 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAL: Semantic Attention Learning for Long Video Representation
Dec 02, 2024Long video understanding presents challenges due to the inherent high computational complexity and redundant temporal information. An effective representation for long videos must process such redundancy efficiently while preserving essential contents for downstream tasks. This paper introduces SEmantic Attention Learning (SEAL), a novel unified representation for long videos. To reduce computational complexity, long videos are decomposed into three distinct types of semantic entities: scenes, objects, and actions, allowing models to operate on a handful of entities rather than a large number of frames or pixels. To further address redundancy, we propose an attention learning module that balances token relevance with diversity formulated as a subset selection optimization problem. Our representation is versatile, enabling applications across various long video understanding tasks. Extensive experiments show that SEAL significantly outperforms state-of-the-art methods in video question answering and temporal grounding tasks and benchmarks including LVBench, MovieChat-1K, and Ego4D.
Learning Space-Time Semantic Correspondences
Jun 16, 2023



We propose a new task of space-time semantic correspondence prediction in videos. Given a source video, a target video, and a set of space-time key-points in the source video, the task requires predicting a set of keypoints in the target video that are the semantic correspondences of the provided source keypoints. We believe that this task is important for fine-grain video understanding, potentially enabling applications such as activity coaching, sports analysis, robot imitation learning, and more. Our contributions in this paper are: (i) proposing a new task and providing annotations for space-time semantic correspondences on two existing benchmarks: Penn Action and Pouring; and (ii) presenting a comprehensive set of baselines and experiments to gain insights about the new problem. Our main finding is that the space-time semantic correspondence prediction problem is best approached jointly in space and time rather than in their decomposed sub-problems: time alignment and spatial correspondences.
Open-world Instance Segmentation: Top-down Learning with Bottom-up Supervision
Mar 09, 2023



Many top-down architectures for instance segmentation achieve significant success when trained and tested on pre-defined closed-world taxonomy. However, when deployed in the open world, they exhibit notable bias towards seen classes and suffer from significant performance drop. In this work, we propose a novel approach for open world instance segmentation called bottom-Up and top-Down Open-world Segmentation (UDOS) that combines classical bottom-up segmentation algorithms within a top-down learning framework. UDOS first predicts parts of objects using a top-down network trained with weak supervision from bottom-up segmentations. The bottom-up segmentations are class-agnostic and do not overfit to specific taxonomies. The part-masks are then fed into affinity-based grouping and refinement modules to predict robust instance-level segmentations. UDOS enjoys both the speed and efficiency from the top-down architectures and the generalization ability to unseen categories from bottom-up supervision. We validate the strengths of UDOS on multiple cross-category as well as cross-dataset transfer tasks from 5 challenging datasets including MS-COCO, LVIS, ADE20k, UVO and OpenImages, achieving significant improvements over state-of-the-art across the board. Our code and models are available on our project page.
MINOTAUR: Multi-task Video Grounding From Multimodal Queries
Feb 16, 2023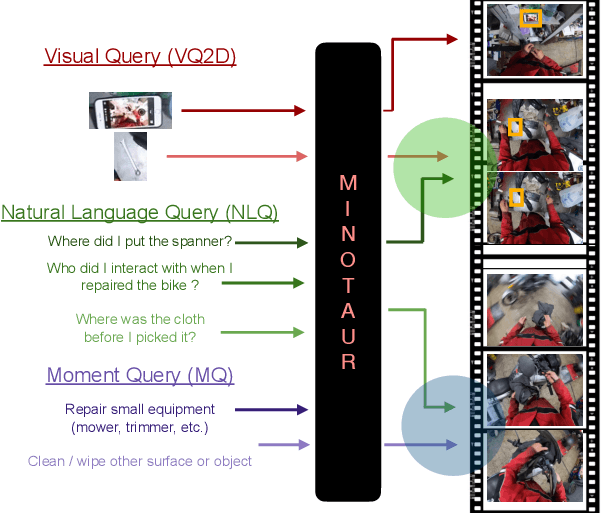

