 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeodragon: Mobile Video Generation using Diffusion Transformer
Nov 08, 2025We introduce Neodragon, a text-to-video system capable of generating 2s (49 frames @24 fps) videos at the 640x1024 resolution directly on a Qualcomm Hexagon NPU in a record 6.7s (7 FPS). Differing from existing transformer-based offline text-to-video generation models, Neodragon is the first to have been specifically optimised for mobile hardware to achieve efficient and high-fidelity video synthesis. We achieve this through four key technical contributions: (1) Replacing the original large 4.762B T5xxl Text-Encoder with a much smaller 0.2B DT5 (DistilT5) with minimal quality loss, enabled through a novel Text-Encoder Distillation procedure. (2) Proposing an Asymmetric Decoder Distillation approach allowing us to replace the native codec-latent-VAE decoder with a more efficient one, without disturbing the generative latent-space of the generation pipeline. (3) Pruning of MMDiT blocks within the denoiser backbone based on their relative importance, with recovery of original performance through a two-stage distillation process. (4) Reducing the NFE (Neural Functional Evaluation) requirement of the denoiser by performing step distillation using DMD adapted for pyramidal flow-matching, thereby substantially accelerating video generation. When paired with an optimised SSD1B first-frame image generator and QuickSRNet for 2x super-resolution, our end-to-end Neodragon system becomes a highly parameter (4.945B full model), memory (3.5GB peak RAM usage), and runtime (6.7s E2E latency) efficient mobile-friendly model, while achieving a VBench total score of 81.61. By enabling low-cost, private, and on-device text-to-video synthesis, Neodragon democratizes AI-based video content creation, empowering creators to generate high-quality videos without reliance on cloud services. Code and model will be made publicly available at our website: https://qualcomm-ai-research.github.io/neodragon
Mobile Video Diffusion
Dec 10, 2024Video diffusion models have achieved impressive realism and controllability but are limited by high computational demands, restricting their use on mobile devices. This paper introduces the first mobile-optimized video diffusion model. Starting from a spatio-temporal UNet from Stable Video Diffusion (SVD), we reduce memory and computational cost by reducing the frame resolution, incorporating multi-scale temporal representations, and introducing two novel pruning schema to reduce the number of channels and temporal blocks. Furthermore, we employ adversarial finetuning to reduce the denoising to a single step. Our model, coined as MobileVD, is 523x more efficient (1817.2 vs. 4.34 TFLOPs) with a slight quality drop (FVD 149 vs. 171), generating latents for a 14x512x256 px clip in 1.7 seconds on a Xiaomi-14 Pro. Our results are available at https://qualcomm-ai-research.github.io/mobile-video-diffusion/
MoViE: Mobile Diffusion for Video Editing
Dec 09, 2024Recent progress in diffusion-based video editing has shown remarkable potential for practical applications. However, these methods remain prohibitively expensive and challenging to deploy on mobile devices. In this study, we introduce a series of optimizations that render mobile video editing feasible. Building upon the existing image editing model, we first optimize its architecture and incorporate a lightweight autoencoder. Subsequently, we extend classifier-free guidance distillation to multiple modalities, resulting in a threefold on-device speedup. Finally, we reduce the number of sampling steps to one by introducing a novel adversarial distillation scheme which preserves the controllability of the editing process. Collectively, these optimizations enable video editing at 12 frames per second on mobile devices, while maintaining high quality. Our results are available at https://qualcomm-ai-research.github.io/mobile-video-editing/
Top-Down Networks: A coarse-to-fine reimagination of CNNs
Apr 16, 2020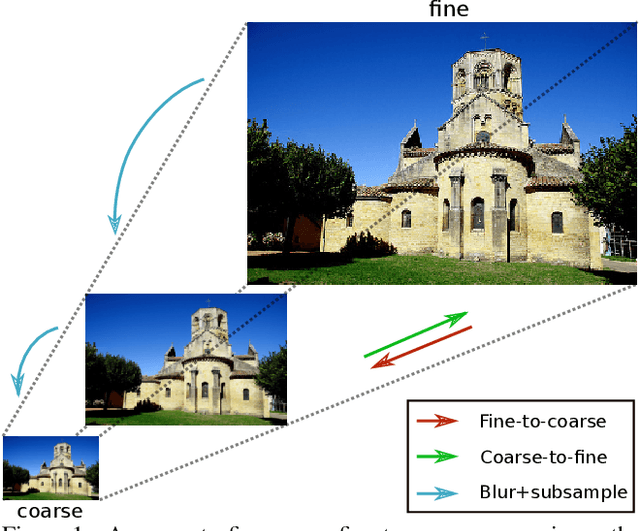



Biological vision adopts a coarse-to-fine information processing pathway, from initial visual detection and binding of salient features of a visual scene, to the enhanced and preferential processing given relevant stimuli. On the contrary, CNNs employ a fine-to-coarse processing, moving from local, edge-detecting filters to more global ones extracting abstract representations of the input. In this paper we reverse the feature extraction part of standard bottom-up architectures and turn them upside-down: We propose top-down networks. Our proposed coarse-to-fine pathway, by blurring higher frequency information and restoring it only at later stages, offers a line of defence against adversarial attacks that introduce high frequency noise. Moreover, since we increase image resolution with depth, the high resolution of the feature map in the final convolutional layer contributes to the explainability of the network's decision making process. This favors object-driven decisions over context driven ones, and thus provides better localized class activation maps. This paper offers empirical evidence for the applicability of the top-down resolution processing to various existing architectures on multiple visual tasks.