 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Billion-scale semi-supervised learning for image classification
May 02, 2019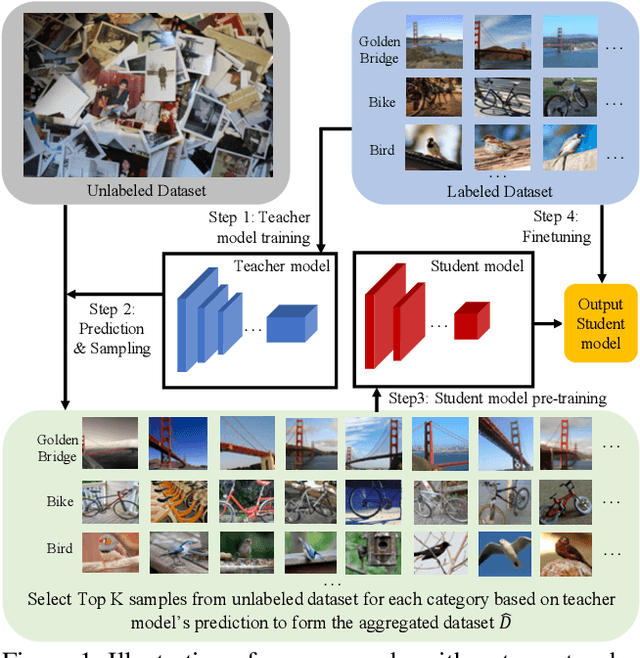

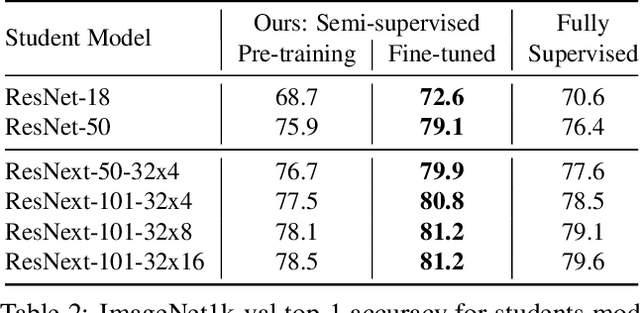
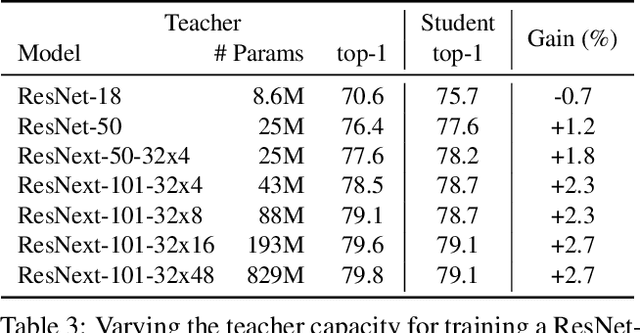
This paper presents a study of semi-supervised learning with large convolutional networks. We propose a pipeline, based on a teacher/student paradigm, that leverages a large collection of unlabelled images (up to 1 billion). Our main goal is to improve the performance for a given target architecture, like ResNet-50 or ResNext. We provide an extensive analysis of the success factors of our approach, which leads us to formulate some recommendations to produce high-accuracy models for image classification with semi-supervised learning. As a result, our approach brings important gains to standard architectures for image, video and fine-grained classification. For instance, by leveraging one billion unlabelled images, our learned vanilla ResNet-50 achieves 81.2% top-1 accuracy on the ImageNet benchmark.
