 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverseFlow: Sample-Efficient Diverse Mode Coverage in Flows
Apr 10, 2025Many real-world applications of flow-based generative models desire a diverse set of samples that cover multiple modes of the target distribution. However, the predominant approach for obtaining diverse sets is not sample-efficient, as it involves independently obtaining many samples from the source distribution and mapping them through the flow until the desired mode coverage is achieved. As an alternative to repeated sampling, we introduce DiverseFlow: a training-free approach to improve the diversity of flow models. Our key idea is to employ a determinantal point process to induce a coupling between the samples that drives diversity under a fixed sampling budget. In essence, DiverseFlow allows exploration of more variations in a learned flow model with fewer samples. We demonstrate the efficacy of our method for tasks where sample-efficient diversity is desirable, such as text-guided image generation with polysemous words, inverse problems like large-hole inpainting, and class-conditional image synthesis.
Compositional World Knowledge leads to High Utility Synthetic data
Mar 06, 2025Machine learning systems struggle with robustness, under subpopulation shifts. This problem becomes especially pronounced in scenarios where only a subset of attribute combinations is observed during training -a severe form of subpopulation shift, referred as compositional shift. To address this problem, we ask the following question: Can we improve the robustness by training on synthetic data, spanning all possible attribute combinations? We first show that training of conditional diffusion models on limited data lead to incorrect underlying distribution. Therefore, synthetic data sampled from such models will result in unfaithful samples and does not lead to improve performance of downstream machine learning systems. To address this problem, we propose CoInD to reflect the compositional nature of the world by enforcing conditional independence through minimizing Fisher's divergence between joint and marginal distributions. We demonstrate that synthetic data generated by CoInD is faithful and this translates to state-of-the-art worst-group accuracy on compositional shift tasks on CelebA.
CoInD: Enabling Logical Compositions in Diffusion Models
Mar 03, 2025How can we learn generative models to sample data with arbitrary logical compositions of statistically independent attributes? The prevailing solution is to sample from distributions expressed as a composition of attributes' conditional marginal distributions under the assumption that they are statistically independent. This paper shows that standard conditional diffusion models violate this assumption, even when all attribute compositions are observed during training. And, this violation is significantly more severe when only a subset of the compositions is observed. We propose CoInD to address this problem. It explicitly enforces statistical independence between the conditional marginal distributions by minimizing Fisher's divergence between the joint and marginal distributions. The theoretical advantages of CoInD are reflected in both qualitative and quantitative experiments, demonstrating a significantly more faithful and controlled generation of samples for arbitrary logical compositions of attributes. The benefit is more pronounced for scenarios that current solutions relying on the assumption of conditionally independent marginals struggle with, namely, logical compositions involving the NOT operation and when only a subset of compositions are observed during training.
SEAL: Semantic Attention Learning for Long Video Representation
Dec 02, 2024Long video understanding presents challenges due to the inherent high computational complexity and redundant temporal information. An effective representation for long videos must process such redundancy efficiently while preserving essential contents for downstream tasks. This paper introduces SEmantic Attention Learning (SEAL), a novel unified representation for long videos. To reduce computational complexity, long videos are decomposed into three distinct types of semantic entities: scenes, objects, and actions, allowing models to operate on a handful of entities rather than a large number of frames or pixels. To further address redundancy, we propose an attention learning module that balances token relevance with diversity formulated as a subset selection optimization problem. Our representation is versatile, enabling applications across various long video understanding tasks. Extensive experiments show that SEAL significantly outperforms state-of-the-art methods in video question answering and temporal grounding tasks and benchmarks including LVBench, MovieChat-1K, and Ego4D.
