 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramidalWan: On Making Pretrained Video Model Pyramidal for Efficient Inference
Jan 08, 2026Recently proposed pyramidal models decompose the conventional forward and backward diffusion processes into multiple stages operating at varying resolutions. These models handle inputs with higher noise levels at lower resolutions, while less noisy inputs are processed at higher resolutions. This hierarchical approach significantly reduces the computational cost of inference in multi-step denoising models. However, existing open-source pyramidal video models have been trained from scratch and tend to underperform compared to state-of-the-art systems in terms of visual plausibility. In this work, we present a pipeline that converts a pretrained diffusion model into a pyramidal one through low-cost finetuning, achieving this transformation without degradation in quality of output videos. Furthermore, we investigate and compare various strategies for step distillation within pyramidal models, aiming to further enhance the inference efficiency. Our results are available at https://qualcomm-ai-research.github.io/PyramidalWan.
Neodragon: Mobile Video Generation using Diffusion Transformer
Nov 08, 2025We introduce Neodragon, a text-to-video system capable of generating 2s (49 frames @24 fps) videos at the 640x1024 resolution directly on a Qualcomm Hexagon NPU in a record 6.7s (7 FPS). Differing from existing transformer-based offline text-to-video generation models, Neodragon is the first to have been specifically optimised for mobile hardware to achieve efficient and high-fidelity video synthesis. We achieve this through four key technical contributions: (1) Replacing the original large 4.762B T5xxl Text-Encoder with a much smaller 0.2B DT5 (DistilT5) with minimal quality loss, enabled through a novel Text-Encoder Distillation procedure. (2) Proposing an Asymmetric Decoder Distillation approach allowing us to replace the native codec-latent-VAE decoder with a more efficient one, without disturbing the generative latent-space of the generation pipeline. (3) Pruning of MMDiT blocks within the denoiser backbone based on their relative importance, with recovery of original performance through a two-stage distillation process. (4) Reducing the NFE (Neural Functional Evaluation) requirement of the denoiser by performing step distillation using DMD adapted for pyramidal flow-matching, thereby substantially accelerating video generation. When paired with an optimised SSD1B first-frame image generator and QuickSRNet for 2x super-resolution, our end-to-end Neodragon system becomes a highly parameter (4.945B full model), memory (3.5GB peak RAM usage), and runtime (6.7s E2E latency) efficient mobile-friendly model, while achieving a VBench total score of 81.61. By enabling low-cost, private, and on-device text-to-video synthesis, Neodragon democratizes AI-based video content creation, empowering creators to generate high-quality videos without reliance on cloud services. Code and model will be made publicly available at our website: https://qualcomm-ai-research.github.io/neodragon
MoViE: Mobile Diffusion for Video Editing
Dec 09, 2024Recent progress in diffusion-based video editing has shown remarkable potential for practical applications. However, these methods remain prohibitively expensive and challenging to deploy on mobile devices. In this study, we introduce a series of optimizations that render mobile video editing feasible. Building upon the existing image editing model, we first optimize its architecture and incorporate a lightweight autoencoder. Subsequently, we extend classifier-free guidance distillation to multiple modalities, resulting in a threefold on-device speedup. Finally, we reduce the number of sampling steps to one by introducing a novel adversarial distillation scheme which preserves the controllability of the editing process. Collectively, these optimizations enable video editing at 12 frames per second on mobile devices, while maintaining high quality. Our results are available at https://qualcomm-ai-research.github.io/mobile-video-editing/
Object-Centric Diffusion for Efficient Video Editing
Jan 11, 2024



