 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Video Diffusion
Dec 10, 2024



Video diffusion models have achieved impressive realism and controllability but are limited by high computational demands, restricting their use on mobile devices. This paper introduces the first mobile-optimized video diffusion model. Starting from a spatio-temporal UNet from Stable Video Diffusion (SVD), we reduce memory and computational cost by reducing the frame resolution, incorporating multi-scale temporal representations, and introducing two novel pruning schema to reduce the number of channels and temporal blocks. Furthermore, we employ adversarial finetuning to reduce the denoising to a single step. Our model, coined as MobileVD, is 523x more efficient (1817.2 vs. 4.34 TFLOPs) with a slight quality drop (FVD 149 vs. 171), generating latents for a 14x512x256 px clip in 1.7 seconds on a Xiaomi-14 Pro. Our results are available at https://qualcomm-ai-research.github.io/mobile-video-diffusion/
MoViE: Mobile Diffusion for Video Editing
Dec 09, 2024



Recent progress in diffusion-based video editing has shown remarkable potential for practical applications. However, these methods remain prohibitively expensive and challenging to deploy on mobile devices. In this study, we introduce a series of optimizations that render mobile video editing feasible. Building upon the existing image editing model, we first optimize its architecture and incorporate a lightweight autoencoder. Subsequently, we extend classifier-free guidance distillation to multiple modalities, resulting in a threefold on-device speedup. Finally, we reduce the number of sampling steps to one by introducing a novel adversarial distillation scheme which preserves the controllability of the editing process. Collectively, these optimizations enable video editing at 12 frames per second on mobile devices, while maintaining high quality. Our results are available at https://qualcomm-ai-research.github.io/mobile-video-editing/
Clockwork Diffusion: Efficient Generation With Model-Step Distillation
Dec 13, 2023



This work aims to improve the efficiency of text-to-image diffusion models. While diffusion models use computationally expensive UNet-based denoising operations in every generation step, we identify that not all operations are equally relevant for the final output quality. In particular, we observe that UNet layers operating on high-res feature maps are relatively sensitive to small perturbations. In contrast, low-res feature maps influence the semantic layout of the final image and can often be perturbed with no noticeable change in the output. Based on this observation, we propose Clockwork Diffusion, a method that periodically reuses computation from preceding denoising steps to approximate low-res feature maps at one or more subsequent steps. For multiple baselines, and for both text-to-image generation and image editing, we demonstrate that Clockwork leads to comparable or improved perceptual scores with drastically reduced computational complexity. As an example, for Stable Diffusion v1.5 with 8 DPM++ steps we save 32% of FLOPs with negligible FID and CLIP change.
Skip-Attention: Improving Vision Transformers by Paying Less Attention
Jan 17, 2023



