 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable-AI Policies using Evolutionary Nonlinear Decision Trees for Discrete Action Systems
Sep 20, 2020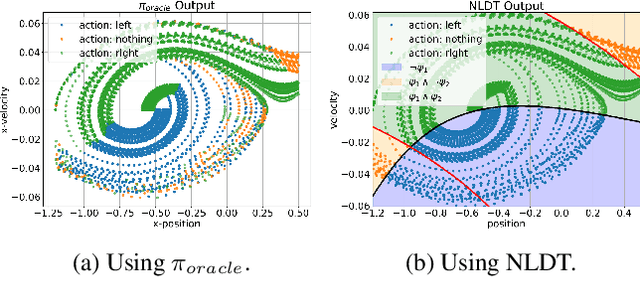


Black-box artificial intelligence (AI) induction methods such as deep reinforcement learning (DRL) are increasingly being used to find optimal policies for a given control task. Although policies represented using a black-box AI are capable of efficiently executing the underlying control task and achieving optimal closed-loop performance -- controlling the agent from initial time step until the successful termination of an episode, the developed control rules are often complex and neither interpretable nor explainable. In this paper, we use a recently proposed nonlinear decision-tree (NLDT) approach to find a hierarchical set of control rules in an attempt to maximize the open-loop performance for approximating and explaining the pre-trained black-box DRL (oracle) agent using the labelled state-action dataset. Recent advances in nonlinear optimization approaches using evolutionary computation facilitates finding a hierarchical set of nonlinear control rules as a function of state variables using a computationally fast bilevel optimization procedure at each node of the proposed NLDT. Additionally, we propose a re-optimization procedure for enhancing closed-loop performance of an already derived NLDT. We evaluate our proposed methodologies on four different control problems having two to four discrete actions. In all these problems our proposed approach is able to find simple and interpretable rules involving one to four non-linear terms per rule, while simultaneously achieving on par closed-loop performance when compared to a trained black-box DRL agent. The obtained results are inspiring as they suggest the replacement of complicated black-box DRL policies involving thousands of parameters (making them non-interpretable) with simple interpretable policies. Results are encouraging and motivating to pursue further applications of proposed approach in solving more complex control tasks.
Evaluating Nonlinear Decision Trees for Binary Classification Tasks with Other Existing Methods
Aug 25, 2020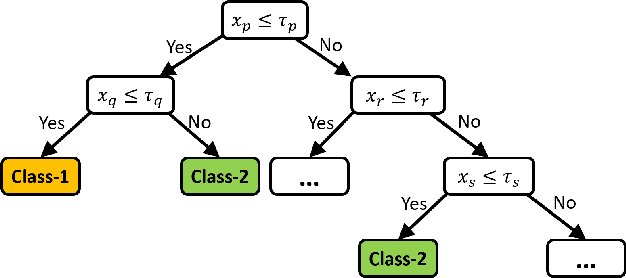
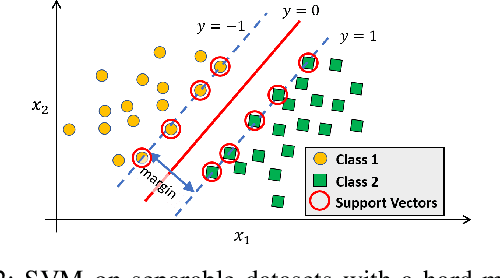
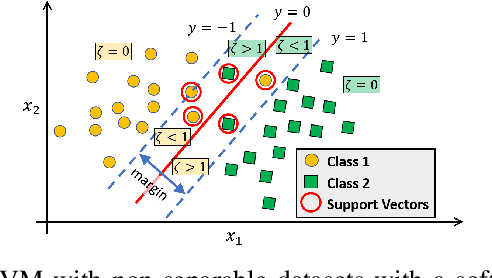
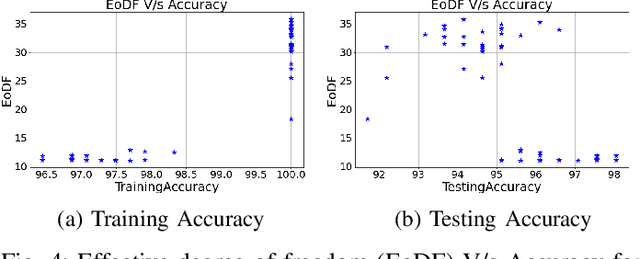
Classification of datasets into two or more distinct classes is an important machine learning task. Many methods are able to classify binary classification tasks with a very high accuracy on test data, but cannot provide any easily interpretable explanation for users to have a deeper understanding of reasons for the split of data into two classes. In this paper, we highlight and evaluate a recently proposed nonlinear decision tree approach with a number of commonly used classification methods on a number of datasets involving a few to a large number of features. The study reveals key issues such as effect of classification on the method's parameter values, complexity of the classifier versus achieved accuracy, and interpretability of resulting classifiers.
