 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-Down Networks: A coarse-to-fine reimagination of CNNs
Paper and Code
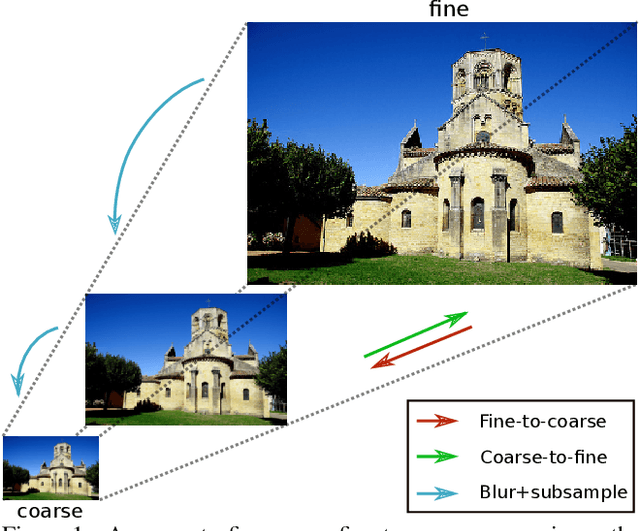



Biological vision adopts a coarse-to-fine information processing pathway, from initial visual detection and binding of salient features of a visual scene, to the enhanced and preferential processing given relevant stimuli. On the contrary, CNNs employ a fine-to-coarse processing, moving from local, edge-detecting filters to more global ones extracting abstract representations of the input. In this paper we reverse the feature extraction part of standard bottom-up architectures and turn them upside-down: We propose top-down networks. Our proposed coarse-to-fine pathway, by blurring higher frequency information and restoring it only at later stages, offers a line of defence against adversarial attacks that introduce high frequency noise. Moreover, since we increase image resolution with depth, the high resolution of the feature map in the final convolutional layer contributes to the explainability of the network's decision making process. This favors object-driven decisions over context driven ones, and thus provides better localized class activation maps. This paper offers empirical evidence for the applicability of the top-down resolution processing to various existing architectures on multiple visual tasks.