 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvPoser: Environment-aware Realistic Human Motion Estimation from Sparse Observations with Uncertainty Modeling
Dec 13, 2024



Estimating full-body motion using the tracking signals of head and hands from VR devices holds great potential for various applications. However, the sparsity and unique distribution of observations present a significant challenge, resulting in an ill-posed problem with multiple feasible solutions (i.e., hypotheses). This amplifies uncertainty and ambiguity in full-body motion estimation, especially for the lower-body joints. Therefore, we propose a new method, EnvPoser, that employs a two-stage framework to perform full-body motion estimation using sparse tracking signals and pre-scanned environment from VR devices. EnvPoser models the multi-hypothesis nature of human motion through an uncertainty-aware estimation module in the first stage. In the second stage, we refine these multi-hypothesis estimates by integrating semantic and geometric environmental constraints, ensuring that the final motion estimation aligns realistically with both the environmental context and physical interactions. Qualitative and quantitative experiments on two public datasets demonstrate that our method achieves state-of-the-art performance, highlighting significant improvements in human motion estimation within motion-environment interaction scenarios.
HeadGAP: Few-shot 3D Head Avatar via Generalizable Gaussian Priors
Aug 12, 2024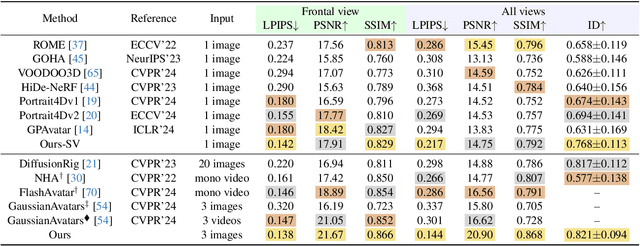

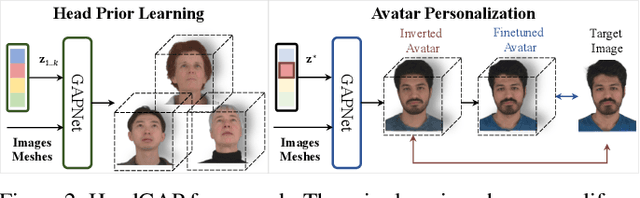
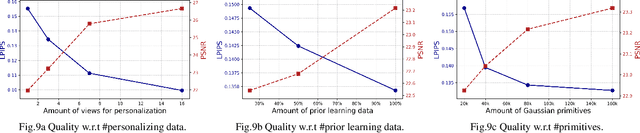
In this paper, we present a novel 3D head avatar creation approach capable of generalizing from few-shot in-the-wild data with high-fidelity and animatable robustness. Given the underconstrained nature of this problem, incorporating prior knowledge is essential. Therefore, we propose a framework comprising prior learning and avatar creation phases. The prior learning phase leverages 3D head priors derived from a large-scale multi-view dynamic dataset, and the avatar creation phase applies these priors for few-shot personalization. Our approach effectively captures these priors by utilizing a Gaussian Splatting-based auto-decoder network with part-based dynamic modeling. Our method employs identity-shared encoding with personalized latent codes for individual identities to learn the attributes of Gaussian primitives. During the avatar creation phase, we achieve fast head avatar personalization by leveraging inversion and fine-tuning strategies. Extensive experiments demonstrate that our model effectively exploits head priors and successfully generalizes them to few-shot personalization, achieving photo-realistic rendering quality, multi-view consistency, and stable animation.
HumanSplat: Generalizable Single-Image Human Gaussian Splatting with Structure Priors
Jun 18, 2024Despite recent advancements in high-fidelity human reconstruction techniques, the requirements for densely captured images or time-consuming per-instance optimization significantly hinder their applications in broader scenarios. To tackle these issues, we present HumanSplat which predicts the 3D Gaussian Splatting properties of any human from a single input image in a generalizable manner. In particular, HumanSplat comprises a 2D multi-view diffusion model and a latent reconstruction transformer with human structure priors that adeptly integrate geometric priors and semantic features within a unified framework. A hierarchical loss that incorporates human semantic information is further designed to achieve high-fidelity texture modeling and better constrain the estimated multiple views. Comprehensive experiments on standard benchmarks and in-the-wild images demonstrate that HumanSplat surpasses existing state-of-the-art methods in achieving photorealistic novel-view synthesis.