 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV-MLM: Bridging Multi-View Mammography and Language for Breast Cancer Diagnosis and Risk Prediction
Oct 30, 2025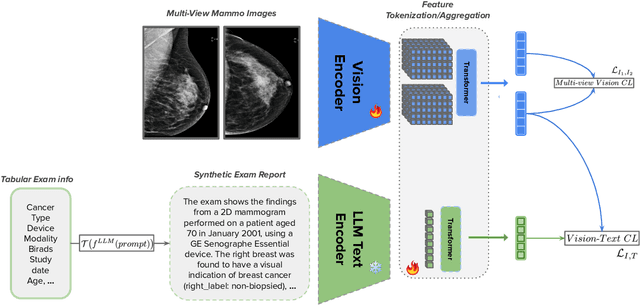
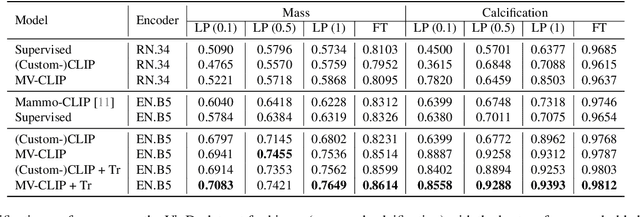


Large annotated datasets are essential for training robust Computer-Aided Diagnosis (CAD) models for breast cancer detection or risk prediction. However, acquiring such datasets with fine-detailed annotation is both costly and time-consuming. Vision-Language Models (VLMs), such as CLIP, which are pre-trained on large image-text pairs, offer a promising solution by enhancing robustness and data efficiency in medical imaging tasks. This paper introduces a novel Multi-View Mammography and Language Model for breast cancer classification and risk prediction, trained on a dataset of paired mammogram images and synthetic radiology reports. Our MV-MLM leverages multi-view supervision to learn rich representations from extensive radiology data by employing cross-modal self-supervision across image-text pairs. This includes multiple views and the corresponding pseudo-radiology reports. We propose a novel joint visual-textual learning strategy to enhance generalization and accuracy performance over different data types and tasks to distinguish breast tissues or cancer characteristics(calcification, mass) and utilize these patterns to understand mammography images and predict cancer risk. We evaluated our method on both private and publicly available datasets, demonstrating that the proposed model achieves state-of-the-art performance in three classification tasks: (1) malignancy classification, (2) subtype classification, and (3) image-based cancer risk prediction. Furthermore, the model exhibits strong data efficiency, outperforming existing fully supervised or VLM baselines while trained on synthetic text reports and without the need for actual radiology reports.
T-SiamTPN: Temporal Siamese Transformer Pyramid Networks for Robust and Efficient UAV Tracking
Sep 16, 2025



Aerial object tracking remains a challenging task due to scale variations, dynamic backgrounds, clutter, and frequent occlusions. While most existing trackers emphasize spatial cues, they often overlook temporal dependencies, resulting in limited robustness in long-term tracking and under occlusion. Furthermore, correlation-based Siamese trackers are inherently constrained by the linear nature of correlation operations, making them ineffective against complex, non-linear appearance changes. To address these limitations, we introduce T-SiamTPN, a temporal-aware Siamese tracking framework that extends the SiamTPN architecture with explicit temporal modeling. Our approach incorporates temporal feature fusion and attention-based interactions, strengthening temporal consistency and enabling richer feature representations. These enhancements yield significant improvements over the baseline and achieve performance competitive with state-of-the-art trackers. Crucially, despite the added temporal modules, T-SiamTPN preserves computational efficiency. Deployed on the resource-constrained Jetson Nano, the tracker runs in real time at 7.1 FPS, demonstrating its suitability for real-world embedded applications without notable runtime overhead. Experimental results highlight substantial gains: compared to the baseline, T-SiamTPN improves success rate by 13.7% and precision by 14.7%. These findings underscore the importance of temporal modeling in Siamese tracking frameworks and establish T-SiamTPN as a strong and efficient solution for aerial object tracking. Code is available at: https://github.com/to/be/released