Holistic Large Scale Video Understanding
Apr 25, 2019



Action recognition has been advanced in recent years by benchmarks with rich annotations. However, research is still mainly limited to human action or sports recognition - focusing on a highly specific video understanding task and thus leaving a significant gap towards describing the overall content of a video. We fill in this gap by presenting a large-scale "Holistic Video Understanding Dataset"~(HVU). HVU is organized hierarchically in a semantic taxonomy that focuses on multi-label and multi-task video understanding as a comprehensive problem that encompasses the recognition of multiple semantic aspects in the dynamic scene. HVU contains approx.~577k videos in total with 13M annotations for training and validation set spanning over {4378} classes. HVU encompasses semantic aspects defined on categories of scenes, objects, actions, events, attributes and concepts, which naturally captures the real-world scenarios. Further, we introduce a new spatio-temporal deep neural network architecture called "Holistic Appearance and Temporal Network"~(HATNet) that builds on fusing 2D and 3D architectures into one by combining intermediate representations of appearance and temporal cues. HATNet focuses on the multi-label and multi-task learning problem and is trained in an end-to-end manner. The experiments show that HATNet trained on HVU outperforms current state-of-the-art methods on challenging human action datasets: HMDB51, UCF101, and Kinetics. The dataset and codes will be made publicly available.
Exploring the Challenges towards Lifelong Fact Learning
Dec 26, 2018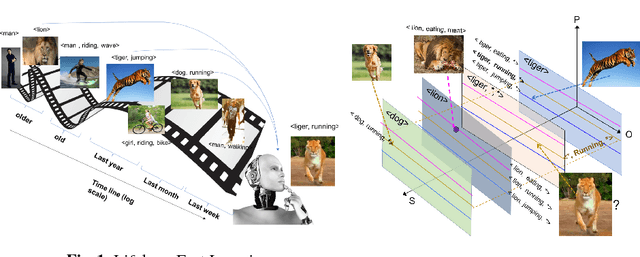
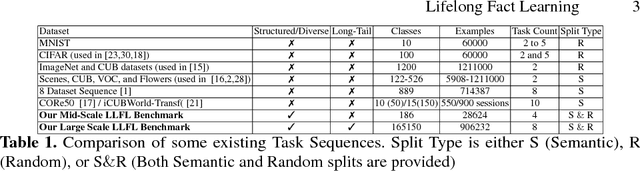
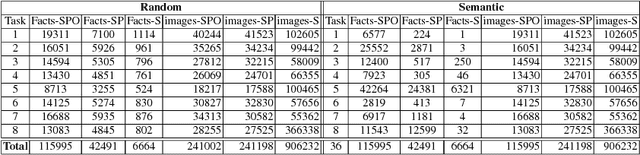
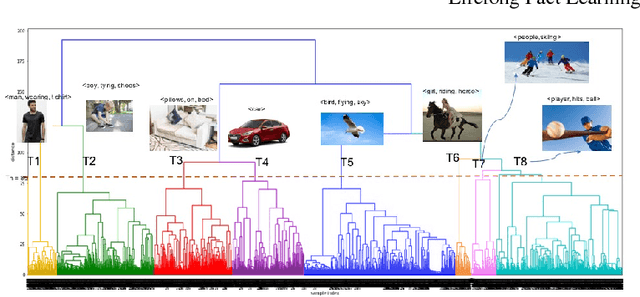
So far life-long learning (LLL) has been studied in relatively small-scale and relatively artificial setups. Here, we introduce a new large-scale alternative. What makes the proposed setup more natural and closer to human-like visual systems is threefold: First, we focus on concepts (or facts, as we call them) of varying complexity, ranging from single objects to more complex structures such as objects performing actions, and objects interacting with other objects. Second, as in real-world settings, our setup has a long-tail distribution, an aspect which has mostly been ignored in the LLL context. Third, facts across tasks may share structure (e.g., <person, riding, wave> and <dog, riding, wave>). Facts can also be semantically related (e.g., "liger" relates to seen categories like "tiger" and "lion"). Given the large number of possible facts, a LLL setup seems a natural choice. To avoid model size growing over time and to optimally exploit the semantic relations and structure, we combine it with a visual semantic embedding instead of discrete class labels. We adapt existing datasets with the properties mentioned above into new benchmarks, by dividing them semantically or randomly into disjoint tasks. This leads to two large-scale benchmarks with 906,232 images and 165,150 unique facts, on which we evaluate and analyze state-of-the-art LLL methods.