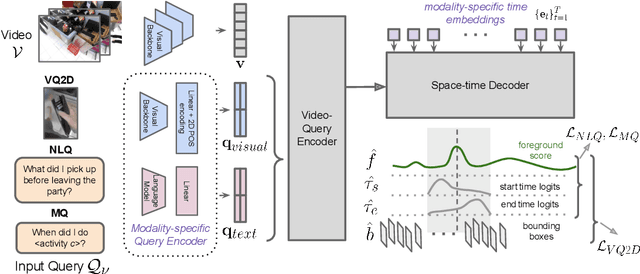
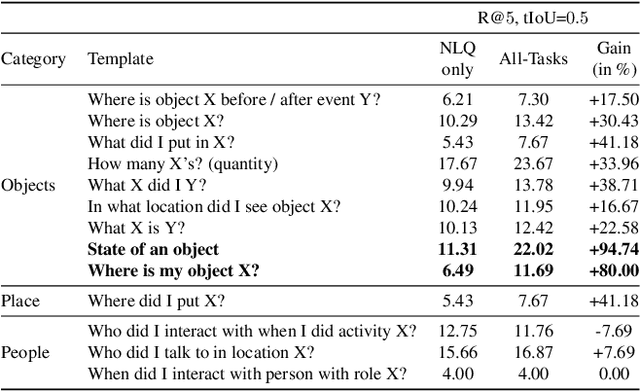
Video understanding tasks take many forms, from action detection to visual query localization and spatio-temporal grounding of sentences. These tasks differ in the type of inputs (only video, or video-query pair where query is an image region or sentence) and outputs (temporal segments or spatio-temporal tubes). However, at their core they require the same fundamental understanding of the video, i.e., the actors and objects in it, their actions and interactions. So far these tasks have been tackled in isolation with individual, highly specialized architectures, which do not exploit the interplay between tasks. In contrast, in this paper, we present a single, unified model for tackling query-based video understanding in long-form videos. In particular, our model can address all three tasks of the Ego4D Episodic Memory benchmark which entail queries of three different forms: given an egocentric video and a visual, textual or activity query, the goal is to determine when and where the answer can be seen within the video. Our model design is inspired by recent query-based approaches to spatio-temporal grounding, and contains modality-specific query encoders and task-specific sliding window inference that allow multi-task training with diverse input modalities and different structured outputs. We exhaustively analyze relationships among the tasks and illustrate that cross-task learning leads to improved performance on each individual task, as well as the ability to generalize to unseen tasks, such as zero-shot spatial localization of language queries.
Open-World Instance Segmentation: Exploiting Pseudo Ground Truth From Learned Pairwise Affinity
Apr 12, 2022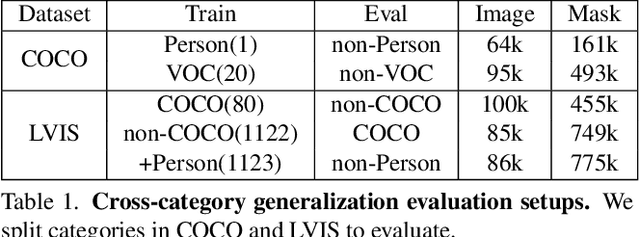



Open-world instance segmentation is the task of grouping pixels into object instances without any pre-determined taxonomy. This is challenging, as state-of-the-art methods rely on explicit class semantics obtained from large labeled datasets, and out-of-domain evaluation performance drops significantly. Here we propose a novel approach for mask proposals, Generic Grouping Networks (GGNs), constructed without semantic supervision. Our approach combines a local measure of pixel affinity with instance-level mask supervision, producing a training regimen designed to make the model as generic as the data diversity allows. We introduce a method for predicting Pairwise Affinities (PA), a learned local relationship between pairs of pixels. PA generalizes very well to unseen categories. From PA we construct a large set of pseudo-ground-truth instance masks; combined with human-annotated instance masks we train GGNs and significantly outperform the SOTA on open-world instance segmentation on various benchmarks including COCO, LVIS, ADE20K, and UVO. Code is available on project website: https://sites.google.com/view/generic-grouping/.
Long-Short Temporal Contrastive Learning of Video Transformers
Jul 08, 2021



Video transformers have recently emerged as a competitive alternative to 3D CNNs for video understanding. However, due to their large number of parameters and reduced inductive biases, these models require supervised pretraining on large-scale image datasets to achieve top performance. In this paper, we empirically demonstrate that self-supervised pretraining of video transformers on video-only datasets can lead to action recognition results that are on par or better than those obtained with supervised pretraining on large-scale image datasets, even massive ones such as ImageNet-21K. Since transformer-based models are effective at capturing dependencies over extended temporal spans, we propose a simple learning procedure that forces the model to match a long-term view to a short-term view of the same video. Our approach, named Long-Short Temporal Contrastive Learning (LSTCL), enables video transformers to learn an effective clip-level representation by predicting temporal context captured from a longer temporal extent. To demonstrate the generality of our findings, we implement and validate our approach under three different self-supervised contrastive learning frameworks (MoCo v3, BYOL, SimSiam) using two distinct video-transformer architectures, including an improved variant of the Swin Transformer augmented with space-time attention. We conduct a thorough ablation study and show that LSTCL achieves competitive performance on multiple video benchmarks and represents a convincing alternative to supervised image-based pretraining.
Unidentified Video Objects: A Benchmark for Dense, Open-World Segmentation
Apr 10, 2021
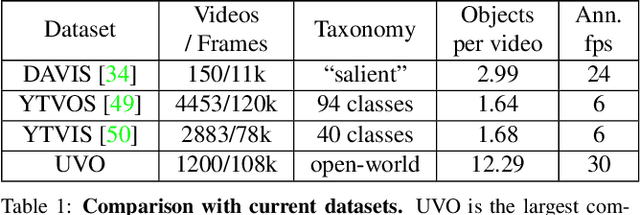


