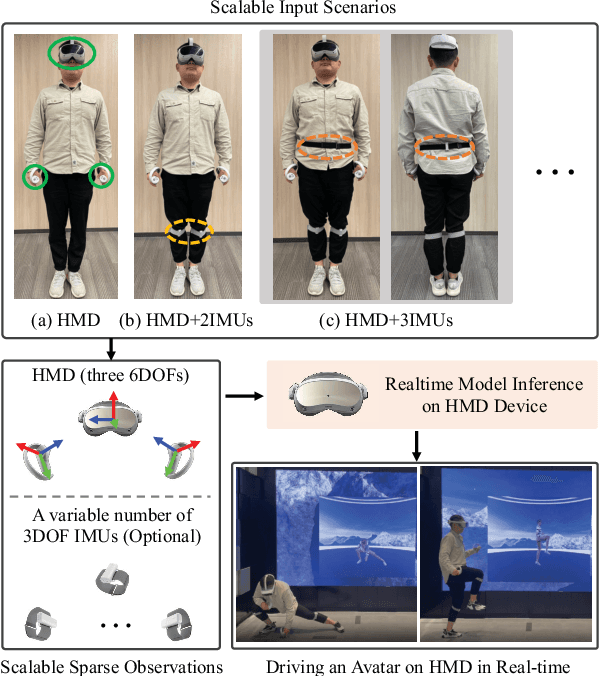
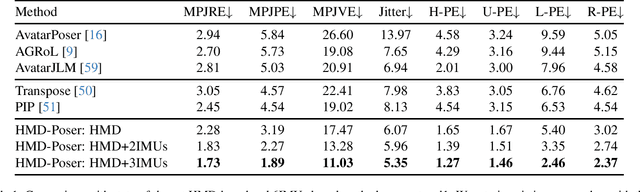
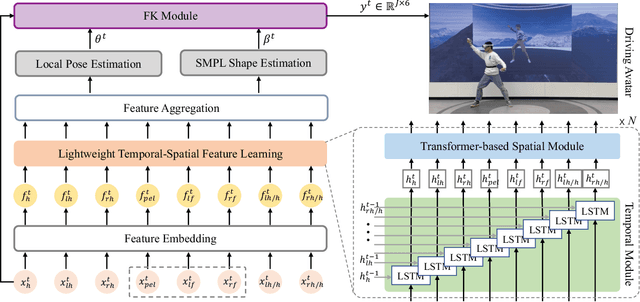
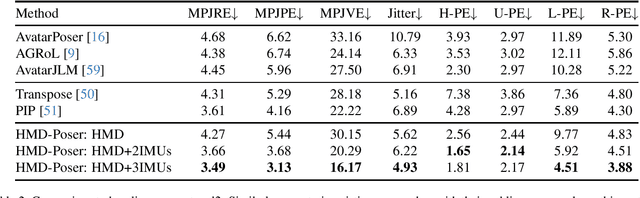
It is especially challenging to achieve real-time human motion tracking on a standalone VR Head-Mounted Display (HMD) such as Meta Quest and PICO. In this paper, we propose HMD-Poser, the first unified approach to recover full-body motions using scalable sparse observations from HMD and body-worn IMUs. In particular, it can support a variety of input scenarios, such as HMD, HMD+2IMUs, HMD+3IMUs, etc. The scalability of inputs may accommodate users' choices for both high tracking accuracy and easy-to-wear. A lightweight temporal-spatial feature learning network is proposed in HMD-Poser to guarantee that the model runs in real-time on HMDs. Furthermore, HMD-Poser presents online body shape estimation to improve the position accuracy of body joints. Extensive experimental results on the challenging AMASS dataset show that HMD-Poser achieves new state-of-the-art results in both accuracy and real-time performance. We also build a new free-dancing motion dataset to evaluate HMD-Poser's on-device performance and investigate the performance gap between synthetic data and real-captured sensor data. Finally, we demonstrate our HMD-Poser with a real-time Avatar-driving application on a commercial HMD. Our code and free-dancing motion dataset are available https://pico-ai-team.github.io/hmd-poser
OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
Feb 29, 2024In this paper, we delve into the creation of one-shot hand avatars, attaining high-fidelity and drivable hand representations swiftly from a single image. With the burgeoning domains of the digital human, the need for quick and personalized hand avatar creation has become increasingly critical. Existing techniques typically require extensive input data and may prove cumbersome or even impractical in certain scenarios. To enhance accessibility, we present a novel method OHTA (One-shot Hand avaTAr) that enables the creation of detailed hand avatars from merely one image. OHTA tackles the inherent difficulties of this data-limited problem by learning and utilizing data-driven hand priors. Specifically, we design a hand prior model initially employed for 1) learning various hand priors with available data and subsequently for 2) the inversion and fitting of the target identity with prior knowledge. OHTA demonstrates the capability to create high-fidelity hand avatars with consistent animatable quality, solely relying on a single image. Furthermore, we illustrate the versatility of OHTA through diverse applications, encompassing text-to-avatar conversion, hand editing, and identity latent space manipulation.