Large-Scale Visual Relationship Understanding
Sep 14, 2018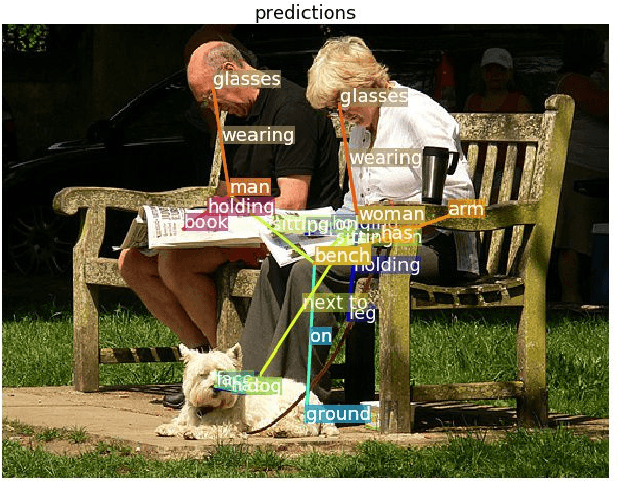

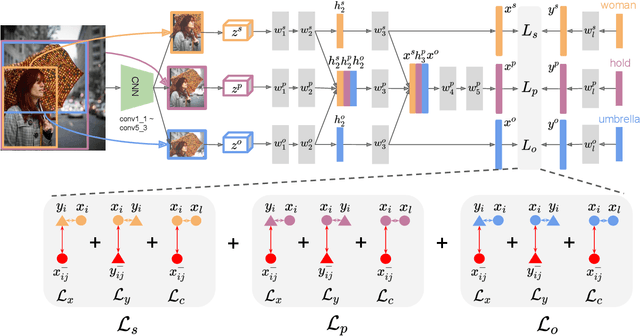
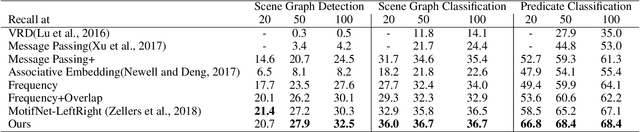
Large scale visual understanding is challenging, as it requires a model to handle the widely-spread and imbalanced distribution of <subject, relation, object> triples. In real-world scenarios with large numbers of objects and relations, some are seen very commonly while others are barely seen. We develop a new relationship detection model that embeds objects and relations into two vector spaces where both discriminative capability and semantic affinity are preserved. We learn both a visual and a semantic module that map features from the two modalities into a shared space, where matched pairs of features have to discriminate against those unmatched, but also maintain close distances to semantically similar ones. Benefiting from that, our model can achieve superior performance even when the visual entity categories scale up to more than 80,000, with extremely skewed class distribution. We demonstrate the efficacy of our model on a large and imbalanced benchmark based of Visual Genome that comprises 53,000+ objects and 29,000+ relations, a scale at which no previous work has ever been evaluated at. We show superiority of our model over carefully designed baselines on the original Visual Genome dataset with 80,000+ categories. We also show state-of-the-art performance on the VRD dataset and the scene graph dataset which is a subset of Visual Genome with 200 categories.
Detect-and-Track: Efficient Pose Estimation in Videos
May 02, 2018

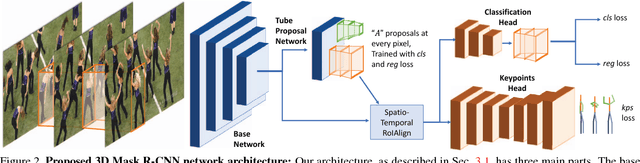

This paper addresses the problem of estimating and tracking human body keypoints in complex, multi-person video. We propose an extremely lightweight yet highly effective approach that builds upon the latest advancements in human detection and video understanding. Our method operates in two-stages: keypoint estimation in frames or short clips, followed by lightweight tracking to generate keypoint predictions linked over the entire video. For frame-level pose estimation we experiment with Mask R-CNN, as well as our own proposed 3D extension of this model, which leverages temporal information over small clips to generate more robust frame predictions. We conduct extensive ablative experiments on the newly released multi-person video pose estimation benchmark, PoseTrack, to validate various design choices of our model. Our approach achieves an accuracy of 55.2% on the validation and 51.8% on the test set using the Multi-Object Tracking Accuracy (MOTA) metric, and achieves state of the art performance on the ICCV 2017 PoseTrack keypoint tracking challenge.