SelectiveKD: A semi-supervised framework for cancer detection in DBT through Knowledge Distillation and Pseudo-labeling
Sep 25, 2024When developing Computer Aided Detection (CAD) systems for Digital Breast Tomosynthesis (DBT), the complexity arising from the volumetric nature of the modality poses significant technical challenges for obtaining large-scale accurate annotations. Without access to large-scale annotations, the resulting model may not generalize to different domains. Given the costly nature of obtaining DBT annotations, how to effectively increase the amount of data used for training DBT CAD systems remains an open challenge. In this paper, we present SelectiveKD, a semi-supervised learning framework for building cancer detection models for DBT, which only requires a limited number of annotated slices to reach high performance. We achieve this by utilizing unlabeled slices available in a DBT stack through a knowledge distillation framework in which the teacher model provides a supervisory signal to the student model for all slices in the DBT volume. Our framework mitigates the potential noise in the supervisory signal from a sub-optimal teacher by implementing a selective dataset expansion strategy using pseudo labels. We evaluate our approach with a large-scale real-world dataset of over 10,000 DBT exams collected from multiple device manufacturers and locations. The resulting SelectiveKD process effectively utilizes unannotated slices from a DBT stack, leading to significantly improved cancer classification performance (AUC) and generalization performance.
Computation-Efficient Era: A Comprehensive Survey of State Space Models in Medical Image Analysis
Jun 05, 2024



Sequence modeling plays a vital role across various domains, with recurrent neural networks being historically the predominant method of performing these tasks. However, the emergence of transformers has altered this paradigm due to their superior performance. Built upon these advances, transformers have conjoined CNNs as two leading foundational models for learning visual representations. However, transformers are hindered by the $\mathcal{O}(N^2)$ complexity of their attention mechanisms, while CNNs lack global receptive fields and dynamic weight allocation. State Space Models (SSMs), specifically the \textit{\textbf{Mamba}} model with selection mechanisms and hardware-aware architecture, have garnered immense interest lately in sequential modeling and visual representation learning, challenging the dominance of transformers by providing infinite context lengths and offering substantial efficiency maintaining linear complexity in the input sequence. Capitalizing on the advances in computer vision, medical imaging has heralded a new epoch with Mamba models. Intending to help researchers navigate the surge, this survey seeks to offer an encyclopedic review of Mamba models in medical imaging. Specifically, we start with a comprehensive theoretical review forming the basis of SSMs, including Mamba architecture and its alternatives for sequence modeling paradigms in this context. Next, we offer a structured classification of Mamba models in the medical field and introduce a diverse categorization scheme based on their application, imaging modalities, and targeted organs. Finally, we summarize key challenges, discuss different future research directions of the SSMs in the medical domain, and propose several directions to fulfill the demands of this field. In addition, we have compiled the studies discussed in this paper along with their open-source implementations on our GitHub repository.