This work aims to improve the efficiency of vision transformers (ViT). While ViTs use computationally expensive self-attention operations in every layer, we identify that these operations are highly correlated across layers -- a key redundancy that causes unnecessary computations. Based on this observation, we propose SkipAt, a method to reuse self-attention computation from preceding layers to approximate attention at one or more subsequent layers. To ensure that reusing self-attention blocks across layers does not degrade the performance, we introduce a simple parametric function, which outperforms the baseline transformer's performance while running computationally faster. We show the effectiveness of our method in image classification and self-supervised learning on ImageNet-1K, semantic segmentation on ADE20K, image denoising on SIDD, and video denoising on DAVIS. We achieve improved throughput at the same-or-higher accuracy levels in all these tasks.
SALISA: Saliency-based Input Sampling for Efficient Video Object Detection
Apr 05, 2022
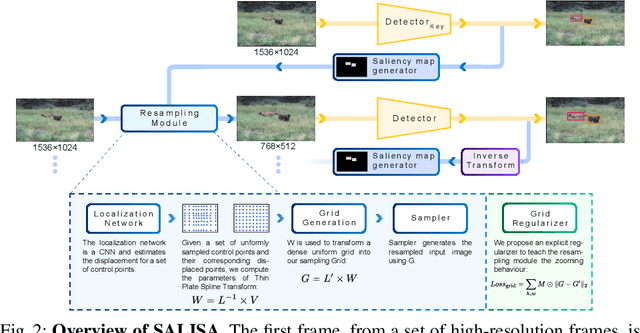
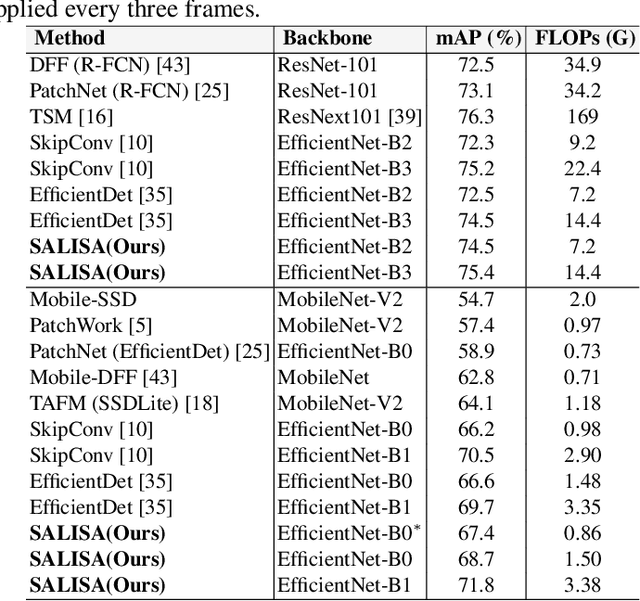

