 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartCrafter: Structured 3D Mesh Generation via Compositional Latent Diffusion Transformers
Jun 05, 2025We introduce PartCrafter, the first structured 3D generative model that jointly synthesizes multiple semantically meaningful and geometrically distinct 3D meshes from a single RGB image. Unlike existing methods that either produce monolithic 3D shapes or follow two-stage pipelines, i.e., first segmenting an image and then reconstructing each segment, PartCrafter adopts a unified, compositional generation architecture that does not rely on pre-segmented inputs. Conditioned on a single image, it simultaneously denoises multiple 3D parts, enabling end-to-end part-aware generation of both individual objects and complex multi-object scenes. PartCrafter builds upon a pretrained 3D mesh diffusion transformer (DiT) trained on whole objects, inheriting the pretrained weights, encoder, and decoder, and introduces two key innovations: (1) A compositional latent space, where each 3D part is represented by a set of disentangled latent tokens; (2) A hierarchical attention mechanism that enables structured information flow both within individual parts and across all parts, ensuring global coherence while preserving part-level detail during generation. To support part-level supervision, we curate a new dataset by mining part-level annotations from large-scale 3D object datasets. Experiments show that PartCrafter outperforms existing approaches in generating decomposable 3D meshes, including parts that are not directly visible in input images, demonstrating the strength of part-aware generative priors for 3D understanding and synthesis. Code and training data will be released.
OmniPhysGS: 3D Constitutive Gaussians for General Physics-Based Dynamics Generation
Jan 31, 2025



Recently, significant advancements have been made in the reconstruction and generation of 3D assets, including static cases and those with physical interactions. To recover the physical properties of 3D assets, existing methods typically assume that all materials belong to a specific predefined category (e.g., elasticity). However, such assumptions ignore the complex composition of multiple heterogeneous objects in real scenarios and tend to render less physically plausible animation given a wider range of objects. We propose OmniPhysGS for synthesizing a physics-based 3D dynamic scene composed of more general objects. A key design of OmniPhysGS is treating each 3D asset as a collection of constitutive 3D Gaussians. For each Gaussian, its physical material is represented by an ensemble of 12 physical domain-expert sub-models (rubber, metal, honey, water, etc.), which greatly enhances the flexibility of the proposed model. In the implementation, we define a scene by user-specified prompts and supervise the estimation of material weighting factors via a pretrained video diffusion model. Comprehensive experiments demonstrate that OmniPhysGS achieves more general and realistic physical dynamics across a broader spectrum of materials, including elastic, viscoelastic, plastic, and fluid substances, as well as interactions between different materials. Our method surpasses existing methods by approximately 3% to 16% in metrics of visual quality and text alignment.
DiffSplat: Repurposing Image Diffusion Models for Scalable Gaussian Splat Generation
Jan 28, 2025Recent advancements in 3D content generation from text or a single image struggle with limited high-quality 3D datasets and inconsistency from 2D multi-view generation. We introduce DiffSplat, a novel 3D generative framework that natively generates 3D Gaussian splats by taming large-scale text-to-image diffusion models. It differs from previous 3D generative models by effectively utilizing web-scale 2D priors while maintaining 3D consistency in a unified model. To bootstrap the training, a lightweight reconstruction model is proposed to instantly produce multi-view Gaussian splat grids for scalable dataset curation. In conjunction with the regular diffusion loss on these grids, a 3D rendering loss is introduced to facilitate 3D coherence across arbitrary views. The compatibility with image diffusion models enables seamless adaptions of numerous techniques for image generation to the 3D realm. Extensive experiments reveal the superiority of DiffSplat in text- and image-conditioned generation tasks and downstream applications. Thorough ablation studies validate the efficacy of each critical design choice and provide insights into the underlying mechanism.