Temporally-Weighted Hierarchical Clustering for Unsupervised Action Segmentation
Mar 27, 2021

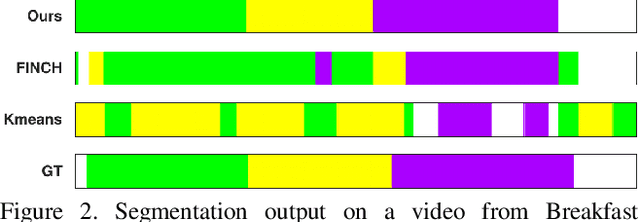
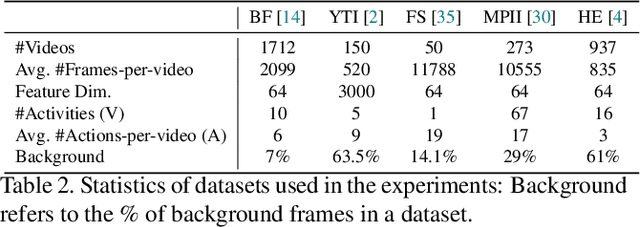
Action segmentation refers to inferring boundaries of semantically consistent visual concepts in videos and is an important requirement for many video understanding tasks. For this and other video understanding tasks, supervised approaches have achieved encouraging performance but require a high volume of detailed frame-level annotations. We present a fully automatic and unsupervised approach for segmenting actions in a video that does not require any training. Our proposal is an effective temporally-weighted hierarchical clustering algorithm that can group semantically consistent frames of the video. Our main finding is that representing a video with a 1-nearest neighbor graph by taking into account the time progression is sufficient to form semantically and temporally consistent clusters of frames where each cluster may represent some action in the video. Additionally, we establish strong unsupervised baselines for action segmentation and show significant performance improvements over published unsupervised methods on five challenging action segmentation datasets. Our code is available at https://github.com/ssarfraz/FINCH-Clustering/tree/master/TW-FINCH
3D CNNs with Adaptive Temporal Feature Resolutions
Nov 17, 2020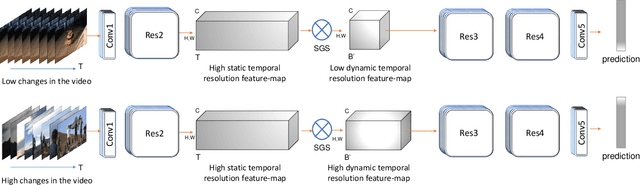


While state-of-the-art 3D Convolutional Neural Networks (CNN) achieve very good results on action recognition datasets, they are computationally very expensive and require many GFLOPs. While the GFLOPs of a 3D CNN can be decreased by reducing the temporal feature resolution within the network, there is no setting that is optimal for all input clips. In this work, we, therefore, introduce a differentiable Similarity Guided Sampling (SGS) module, which can be plugged into any existing 3D CNN architecture. SGS empowers 3D CNNs by learning the similarity of temporal features and grouping similar features together. As a result, the temporal feature resolution is not anymore static but it varies for each input video clip. By integrating SGS as an additional layer within current 3D CNNs, we can convert them into much more efficient 3D CNNs with adaptive temporal feature resolutions (ATFR). Our evaluations show that the proposed module improves the state-of-the-art by reducing the computational cost (GFLOPs)by half while preserving or even improving the accuracy. We evaluate our module by adding it to multiple state-of-the-art 3D CNNs on various datasets such as Kinetics-600, Kinetics-400, mini-Kinetics, Something-Something V2, UCF101, and HMDB51
Self-Supervised Ranking for Representation Learning
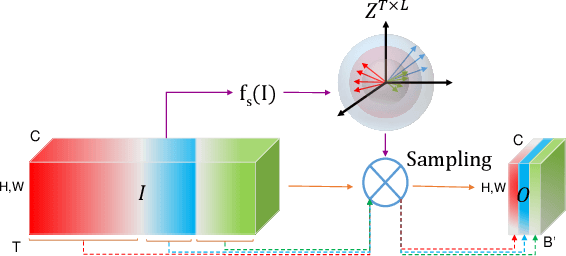
Oct 14, 2020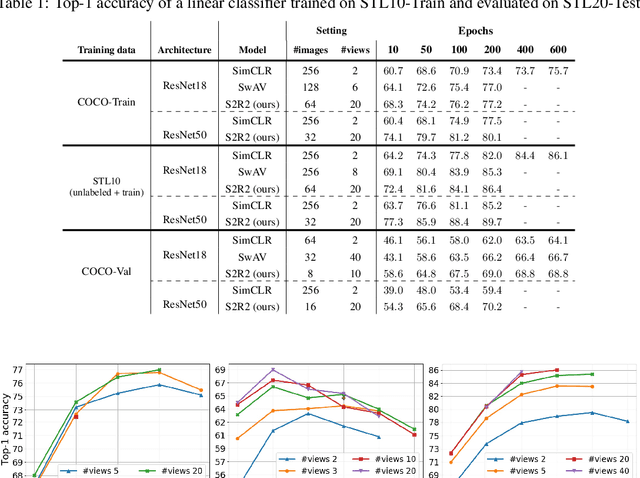
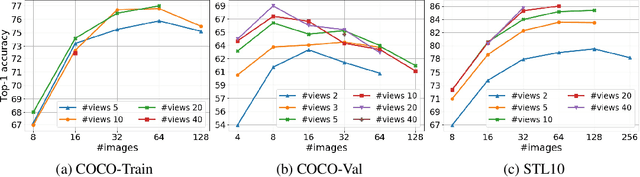