Enhancing Privacy in Face Analytics Using Fully Homomorphic Encryption
Apr 24, 2024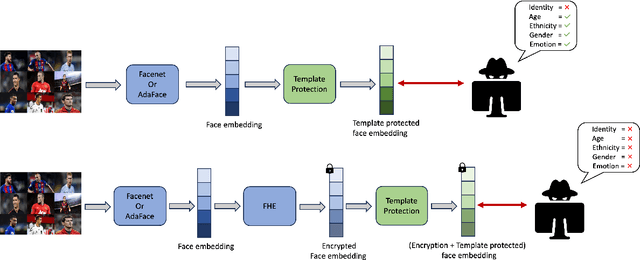
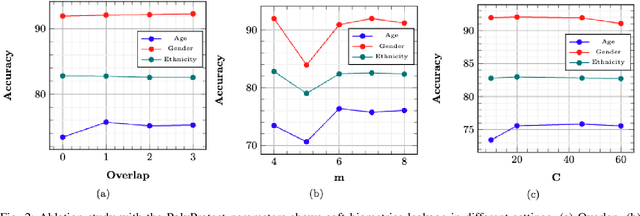
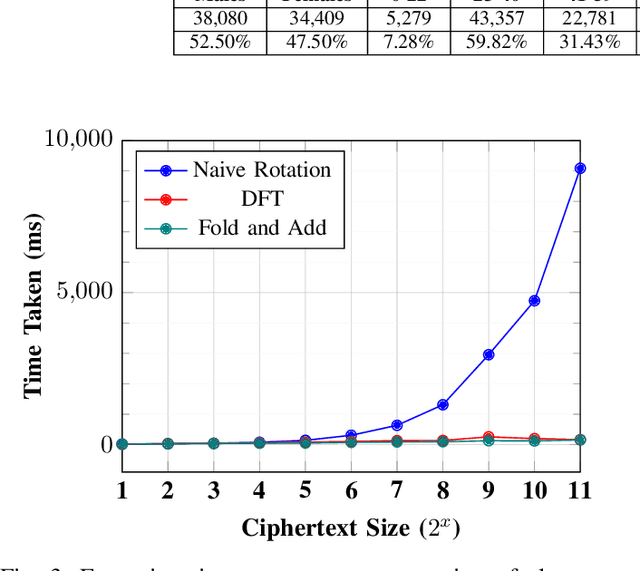
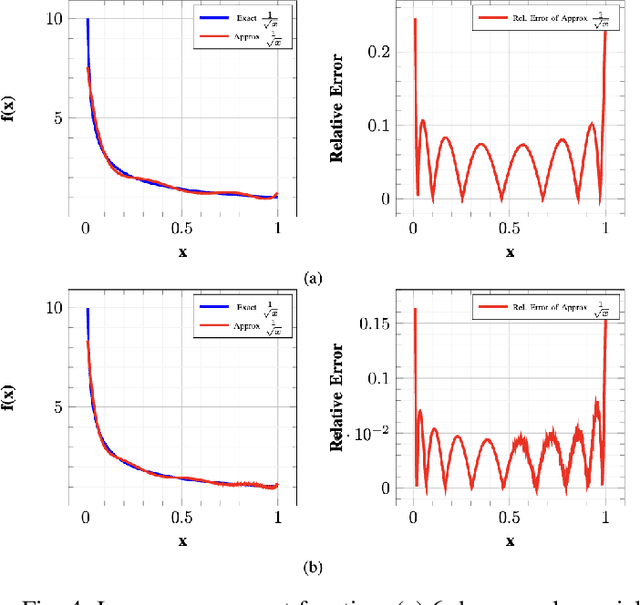
Modern face recognition systems utilize deep neural networks to extract salient features from a face. These features denote embeddings in latent space and are often stored as templates in a face recognition system. These embeddings are susceptible to data leakage and, in some cases, can even be used to reconstruct the original face image. To prevent compromising identities, template protection schemes are commonly employed. However, these schemes may still not prevent the leakage of soft biometric information such as age, gender and race. To alleviate this issue, we propose a novel technique that combines Fully Homomorphic Encryption (FHE) with an existing template protection scheme known as PolyProtect. We show that the embeddings can be compressed and encrypted using FHE and transformed into a secure PolyProtect template using polynomial transformation, for additional protection. We demonstrate the efficacy of the proposed approach through extensive experiments on multiple datasets. Our proposed approach ensures irreversibility and unlinkability, effectively preventing the leakage of soft biometric attributes from face embeddings without compromising recognition accuracy.
Action Reimagined: Text-to-Pose Video Editing for Dynamic Human Actions
Mar 11, 2024We introduce a novel text-to-pose video editing method, ReimaginedAct. While existing video editing tasks are limited to changes in attributes, backgrounds, and styles, our method aims to predict open-ended human action changes in video. Moreover, our method can accept not only direct instructional text prompts but also `what if' questions to predict possible action changes. ReimaginedAct comprises video understanding, reasoning, and editing modules. First, an LLM is utilized initially to obtain a plausible answer for the instruction or question, which is then used for (1) prompting Grounded-SAM to produce bounding boxes of relevant individuals and (2) retrieving a set of pose videos that we have collected for editing human actions. The retrieved pose videos and the detected individuals are then utilized to alter the poses extracted from the original video. We also employ a timestep blending module to ensure the edited video retains its original content except where necessary modifications are needed. To facilitate research in text-to-pose video editing, we introduce a new evaluation dataset, WhatifVideo-1.0. This dataset includes videos of different scenarios spanning a range of difficulty levels, along with questions and text prompts. Experimental results demonstrate that existing video editing methods struggle with human action editing, while our approach can achieve effective action editing and even imaginary editing from counterfactual questions.
