 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvNet Architecture Search for Spatiotemporal Feature Learning
Paper and Code
Aug 16, 2017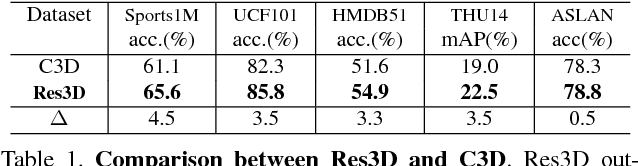



Learning image representations with ConvNets by pre-training on ImageNet has proven useful across many visual understanding tasks including object detection, semantic segmentation, and image captioning. Although any image representation can be applied to video frames, a dedicated spatiotemporal representation is still vital in order to incorporate motion patterns that cannot be captured by appearance based models alone. This paper presents an empirical ConvNet architecture search for spatiotemporal feature learning, culminating in a deep 3-dimensional (3D) Residual ConvNet. Our proposed architecture outperforms C3D by a good margin on Sports-1M, UCF101, HMDB51, THUMOS14, and ASLAN while being 2 times faster at inference time, 2 times smaller in model size, and having a more compact representation.