We present a new framework for self-supervised representation learning by positing it as a ranking problem in an image retrieval context on a large number of random views from random sets of images. Our work is based on two intuitive observations: first, a good representation of images must yield a high-quality image ranking in a retrieval task; second, we would expect random views of an image to be ranked closer to a reference view of that image than random views of other images. Hence, we model representation learning as a learning-to-rank problem in an image retrieval context, and train it by maximizing average precision (AP) for ranking. Specifically, given a mini-batch of images, we generate a large number of positive/negative samples and calculate a ranking loss term by separately treating each image view as a retrieval query. The new framework, dubbed S2R2, enables computing a global objective compared to the local objective in the popular contrastive learning framework calculated on pairs of views. A global objective leads S2R2 to faster convergence in terms of the number of epochs. In principle, by using a ranking criterion, we eliminate reliance on object-centered curated datasets (e.g., ImageNet). When trained on STL10 and MS-COCO, S2R2 outperforms SimCLR and performs on par with the state-of-the-art clustering-based contrastive learning model, SwAV, while being much simpler both conceptually and implementation-wise. Furthermore, when trained on a small subset of MS-COCO with fewer similar scenes, S2R2 significantly outperforms both SwAV and SimCLR. This indicates that S2R2 is potentially more effective on diverse scenes and decreases the need for a large training dataset for self-supervised learning.
Holistic Large Scale Video Understanding
Apr 25, 2019



Action recognition has been advanced in recent years by benchmarks with rich annotations. However, research is still mainly limited to human action or sports recognition - focusing on a highly specific video understanding task and thus leaving a significant gap towards describing the overall content of a video. We fill in this gap by presenting a large-scale "Holistic Video Understanding Dataset"~(HVU). HVU is organized hierarchically in a semantic taxonomy that focuses on multi-label and multi-task video understanding as a comprehensive problem that encompasses the recognition of multiple semantic aspects in the dynamic scene. HVU contains approx.~577k videos in total with 13M annotations for training and validation set spanning over {4378} classes. HVU encompasses semantic aspects defined on categories of scenes, objects, actions, events, attributes and concepts, which naturally captures the real-world scenarios. Further, we introduce a new spatio-temporal deep neural network architecture called "Holistic Appearance and Temporal Network"~(HATNet) that builds on fusing 2D and 3D architectures into one by combining intermediate representations of appearance and temporal cues. HATNet focuses on the multi-label and multi-task learning problem and is trained in an end-to-end manner. The experiments show that HATNet trained on HVU outperforms current state-of-the-art methods on challenging human action datasets: HMDB51, UCF101, and Kinetics. The dataset and codes will be made publicly available.