InstructLayout: Instruction-Driven 2D and 3D Layout Synthesis with Semantic Graph Prior
Jul 11, 2024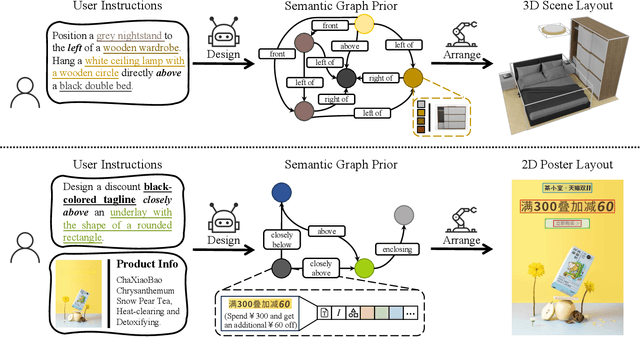
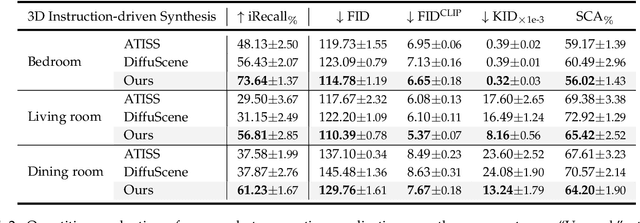
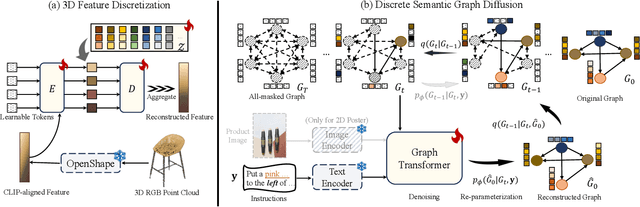
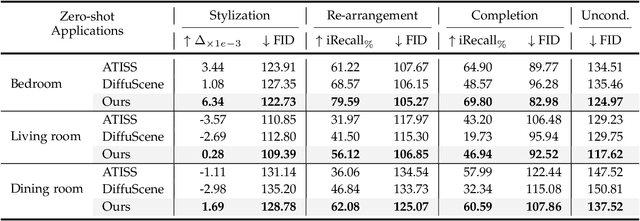
Comprehending natural language instructions is a charming property for both 2D and 3D layout synthesis systems. Existing methods implicitly model object joint distributions and express object relations, hindering generation's controllability. We introduce InstructLayout, a novel generative framework that integrates a semantic graph prior and a layout decoder to improve controllability and fidelity for 2D and 3D layout synthesis. The proposed semantic graph prior learns layout appearances and object distributions simultaneously, demonstrating versatility across various downstream tasks in a zero-shot manner. To facilitate the benchmarking for text-driven 2D and 3D scene synthesis, we respectively curate two high-quality datasets of layout-instruction pairs from public Internet resources with large language and multimodal models. Extensive experimental results reveal that the proposed method outperforms existing state-of-the-art approaches by a large margin in both 2D and 3D layout synthesis tasks. Thorough ablation studies confirm the efficacy of crucial design components.
HumanSplat: Generalizable Single-Image Human Gaussian Splatting with Structure Priors
Jun 18, 2024Despite recent advancements in high-fidelity human reconstruction techniques, the requirements for densely captured images or time-consuming per-instance optimization significantly hinder their applications in broader scenarios. To tackle these issues, we present HumanSplat which predicts the 3D Gaussian Splatting properties of any human from a single input image in a generalizable manner. In particular, HumanSplat comprises a 2D multi-view diffusion model and a latent reconstruction transformer with human structure priors that adeptly integrate geometric priors and semantic features within a unified framework. A hierarchical loss that incorporates human semantic information is further designed to achieve high-fidelity texture modeling and better constrain the estimated multiple views. Comprehensive experiments on standard benchmarks and in-the-wild images demonstrate that HumanSplat surpasses existing state-of-the-art methods in achieving photorealistic novel-view synthesis.
InstructScene: Instruction-Driven 3D Indoor Scene Synthesis with Semantic Graph Prior
Feb 07, 2024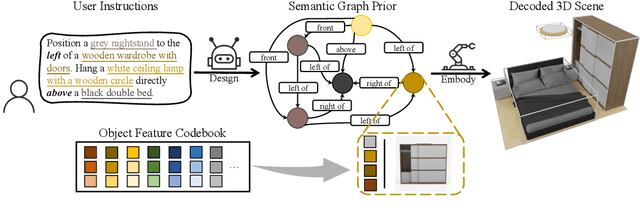
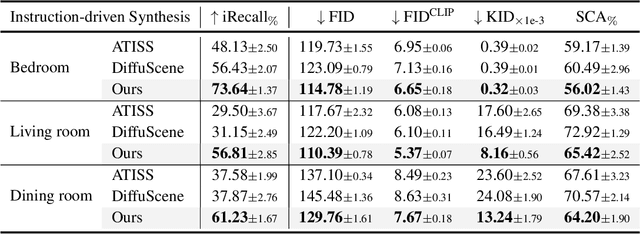
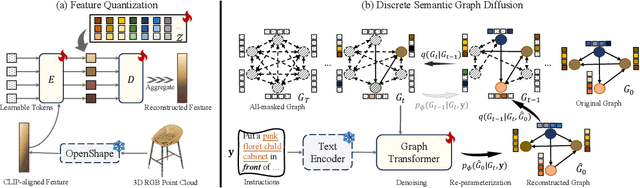
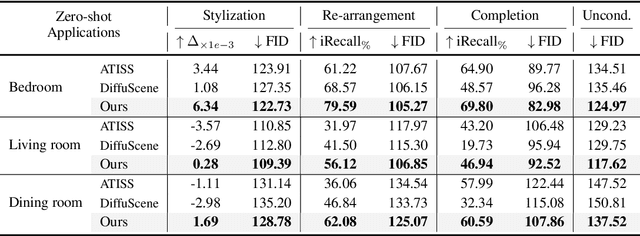
Comprehending natural language instructions is a charming property for 3D indoor scene synthesis systems. Existing methods directly model object joint distributions and express object relations implicitly within a scene, thereby hindering the controllability of generation. We introduce InstructScene, a novel generative framework that integrates a semantic graph prior and a layout decoder to improve controllability and fidelity for 3D scene synthesis. The proposed semantic graph prior jointly learns scene appearances and layout distributions, exhibiting versatility across various downstream tasks in a zero-shot manner. To facilitate the benchmarking for text-driven 3D scene synthesis, we curate a high-quality dataset of scene-instruction pairs with large language and multimodal models. Extensive experimental results reveal that the proposed method surpasses existing state-of-the-art approaches by a large margin. Thorough ablation studies confirm the efficacy of crucial design components. Project page: https://chenguolin.github.io/projects/InstructScene.