3DFaceFill: An Analysis-By-Synthesis Approach to Face Completion
Oct 20, 2021
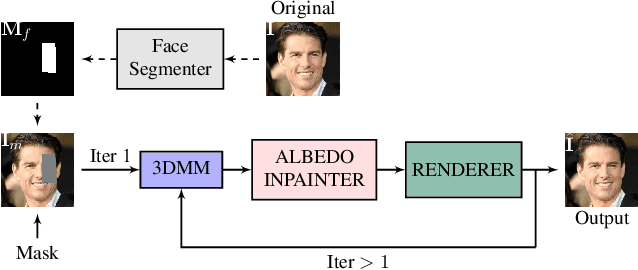


Existing face completion solutions are primarily driven by end-to-end models that directly generate 2D completions of 2D masked faces. By having to implicitly account for geometric and photometric variations in facial shape and appearance, such approaches result in unrealistic completions, especially under large variations in pose, shape, illumination and mask sizes. To alleviate these limitations, we introduce 3DFaceFill, an analysis-by-synthesis approach for face completion that explicitly considers the image formation process. It comprises three components, (1) an encoder that disentangles the face into its constituent 3D mesh, 3D pose, illumination and albedo factors, (2) an autoencoder that inpaints the UV representation of facial albedo, and (3) a renderer that resynthesizes the completed face. By operating on the UV representation, 3DFaceFill affords the power of correspondence and allows us to naturally enforce geometrical priors (e.g. facial symmetry) more effectively. Quantitatively, 3DFaceFill improves the state-of-the-art by up to 4dB higher PSNR and 25% better LPIPS for large masks. And, qualitatively, it leads to demonstrably more photorealistic face completions over a range of masks and occlusions while preserving consistency in global and component-wise shape, pose, illumination and eye-gaze.
On the Fundamental Trade-offs in Learning Invariant Representations
Sep 08, 2021

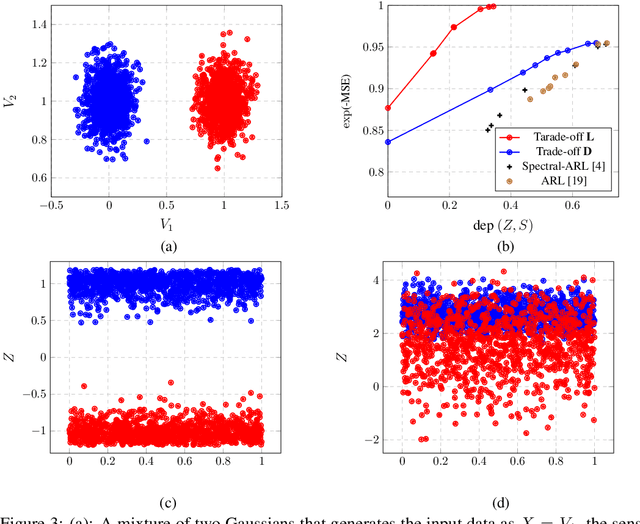
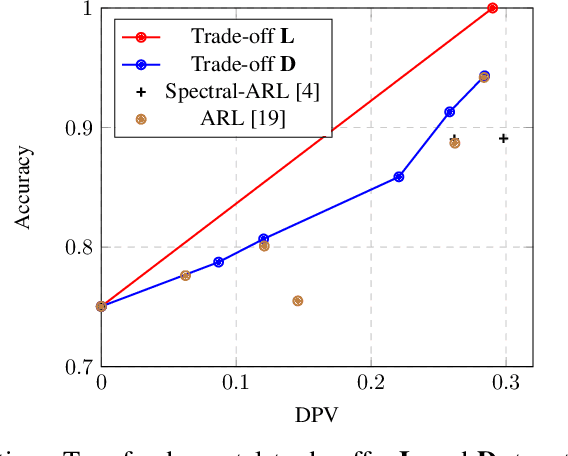
Many applications of representation learning, such as privacy-preservation, algorithmic fairness and domain adaptation, desire explicit control over semantic information being discarded. This goal is often formulated as satisfying two potentially competing objectives: maximizing utility for predicting a target attribute while simultaneously being independent or invariant with respect to a known semantic attribute. In this paper, we \emph{identify and determine} two fundamental trade-offs between utility and semantic dependence induced by the statistical dependencies between the data and its corresponding target and semantic attributes. We derive closed-form solutions for the global optima of the underlying optimization problems under mild assumptions, which in turn yields closed formulae for the exact trade-offs. We also derive empirical estimates of the trade-offs and show their convergence to the corresponding population counterparts. Finally, we numerically quantify the trade-offs on representative problems and compare to the solutions achieved by baseline representation learning algorithms.