High-resolution images are widely adopted for high-performance object detection in videos. However, processing high-resolution inputs comes with high computation costs, and naive down-sampling of the input to reduce the computation costs quickly degrades the detection performance. In this paper, we propose SALISA, a novel non-uniform SALiency-based Input SAmpling technique for video object detection that allows for heavy down-sampling of unimportant background regions while preserving the fine-grained details of a high-resolution image. The resulting image is spatially smaller, leading to reduced computational costs while enabling a performance comparable to a high-resolution input. To achieve this, we propose a differentiable resampling module based on a thin plate spline spatial transformer network (TPS-STN). This module is regularized by a novel loss to provide an explicit supervision signal to learn to "magnify" salient regions. We report state-of-the-art results in the low compute regime on the ImageNet-VID and UA-DETRAC video object detection datasets. We demonstrate that on both datasets, the mAP of an EfficientDet-D1 (EfficientDet-D2) gets on par with EfficientDet-D2 (EfficientDet-D3) at a much lower computational cost. We also show that SALISA significantly improves the detection of small objects. In particular, SALISA with an EfficientDet-D1 detector improves the detection of small objects by $77\%$, and remarkably also outperforms EfficientDetD3 baseline.
FrameExit: Conditional Early Exiting for Efficient Video Recognition
Apr 27, 2021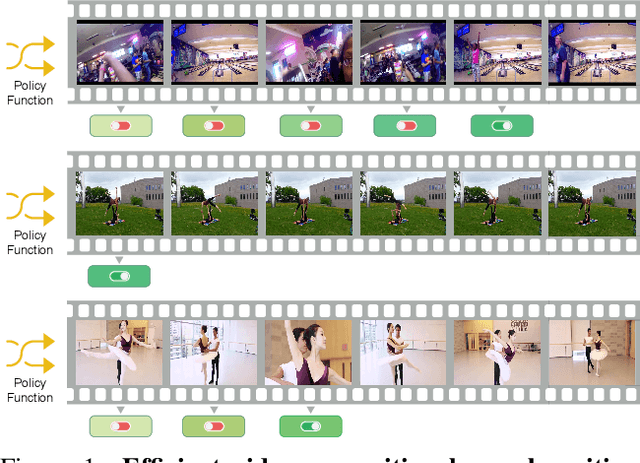
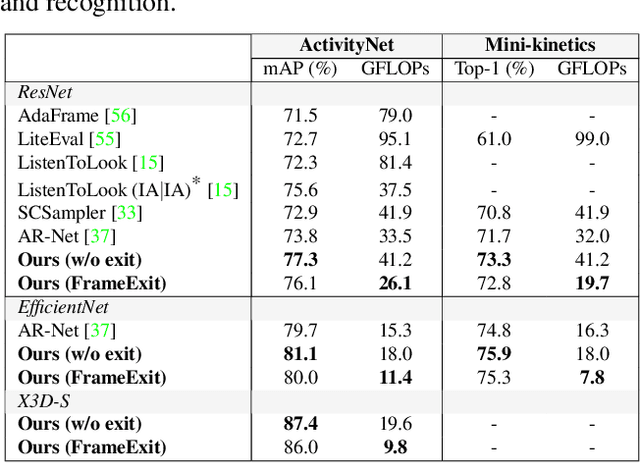
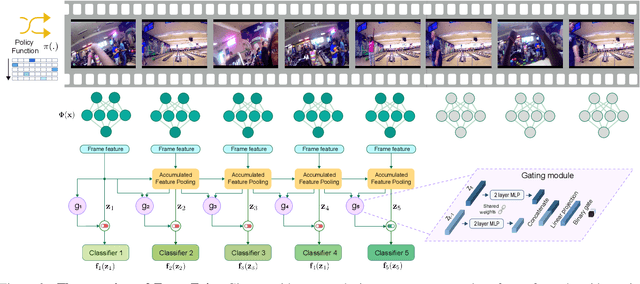
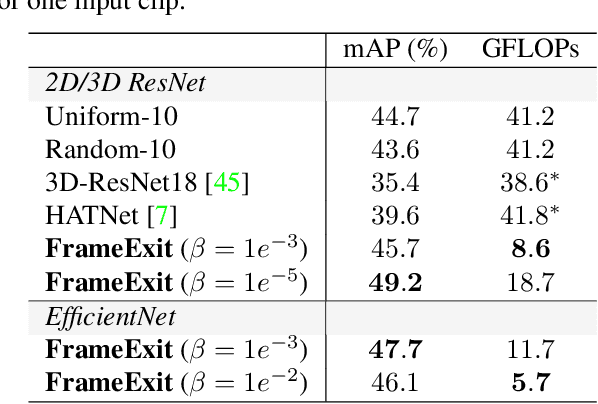
In this paper, we propose a conditional early exiting framework for efficient video recognition. While existing works focus on selecting a subset of salient frames to reduce the computation costs, we propose to use a simple sampling strategy combined with conditional early exiting to enable efficient recognition. Our model automatically learns to process fewer frames for simpler videos and more frames for complex ones. To achieve this, we employ a cascade of gating modules to automatically determine the earliest point in processing where an inference is sufficiently reliable. We generate on-the-fly supervision signals to the gates to provide a dynamic trade-off between accuracy and computational cost. Our proposed model outperforms competing methods on three large-scale video benchmarks. In particular, on ActivityNet1.3 and mini-kinetics, we outperform the state-of-the-art efficient video recognition methods with 1.3$\times$ and 2.1$\times$ less GFLOPs, respectively. Additionally, our method sets a new state of the art for efficient video understanding on the HVU benchmark.
Video Time: Properties, Encoders and Evaluation
Jul 18, 2018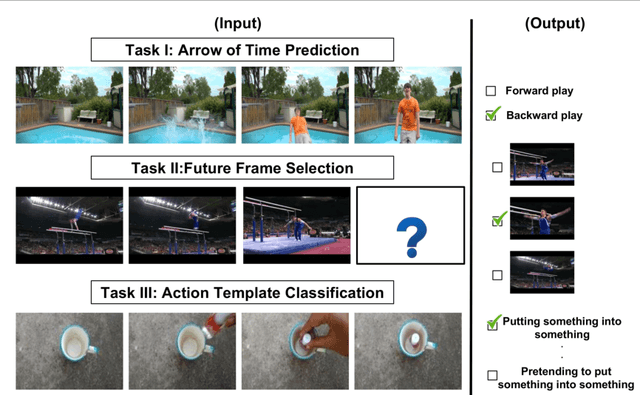