NuTime: Numerically Multi-Scaled Embedding for Large-Scale Time Series Pretraining
Oct 12, 2023Recent research on time-series self-supervised models shows great promise in learning semantic representations. However, it has been limited to small-scale datasets, e.g., thousands of temporal sequences. In this work, we make key technical contributions that are tailored to the numerical properties of time-series data and allow the model to scale to large datasets, e.g., millions of temporal sequences. We adopt the Transformer architecture by first partitioning the input into non-overlapping windows. Each window is then characterized by its normalized shape and two scalar values denoting the mean and standard deviation within each window. To embed scalar values that may possess arbitrary numerical scales to high-dimensional vectors, we propose a numerically multi-scaled embedding module enumerating all possible scales for the scalar values. The model undergoes pretraining using the proposed numerically multi-scaled embedding with a simple contrastive objective on a large-scale dataset containing over a million sequences. We study its transfer performance on a number of univariate and multivariate classification benchmarks. Our method exhibits remarkable improvement against previous representation learning approaches and establishes the new state of the art, even compared with domain-specific non-learning-based methods.
Watermark Faker: Towards Forgery of Digital Image Watermarking
Mar 23, 2021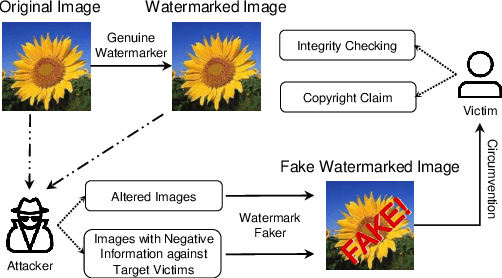
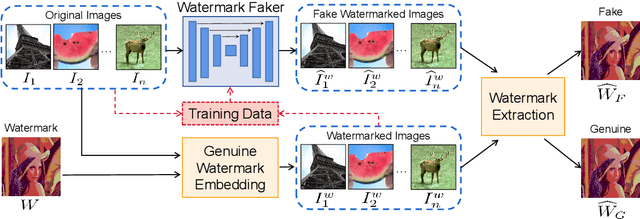
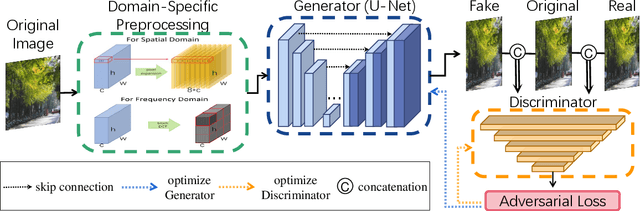
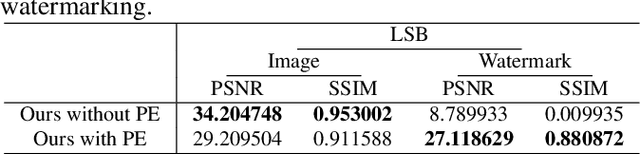
Digital watermarking has been widely used to protect the copyright and integrity of multimedia data. Previous studies mainly focus on designing watermarking techniques that are robust to attacks of destroying the embedded watermarks. However, the emerging deep learning based image generation technology raises new open issues that whether it is possible to generate fake watermarked images for circumvention. In this paper, we make the first attempt to develop digital image watermark fakers by using generative adversarial learning. Suppose that a set of paired images of original and watermarked images generated by the targeted watermarker are available, we use them to train a watermark faker with U-Net as the backbone, whose input is an original image, and after a domain-specific preprocessing, it outputs a fake watermarked image. Our experiments show that the proposed watermark faker can effectively crack digital image watermarkers in both spatial and frequency domains, suggesting the risk of such forgery attacks.