NSGA-NET: A Multi-Objective Genetic Algorithm for Neural Architecture Search
Oct 08, 2018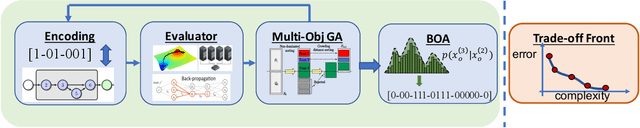
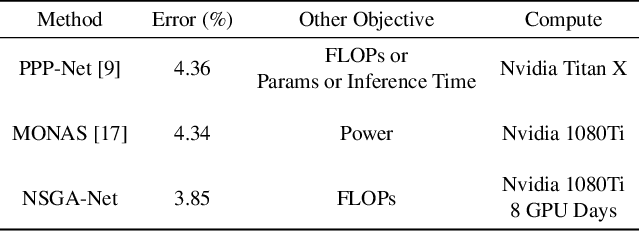

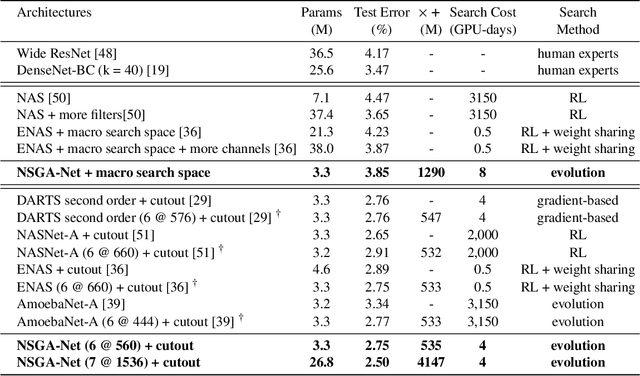
This paper introduces NSGA-Net, an evolutionary approach for neural architecture search (NAS). NSGA-Net is designed with three goals in mind: (1) a NAS procedure for multiple, possibly conflicting, objectives, (2) efficient exploration and exploitation of the space of potential neural network architectures, and (3) output of a diverse set of network architectures spanning a trade-off frontier of the objectives in a single run. NSGA-Net is a population-based search algorithm that explores a space of potential neural network architectures in three steps, namely, a population initialization step that is based on prior-knowledge from hand-crafted architectures, an exploration step comprising crossover and mutation of architectures and finally an exploitation step that applies the entire history of evaluated neural architectures in the form of a Bayesian Network prior. Experimental results suggest that combining the objectives of minimizing both an error metric and computational complexity, as measured by FLOPS, allows NSGA-Net to find competitive neural architectures near the Pareto front of both objectives on two different tasks, object classification and object alignment. NSGA-Net obtains networks that achieve 3.72% (at 4.5 million FLOP) error on CIFAR-10 classification and 8.64% (at 26.6 million FLOP) error on the CMU-Car alignment task. Code available at: https://github.com/ianwhale/nsga-net
Emergence of Selective Invariance in Hierarchical Feed Forward Networks
Jan 30, 2017



Many theories have emerged which investigate how in- variance is generated in hierarchical networks through sim- ple schemes such as max and mean pooling. The restriction to max/mean pooling in theoretical and empirical studies has diverted attention away from a more general way of generating invariance to nuisance transformations. We con- jecture that hierarchically building selective invariance (i.e. carefully choosing the range of the transformation to be in- variant to at each layer of a hierarchical network) is im- portant for pattern recognition. We utilize a novel pooling layer called adaptive pooling to find linear pooling weights within networks. These networks with the learnt pooling weights have performances on object categorization tasks that are comparable to max/mean pooling networks. In- terestingly, adaptive pooling can converge to mean pooling (when initialized with random pooling weights), find more general linear pooling schemes or even decide not to pool at all. We illustrate the general notion of selective invari- ance through object categorization experiments on large- scale datasets such as SVHN and ILSVRC 2012.