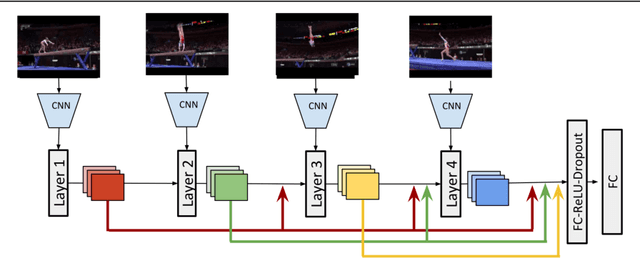
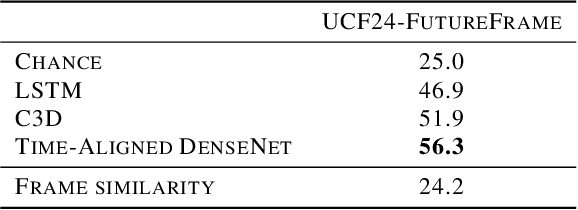
Time-aware encoding of frame sequences in a video is a fundamental problem in video understanding. While many attempted to model time in videos, an explicit study on quantifying video time is missing. To fill this lacuna, we aim to evaluate video time explicitly. We describe three properties of video time, namely a) temporal asymmetry, b)temporal continuity and c) temporal causality. Based on each we formulate a task able to quantify the associated property. This allows assessing the effectiveness of modern video encoders, like C3D and LSTM, in their ability to model time. Our analysis provides insights about existing encoders while also leading us to propose a new video time encoder, which is better suited for the video time recognition tasks than C3D and LSTM. We believe the proposed meta-analysis can provide a reasonable baseline to assess video time encoders on equal grounds on a set of temporal-aware tasks.
Actor and Action Video Segmentation from a Sentence
Mar 20, 2018
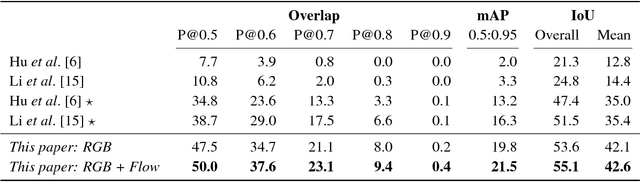

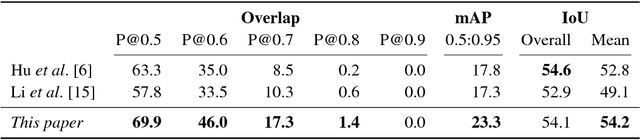
This paper strives for pixel-level segmentation of actors and their actions in video content. Different from existing works, which all learn to segment from a fixed vocabulary of actor and action pairs, we infer the segmentation from a natural language input sentence. This allows to distinguish between fine-grained actors in the same super-category, identify actor and action instances, and segment pairs that are outside of the actor and action vocabulary. We propose a fully-convolutional model for pixel-level actor and action segmentation using an encoder-decoder architecture optimized for video. To show the potential of actor and action video segmentation from a sentence, we extend two popular actor and action datasets with more than 7,500 natural language descriptions. Experiments demonstrate the quality of the sentence-guided segmentations, the generalization ability of our model, and its advantage for traditional actor and action segmentation compared to the state-of-the-art.
Online Action Detection
Aug 30, 2016
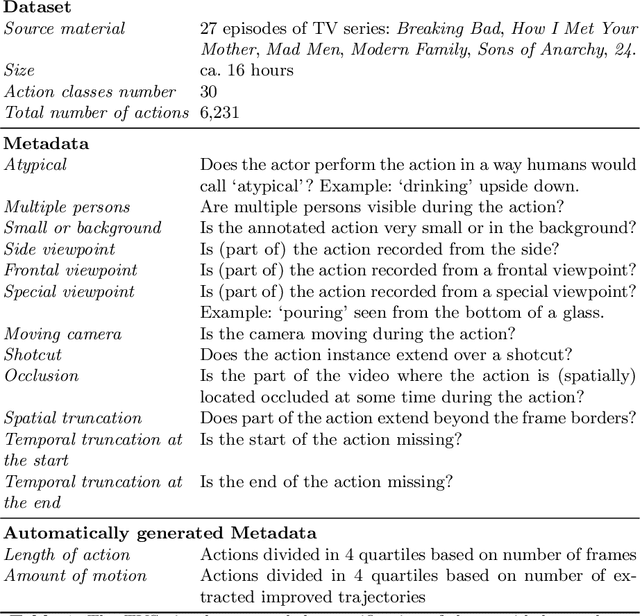


