 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepProposals: Hunting Objects and Actions by Cascading Deep Convolutional Layers
Paper and Code
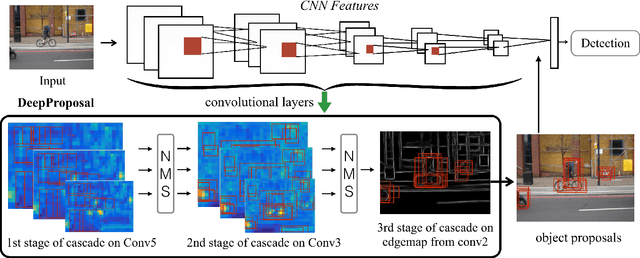

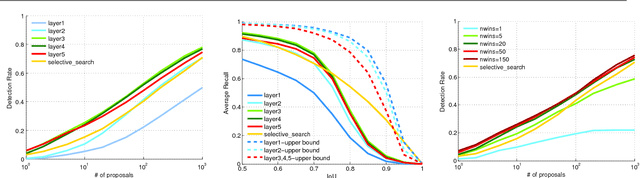

In this paper, a new method for generating object and action proposals in images and videos is proposed. It builds on activations of different convolutional layers of a pretrained CNN, combining the localization accuracy of the early layers with the high informative-ness (and hence recall) of the later layers. To this end, we build an inverse cascade that, going backward from the later to the earlier convolutional layers of the CNN, selects the most promising locations and refines them in a coarse-to-fine manner. The method is efficient, because i) it re-uses the same features extracted for detection, ii) it aggregates features using integral images, and iii) it avoids a dense evaluation of the proposals thanks to the use of the inverse coarse-to-fine cascade. The method is also accurate. We show that our DeepProposals outperform most of the previously proposed object proposal and action proposal approaches and, when plugged into a CNN-based object detector, produce state-of-the-art detection performance.