A Brief Survey on Deep Learning Based Data Hiding, Steganography and Watermarking
Mar 02, 2021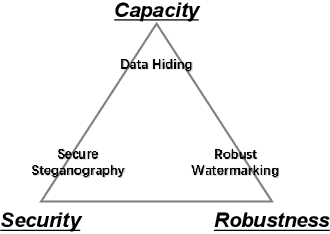
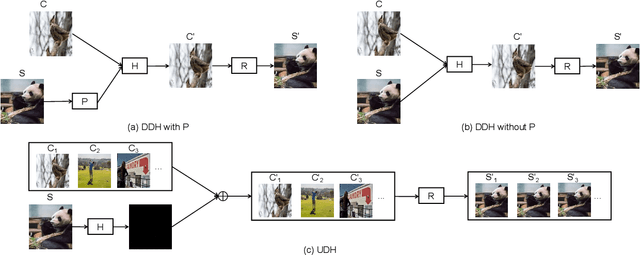
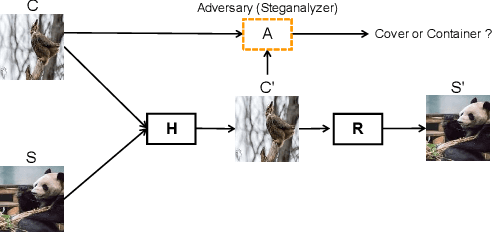
Data hiding is the art of concealing messages with limited perceptual changes. Recently, deep learning has provided enriching perspectives for it and made significant progress. In this work, we conduct a brief yet comprehensive review of existing literature and outline three meta-architectures. Based on this, we summarize specific strategies for various applications of deep hiding, including steganography, light field messaging and watermarking. Finally, further insight into deep hiding is provided through incorporating the perspective of adversarial attack.
A Survey On Universal Adversarial Attack
Mar 02, 2021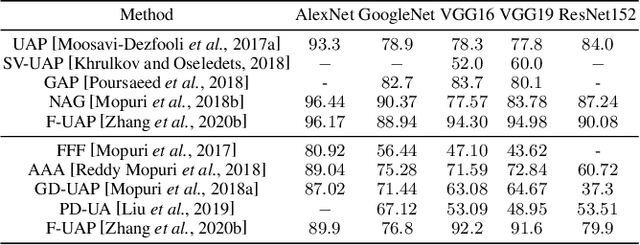
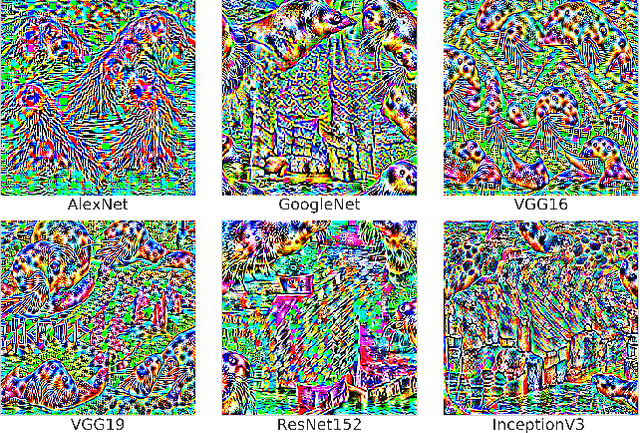
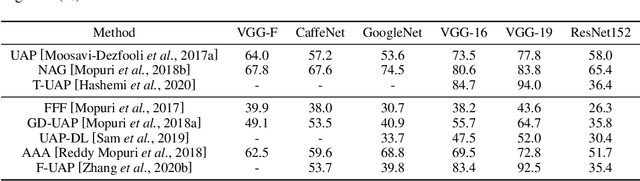
Deep neural networks (DNNs) have demonstrated remarkable performance for various applications, meanwhile, they are widely known to be vulnerable to the attack of adversarial perturbations. This intriguing phenomenon has attracted significant attention in machine learning and what might be more surprising to the community is the existence of universal adversarial perturbations (UAPs), i.e. a single perturbation to fool the target DNN for most images. The advantage of UAP is that it can be generated beforehand and then be applied on-the-fly during the attack. With the focus on UAP against deep classifiers, this survey summarizes the recent progress on universal adversarial attacks, discussing the challenges from both the attack and defense sides, as well as the reason for the existence of UAP. Additionally, universal attacks in a wide range of applications beyond deep classification are also covered.