DynamoNet: Dynamic Action and Motion Network
Apr 25, 2019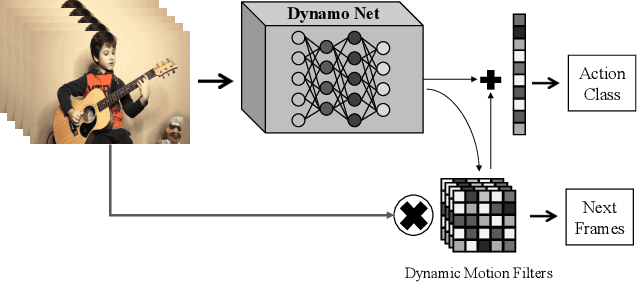
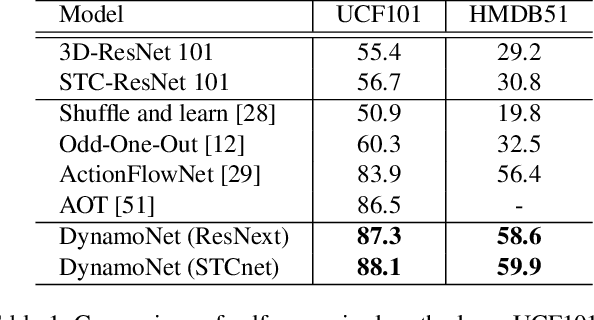
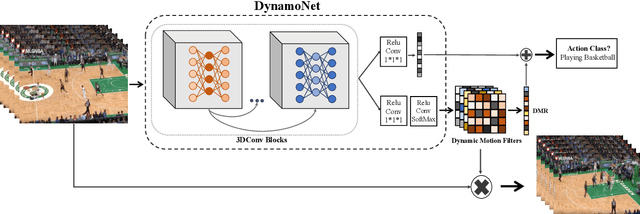
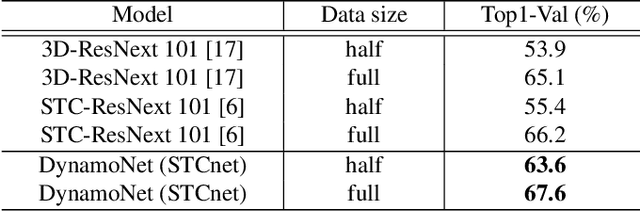
In this paper, we are interested in self-supervised learning the motion cues in videos using dynamic motion filters for a better motion representation to finally boost human action recognition in particular. Thus far, the vision community has focused on spatio-temporal approaches using standard filters, rather we here propose dynamic filters that adaptively learn the video-specific internal motion representation by predicting the short-term future frames. We name this new motion representation, as dynamic motion representation (DMR) and is embedded inside of 3D convolutional network as a new layer, which captures the visual appearance and motion dynamics throughout entire video clip via end-to-end network learning. Simultaneously, we utilize these motion representation to enrich video classification. We have designed the frame prediction task as an auxiliary task to empower the classification problem. With these overall objectives, to this end, we introduce a novel unified spatio-temporal 3D-CNN architecture (DynamoNet) that jointly optimizes the video classification and learning motion representation by predicting future frames as a multi-task learning problem. We conduct experiments on challenging human action datasets: Kinetics 400, UCF101, HMDB51. The experiments using the proposed DynamoNet show promising results on all the datasets.
Spatio-Temporal Channel Correlation Networks for Action Classification
Jun 25, 2018

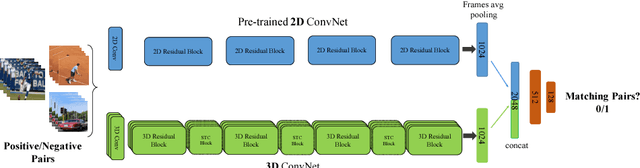

The work in this paper is driven by the question if spatio-temporal correlations are enough for 3D convolutional neural networks (CNN)? Most of the traditional 3D networks use local spatio-temporal features. We introduce a new block that models correlations between channels of a 3D CNN with respect to temporal and spatial features. This new block can be added as a residual unit to different parts of 3D CNNs. We name our novel block 'Spatio-Temporal Channel Correlation' (STC). By embedding this block to the current state-of-the-art architectures such as ResNext and ResNet, we improved the performance by 2-3\% on Kinetics dataset. Our experiments show that adding STC blocks to current state-of-the-art architectures outperforms the state-of-the-art methods on the HMDB51, UCF101 and Kinetics datasets. The other issue in training 3D CNNs is about training them from scratch with a huge labeled dataset to get a reasonable performance. So the knowledge learned in 2D CNNs is completely ignored. Another contribution in this work is a simple and effective technique to transfer knowledge from a pre-trained 2D CNN to a randomly initialized 3D CNN for a stable weight initialization. This allows us to significantly reduce the number of training samples for 3D CNNs. Thus, by fine-tuning this network, we beat the performance of generic and recent methods in 3D CNNs, which were trained on large video datasets, e.g. Sports-1M, and fine-tuned on the target datasets, e.g. HMDB51/UCF101.