Diffusion-based video editing have reached impressive quality and can transform either the global style, local structure, and attributes of given video inputs, following textual edit prompts. However, such solutions typically incur heavy memory and computational costs to generate temporally-coherent frames, either in the form of diffusion inversion and/or cross-frame attention. In this paper, we conduct an analysis of such inefficiencies, and suggest simple yet effective modifications that allow significant speed-ups whilst maintaining quality. Moreover, we introduce Object-Centric Diffusion, coined as OCD, to further reduce latency by allocating computations more towards foreground edited regions that are arguably more important for perceptual quality. We achieve this by two novel proposals: i) Object-Centric Sampling, decoupling the diffusion steps spent on salient regions or background, allocating most of the model capacity to the former, and ii) Object-Centric 3D Token Merging, which reduces cost of cross-frame attention by fusing redundant tokens in unimportant background regions. Both techniques are readily applicable to a given video editing model \textit{without} retraining, and can drastically reduce its memory and computational cost. We evaluate our proposals on inversion-based and control-signal-based editing pipelines, and show a latency reduction up to 10x for a comparable synthesis quality.
Investigating Top-$k$ White-Box and Transferable Black-box Attack
Mar 30, 2022
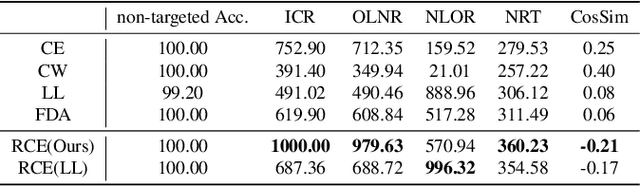


Existing works have identified the limitation of top-$1$ attack success rate (ASR) as a metric to evaluate the attack strength but exclusively investigated it in the white-box setting, while our work extends it to a more practical black-box setting: transferable attack. It is widely reported that stronger I-FGSM transfers worse than simple FGSM, leading to a popular belief that transferability is at odds with the white-box attack strength. Our work challenges this belief with empirical finding that stronger attack actually transfers better for the general top-$k$ ASR indicated by the interest class rank (ICR) after attack. For increasing the attack strength, with an intuitive interpretation of the logit gradient from the geometric perspective, we identify that the weakness of the commonly used losses lie in prioritizing the speed to fool the network instead of maximizing its strength. To this end, we propose a new normalized CE loss that guides the logit to be updated in the direction of implicitly maximizing its rank distance from the ground-truth class. Extensive results in various settings have verified that our proposed new loss is simple yet effective for top-$k$ attack. Code is available at: \url{https://bit.ly/3uCiomP}
Adversarial Robustness Comparison of Vision Transformer and MLP-Mixer to CNNs
Oct 11, 2021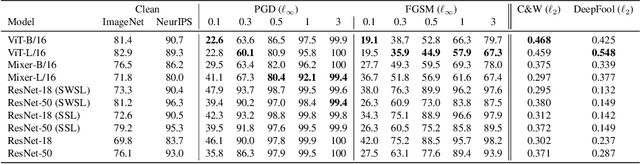


Convolutional Neural Networks (CNNs) have become the de facto gold standard in computer vision applications in the past years. Recently, however, new model architectures have been proposed challenging the status quo. The Vision Transformer (ViT) relies solely on attention modules, while the MLP-Mixer architecture substitutes the self-attention modules with Multi-Layer Perceptrons (MLPs). Despite their great success, CNNs have been widely known to be vulnerable to adversarial attacks, causing serious concerns for security-sensitive applications. Thus, it is critical for the community to know whether the newly proposed ViT and MLP-Mixer are also vulnerable to adversarial attacks. To this end, we empirically evaluate their adversarial robustness under several adversarial attack setups and benchmark them against the widely used CNNs. Overall, we find that the two architectures, especially ViT, are more robust than their CNN models. Using a toy example, we also provide empirical evidence that the lower adversarial robustness of CNNs can be partially attributed to their shift-invariant property. Our frequency analysis suggests that the most robust ViT architectures tend to rely more on low-frequency features compared with CNNs. Additionally, we have an intriguing finding that MLP-Mixer is extremely vulnerable to universal adversarial perturbations.
Universal Adversarial Training with Class-Wise Perturbations
Apr 07, 2021
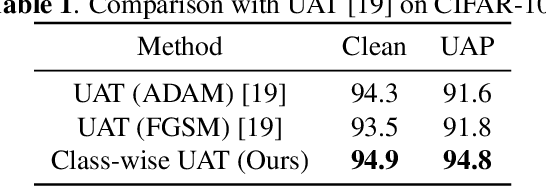