Current state-of-the-art object detection and segmentation methods work well under the closed-world assumption. This closed-world setting assumes that the list of object categories is available during training and deployment. However, many real-world applications require detecting or segmenting novel objects, i.e., object categories never seen during training. In this paper, we present, UVO (Unidentified Video Objects), a new benchmark for open-world class-agnostic object segmentation in videos. Besides shifting the problem focus to the open-world setup, UVO is significantly larger, providing approximately 8 times more videos compared with DAVIS, and 7 times more mask (instance) annotations per video compared with YouTube-VOS and YouTube-VIS. UVO is also more challenging as it includes many videos with crowded scenes and complex background motions. We demonstrated that UVO can be used for other applications, such as object tracking and super-voxel segmentation, besides open-world object segmentation. We believe that UVo is a versatile testbed for researchers to develop novel approaches for open-world class-agnostic object segmentation, and inspires new research directions towards a more comprehensive video understanding beyond classification and detection.
FLAVR: Flow-Agnostic Video Representations for Fast Frame Interpolation
Dec 15, 2020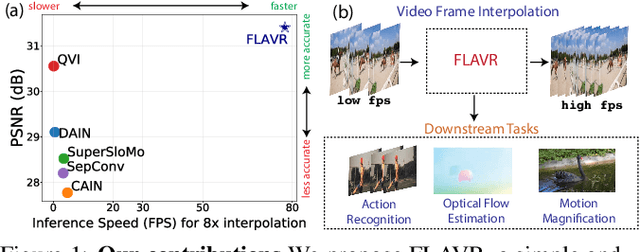
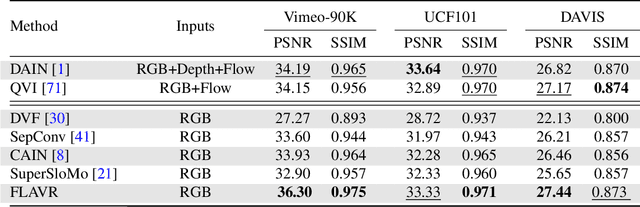
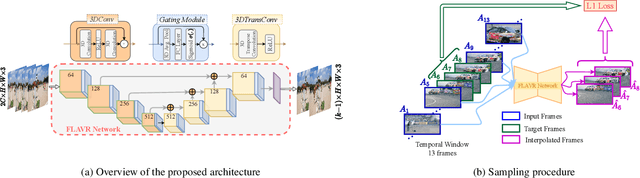

A majority of approaches solve the problem of video frame interpolation by computing bidirectional optical flow between adjacent frames of a video followed by a suitable warping algorithm to generate the output frames. However, methods relying on optical flow often fail to model occlusions and complex non-linear motions directly from the video and introduce additional bottlenecks unsuitable for real time deployment. To overcome these limitations, we propose a flexible and efficient architecture that makes use of 3D space-time convolutions to enable end to end learning and inference for the task of video frame interpolation. Our method efficiently learns to reason about non-linear motions, complex occlusions and temporal abstractions resulting in improved performance on video interpolation, while requiring no additional inputs in the form of optical flow or depth maps. Due to its simplicity, our proposed method improves the inference speed by 384x compared to the current most accurate method and 23x compared to the current fastest on 8x interpolation. In addition, we evaluate our model on a wide range of challenging settings and consistently demonstrate superior qualitative and quantitative results compared with current methods on various popular benchmarks including Vimeo-90K, UCF101, DAVIS, Adobe, and GoPro. Finally, we demonstrate that video frame interpolation can serve as a useful self-supervised pretext task for action recognition, optical flow estimation, and motion magnification.
Self-Supervised Learning by Cross-Modal Audio-Video Clustering
Nov 28, 2019
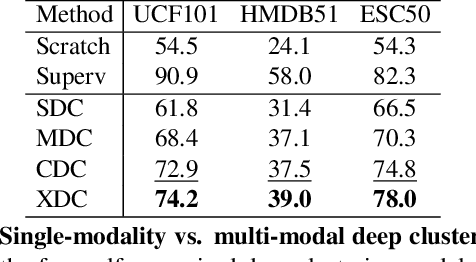