In online action detection, the goal is to detect the start of an action in a video stream as soon as it happens. For instance, if a child is chasing a ball, an autonomous car should recognize what is going on and respond immediately. This is a very challenging problem for four reasons. First, only partial actions are observed. Second, there is a large variability in negative data. Third, the start of the action is unknown, so it is unclear over what time window the information should be integrated. Finally, in real world data, large within-class variability exists. This problem has been addressed before, but only to some extent. Our contributions to online action detection are threefold. First, we introduce a realistic dataset composed of 27 episodes from 6 popular TV series. The dataset spans over 16 hours of footage annotated with 30 action classes, totaling 6,231 action instances. Second, we analyze and compare various baseline methods, showing this is a challenging problem for which none of the methods provides a good solution. Third, we analyze the change in performance when there is a variation in viewpoint, occlusion, truncation, etc. We introduce an evaluation protocol for fair comparison. The dataset, the baselines and the models will all be made publicly available to encourage (much needed) further research on online action detection on realistic data.
DeepProposals: Hunting Objects and Actions by Cascading Deep Convolutional Layers
Jun 15, 2016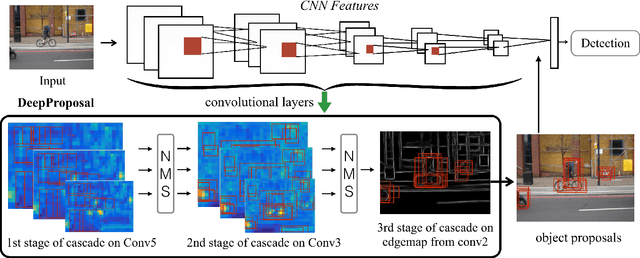

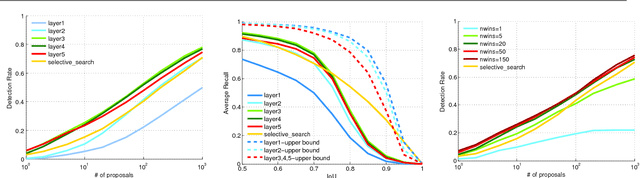

In this paper, a new method for generating object and action proposals in images and videos is proposed. It builds on activations of different convolutional layers of a pretrained CNN, combining the localization accuracy of the early layers with the high informative-ness (and hence recall) of the later layers. To this end, we build an inverse cascade that, going backward from the later to the earlier convolutional layers of the CNN, selects the most promising locations and refines them in a coarse-to-fine manner. The method is efficient, because i) it re-uses the same features extracted for detection, ii) it aggregates features using integral images, and iii) it avoids a dense evaluation of the proposals thanks to the use of the inverse coarse-to-fine cascade. The method is also accurate. We show that our DeepProposals outperform most of the previously proposed object proposal and action proposal approaches and, when plugged into a CNN-based object detector, produce state-of-the-art detection performance.