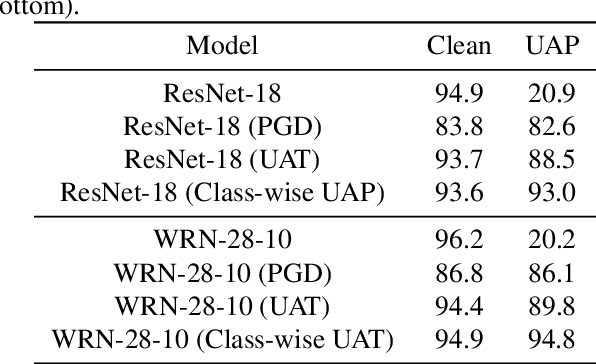
Despite their overwhelming success on a wide range of applications, convolutional neural networks (CNNs) are widely recognized to be vulnerable to adversarial examples. This intriguing phenomenon led to a competition between adversarial attacks and defense techniques. So far, adversarial training is the most widely used method for defending against adversarial attacks. It has also been extended to defend against universal adversarial perturbations (UAPs). The SOTA universal adversarial training (UAT) method optimizes a single perturbation for all training samples in the mini-batch. In this work, we find that a UAP does not attack all classes equally. Inspired by this observation, we identify it as the source of the model having unbalanced robustness. To this end, we improve the SOTA UAT by proposing to utilize class-wise UAPs during adversarial training. On multiple benchmark datasets, our class-wise UAT leads superior performance for both clean accuracy and adversarial robustness against universal attack.
A Survey On Universal Adversarial Attack
Mar 02, 2021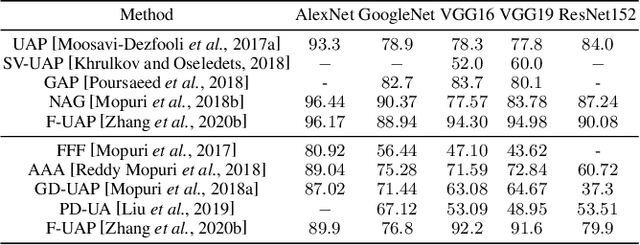
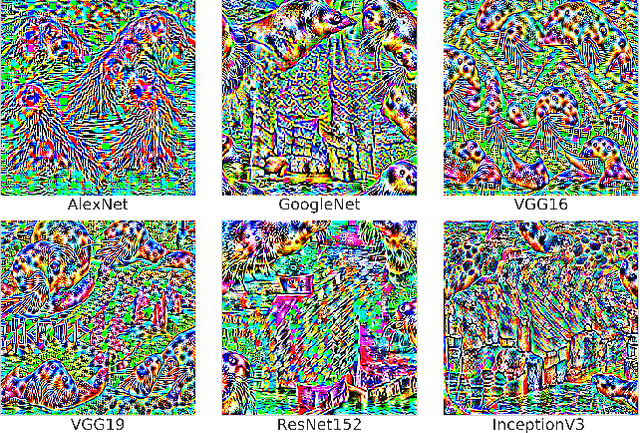
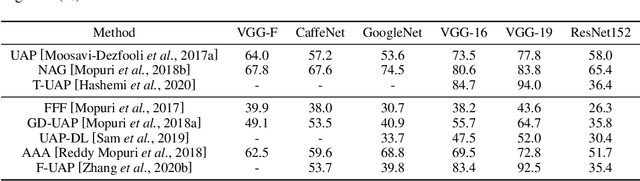
Deep neural networks (DNNs) have demonstrated remarkable performance for various applications, meanwhile, they are widely known to be vulnerable to the attack of adversarial perturbations. This intriguing phenomenon has attracted significant attention in machine learning and what might be more surprising to the community is the existence of universal adversarial perturbations (UAPs), i.e. a single perturbation to fool the target DNN for most images. The advantage of UAP is that it can be generated beforehand and then be applied on-the-fly during the attack. With the focus on UAP against deep classifiers, this survey summarizes the recent progress on universal adversarial attacks, discussing the challenges from both the attack and defense sides, as well as the reason for the existence of UAP. Additionally, universal attacks in a wide range of applications beyond deep classification are also covered.
Universal Adversarial Perturbations Through the Lens of Deep Steganography: Towards A Fourier Perspective
Feb 12, 2021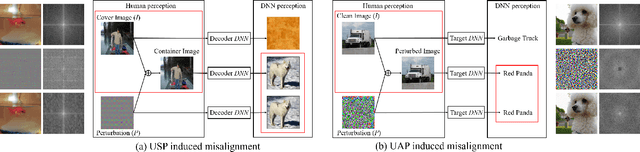