Exploring the Limits of Weakly Supervised Pretraining
May 02, 2018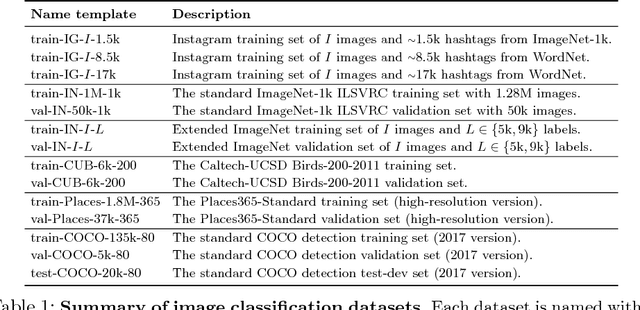
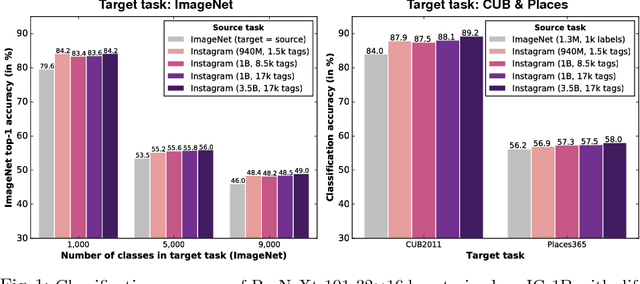
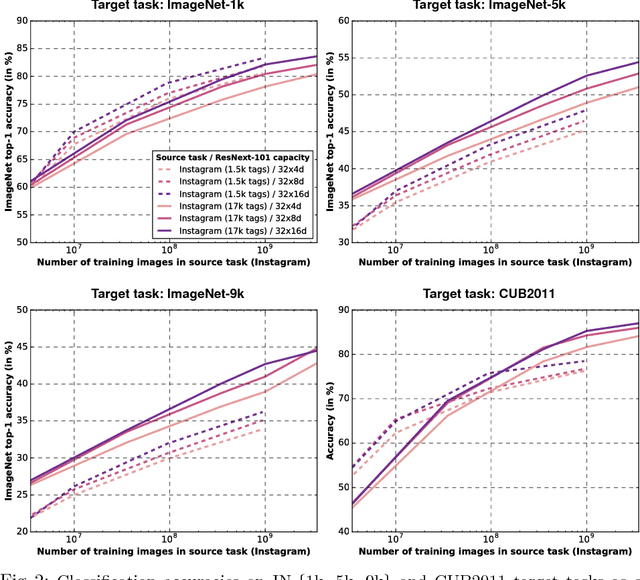
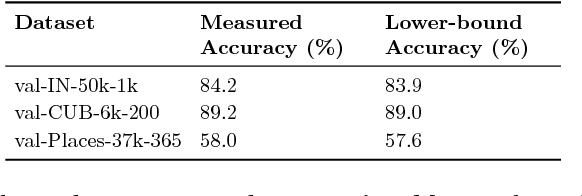
State-of-the-art visual perception models for a wide range of tasks rely on supervised pretraining. ImageNet classification is the de facto pretraining task for these models. Yet, ImageNet is now nearly ten years old and is by modern standards "small". Even so, relatively little is known about the behavior of pretraining with datasets that are multiple orders of magnitude larger. The reasons are obvious: such datasets are difficult to collect and annotate. In this paper, we present a unique study of transfer learning with large convolutional networks trained to predict hashtags on billions of social media images. Our experiments demonstrate that training for large-scale hashtag prediction leads to excellent results. We show improvements on several image classification and object detection tasks, and report the highest ImageNet-1k single-crop, top-1 accuracy to date: 85.4% (97.6% top-5). We also perform extensive experiments that provide novel empirical data on the relationship between large-scale pretraining and transfer learning performance.
