 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALISA: Saliency-based Input Sampling for Efficient Video Object Detection
Paper and Code
Apr 05, 2022
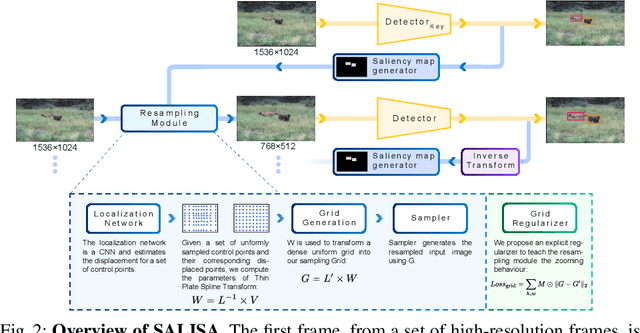
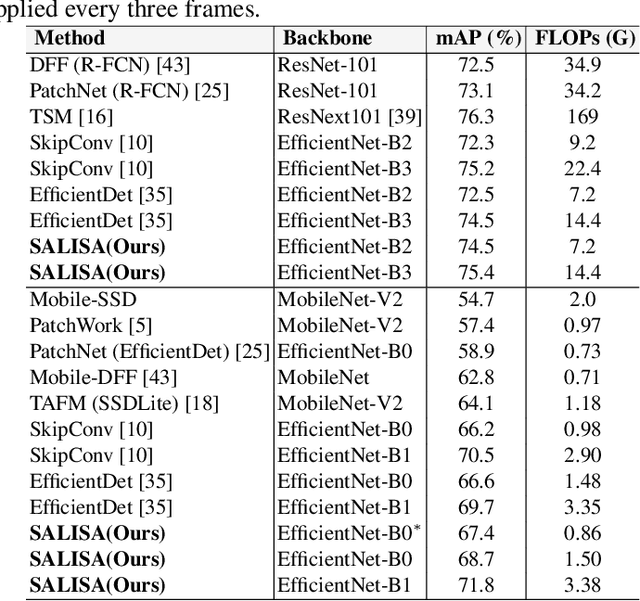

High-resolution images are widely adopted for high-performance object detection in videos. However, processing high-resolution inputs comes with high computation costs, and naive down-sampling of the input to reduce the computation costs quickly degrades the detection performance. In this paper, we propose SALISA, a novel non-uniform SALiency-based Input SAmpling technique for video object detection that allows for heavy down-sampling of unimportant background regions while preserving the fine-grained details of a high-resolution image. The resulting image is spatially smaller, leading to reduced computational costs while enabling a performance comparable to a high-resolution input. To achieve this, we propose a differentiable resampling module based on a thin plate spline spatial transformer network (TPS-STN). This module is regularized by a novel loss to provide an explicit supervision signal to learn to "magnify" salient regions. We report state-of-the-art results in the low compute regime on the ImageNet-VID and UA-DETRAC video object detection datasets. We demonstrate that on both datasets, the mAP of an EfficientDet-D1 (EfficientDet-D2) gets on par with EfficientDet-D2 (EfficientDet-D3) at a much lower computational cost. We also show that SALISA significantly improves the detection of small objects. In particular, SALISA with an EfficientDet-D1 detector improves the detection of small objects by $77\%$, and remarkably also outperforms EfficientDetD3 baseline.