Realistic Full-Body Tracking from Sparse Observations via Joint-Level Modeling
Aug 17, 2023To bridge the physical and virtual worlds for rapidly developed VR/AR applications, the ability to realistically drive 3D full-body avatars is of great significance. Although real-time body tracking with only the head-mounted displays (HMDs) and hand controllers is heavily under-constrained, a carefully designed end-to-end neural network is of great potential to solve the problem by learning from large-scale motion data. To this end, we propose a two-stage framework that can obtain accurate and smooth full-body motions with the three tracking signals of head and hands only. Our framework explicitly models the joint-level features in the first stage and utilizes them as spatiotemporal tokens for alternating spatial and temporal transformer blocks to capture joint-level correlations in the second stage. Furthermore, we design a set of loss terms to constrain the task of a high degree of freedom, such that we can exploit the potential of our joint-level modeling. With extensive experiments on the AMASS motion dataset and real-captured data, we validate the effectiveness of our designs and show our proposed method can achieve more accurate and smooth motion compared to existing approaches.
See You Soon: Decoupled Iterative Refinement Framework for Interacting Hands Reconstruction from a Single RGB Image
Feb 05, 2023Reconstructing interacting hands from a single RGB image is a very challenging task. On the one hand, severe mutual occlusion and similar local appearance between two hands confuse the extraction of visual features, resulting in the misalignment of estimated hand meshes and the image. On the other hand, there are complex interaction patterns between interacting hands, which significantly increases the solution space of hand poses and increases the difficulty of network learning. In this paper, we propose a decoupled iterative refinement framework to achieve pixel-alignment hand reconstruction while efficiently modeling the spatial relationship between hands. Specifically, we define two feature spaces with different characteristics, namely 2D visual feature space and 3D joint feature space. First, we obtain joint-wise features from the visual feature map and utilize a graph convolution network and a transformer to perform intra- and inter-hand information interaction in the 3D joint feature space, respectively. Then, we project the joint features with global information back into the 2D visual feature space in an obfuscation-free manner and utilize the 2D convolution for pixel-wise enhancement. By performing multiple alternate enhancements in the two feature spaces, our method can achieve an accurate and robust reconstruction of interacting hands. Our method outperforms all existing two-hand reconstruction methods by a large margin on the InterHand2.6M dataset. Meanwhile, our method shows a strong generalization ability for in-the-wild images.
Hand Pose Estimation via Multiview Collaborative Self-Supervised Learning
Feb 02, 20233D hand pose estimation has made significant progress in recent years. However, the improvement is highly dependent on the emergence of large-scale annotated datasets. To alleviate the label-hungry limitation, we propose a multi-view collaborative self-supervised learning framework, HaMuCo, that estimates hand pose only with pseudo labels for training. We use a two-stage strategy to tackle the noisy label challenge and the multi-view ``groupthink'' problem. In the first stage, we estimate the 3D hand poses for each view independently. In the second stage, we employ a cross-view interaction network to capture the cross-view correlated features and use multi-view consistency loss to achieve collaborative learning among views. To further enhance the collaboration between single-view and multi-view, we fuse the results of all views to supervise the single-view network. To summarize, we introduce collaborative learning in two folds, the cross-view level and the multi- to single-view level. Extensive experiments show that our method can achieve state-of-the-art performance on multi-view self-supervised hand pose estimation. Moreover, ablation studies verify the effectiveness of each component. Results on multiple datasets further demonstrate the generalization ability of our network.