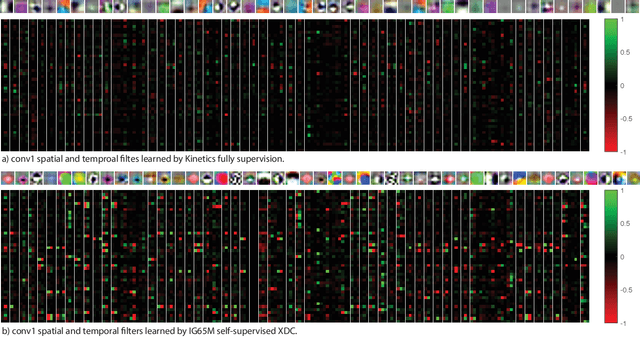
The visual and audio modalities are highly correlated yet they contain different information. Their strong correlation makes it possible to predict the semantics of one from the other with good accuracy. Their intrinsic differences make cross-modal prediction a potentially more rewarding pretext task for self-supervised learning of video and audio representations compared to within-modality learning. Based on this intuition, we propose Cross-Modal Deep Clustering (XDC), a novel self-supervised method that leverages unsupervised clustering in one modality (e.g. audio) as a supervisory signal for the other modality (e.g. video). This cross-modal supervision helps XDC utilize the semantic correlation and the differences between the two modalities. Our experiments show that XDC significantly outperforms single-modality clustering and other multi-modal variants. Our XDC achieves state-of-the-art accuracy among self-supervised methods on several video and audio benchmarks including HMDB51, UCF101, ESC50, and DCASE. Most importantly, the video model pretrained with XDC significantly outperforms the same model pretrained with full-supervision on both ImageNet and Kinetics in action recognition on HMDB51 and UCF101. To the best of our knowledge, XDC is the first method to demonstrate that self-supervision outperforms large-scale full-supervision in representation learning for action recognition.
UniDual: A Unified Model for Image and Video Understanding
Jun 12, 2019
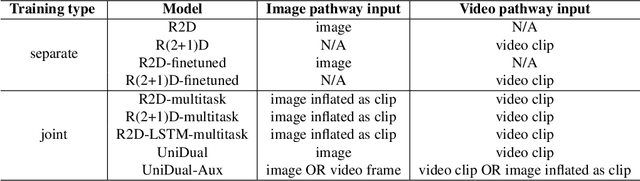
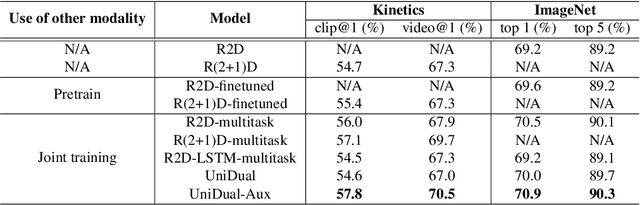

Although a video is effectively a sequence of images, visual perception systems typically model images and videos separately, thus failing to exploit the correlation and the synergy provided by these two media. While a few prior research efforts have explored the benefits of leveraging still-image datasets for video analysis, or vice-versa, most of these attempts have been limited to pretraining a model on one type of visual modality and then adapting it via finetuning on the other modality. In contrast, in this paper we introduce a framework that enables joint training of a unified model on mixed collections of image and video examples spanning different tasks. The key ingredient in our architecture design is a new network block, which we name UniDual. It consists of a shared 2D spatial convolution followed by two parallel point-wise convolutional layers, one devoted to images and the other one used for videos. For video input, the point-wise filtering implements a temporal convolution. For image input, it performs a pixel-wise nonlinear transformation. Repeated stacking of such blocks gives rise to a network where images and videos undergo partially distinct execution pathways, unified by spatial convolutions (capturing commonalities in visual appearance) but separated by point-wise operations (modeling patterns specific to each modality). Extensive experiments on Kinetics and ImageNet demonstrate that our UniDual model jointly trained on these datasets yields substantial accuracy gains for both tasks, compared to 1) training separate models, 2) traditional multi-task learning and 3) the conventional framework of pretraining-followed-by-finetuning. On Kinetics, the UniDual architecture applied to a state-of-the-art video backbone model (R(2+1)D-152) yields an additional video@1 accuracy gain of 1.5%.