A Closer Look at Spatiotemporal Convolutions for Action Recognition
Apr 12, 2018
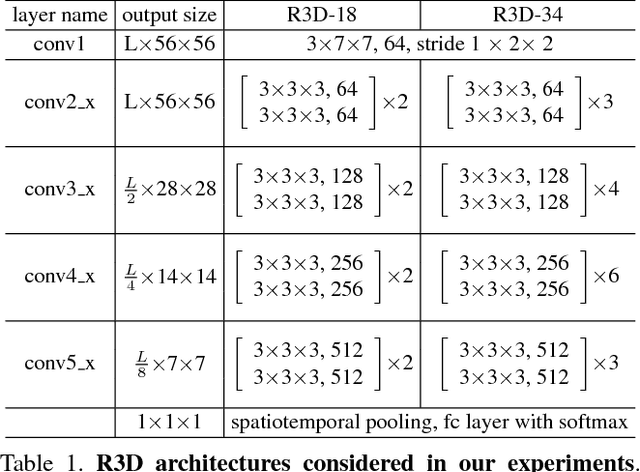
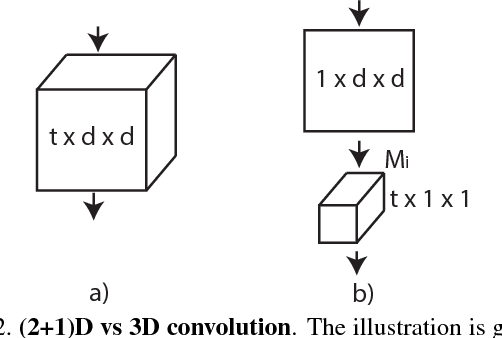

In this paper we discuss several forms of spatiotemporal convolutions for video analysis and study their effects on action recognition. Our motivation stems from the observation that 2D CNNs applied to individual frames of the video have remained solid performers in action recognition. In this work we empirically demonstrate the accuracy advantages of 3D CNNs over 2D CNNs within the framework of residual learning. Furthermore, we show that factorizing the 3D convolutional filters into separate spatial and temporal components yields significantly advantages in accuracy. Our empirical study leads to the design of a new spatiotemporal convolutional block "R(2+1)D" which gives rise to CNNs that achieve results comparable or superior to the state-of-the-art on Sports-1M, Kinetics, UCF101 and HMDB51.
ConvNet Architecture Search for Spatiotemporal Feature Learning
Aug 16, 2017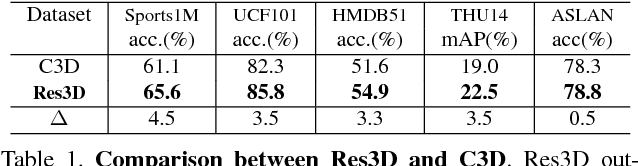



Learning image representations with ConvNets by pre-training on ImageNet has proven useful across many visual understanding tasks including object detection, semantic segmentation, and image captioning. Although any image representation can be applied to video frames, a dedicated spatiotemporal representation is still vital in order to incorporate motion patterns that cannot be captured by appearance based models alone. This paper presents an empirical ConvNet architecture search for spatiotemporal feature learning, culminating in a deep 3-dimensional (3D) Residual ConvNet. Our proposed architecture outperforms C3D by a good margin on Sports-1M, UCF101, HMDB51, THUMOS14, and ASLAN while being 2 times faster at inference time, 2 times smaller in model size, and having a more compact representation.