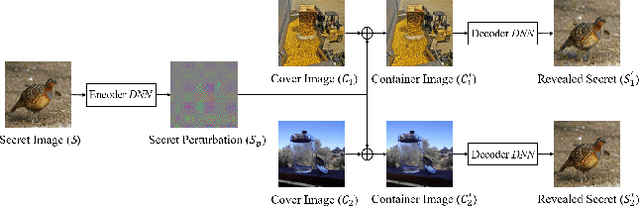

The booming interest in adversarial attacks stems from a misalignment between human vision and a deep neural network (DNN), i.e. a human imperceptible perturbation fools the DNN. Moreover, a single perturbation, often called universal adversarial perturbation (UAP), can be generated to fool the DNN for most images. A similar misalignment phenomenon has recently also been observed in the deep steganography task, where a decoder network can retrieve a secret image back from a slightly perturbed cover image. We attempt explaining the success of both in a unified manner from the Fourier perspective. We perform task-specific and joint analysis and reveal that (a) frequency is a key factor that influences their performance based on the proposed entropy metric for quantifying the frequency distribution; (b) their success can be attributed to a DNN being highly sensitive to high-frequency content. We also perform feature layer analysis for providing deep insight on model generalization and robustness. Additionally, we propose two new variants of universal perturbations: (1) Universal Secret Adversarial Perturbation (USAP) that simultaneously achieves attack and hiding; (2) high-pass UAP (HP-UAP) that is less visible to the human eye.
Towards Robust Data Hiding Against (JPEG) Compression: A Pseudo-Differentiable Deep Learning Approach
Dec 30, 2020
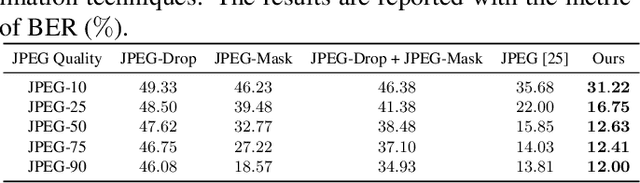
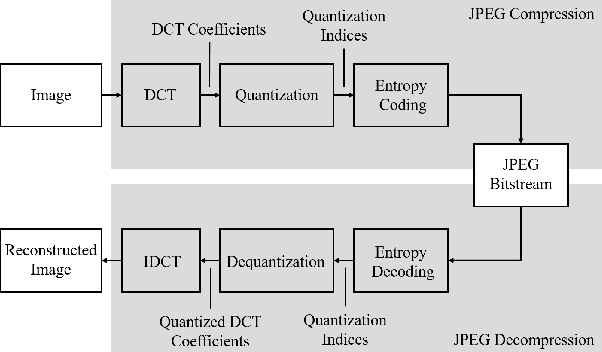

Data hiding is one widely used approach for protecting authentication and ownership. Most multimedia content like images and videos are transmitted or saved in the compressed form. This kind of lossy compression, such as JPEG, can destroy the hidden data, which raises the need of robust data hiding. It is still an open challenge to achieve the goal of data hiding that can be against these compressions. Recently, deep learning has shown large success in data hiding, while non-differentiability of JPEG makes it challenging to train a deep pipeline for improving robustness against lossy compression. The existing SOTA approaches replace the non-differentiable parts with differentiable modules that perform similar operations. Multiple limitations exist: (a) large engineering effort; (b) requiring a white-box knowledge of compression attacks; (c) only works for simple compression like JPEG. In this work, we propose a simple yet effective approach to address all the above limitations at once. Beyond JPEG, our approach has been shown to improve robustness against various image and video lossy compression algorithms.