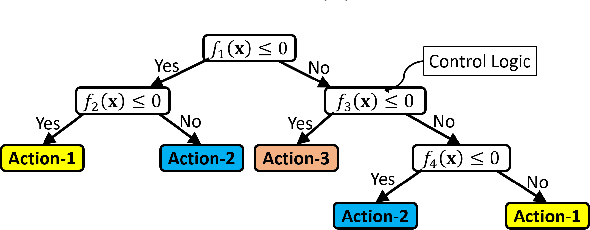
Interpretable Rule Discovery Through Bilevel Optimization of Split-Rules of Nonlinear Decision Trees for Classification Problems
Aug 02, 2020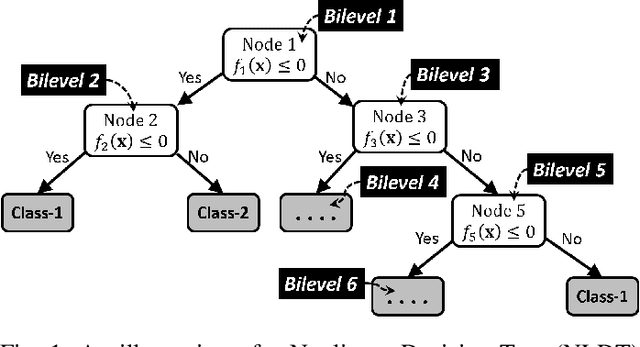
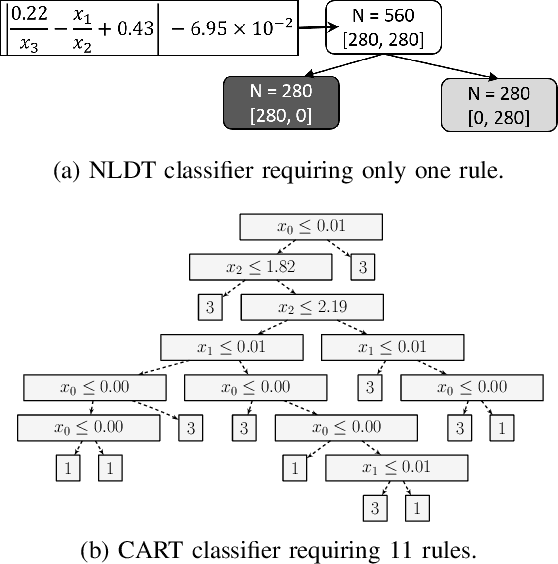
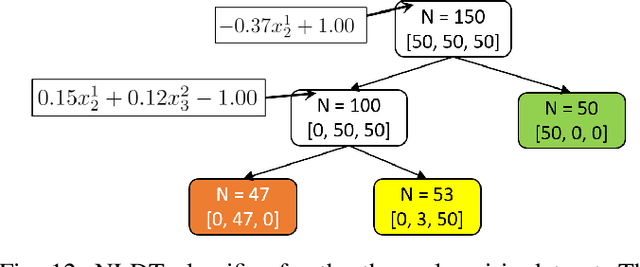

For supervised classification problems involving design, control, other practical purposes, users are not only interested in finding a highly accurate classifier, but they also demand that the obtained classifier be easily interpretable. While the definition of interpretability of a classifier can vary from case to case, here, by a humanly interpretable classifier we restrict it to be expressed in simplistic mathematical terms. As a novel approach, we represent a classifier as an assembly of simple mathematical rules using a non-linear decision tree (NLDT). Each conditional (non-terminal) node of the tree represents a non-linear mathematical rule (split-rule) involving features in order to partition the dataset in the given conditional node into two non-overlapping subsets. This partitioning is intended to minimize the impurity of the resulting child nodes. By restricting the structure of split-rule at each conditional node and depth of the decision tree, the interpretability of the classifier is assured. The non-linear split-rule at a given conditional node is obtained using an evolutionary bilevel optimization algorithm, in which while the upper-level focuses on arriving at an interpretable structure of the split-rule, the lower-level achieves the most appropriate weights (coefficients) of individual constituents of the rule to minimize the net impurity of two resulting child nodes. The performance of the proposed algorithm is demonstrated on a number of controlled test problems, existing benchmark problems, and industrial problems. Results on two to 500-feature problems are encouraging and open up further scopes of applying the proposed approach to more challenging and complex classification tasks.
Multi-Criterion Evolutionary Design of Deep Convolutional Neural Networks
Dec 03, 2019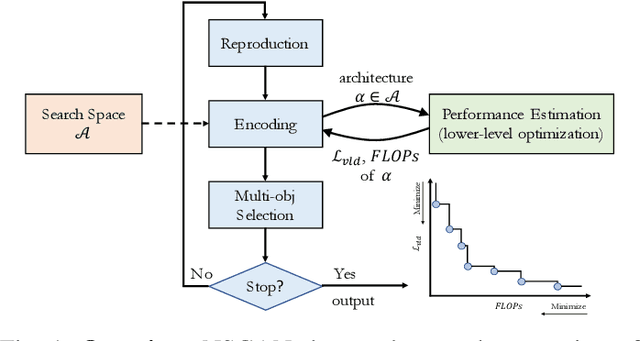
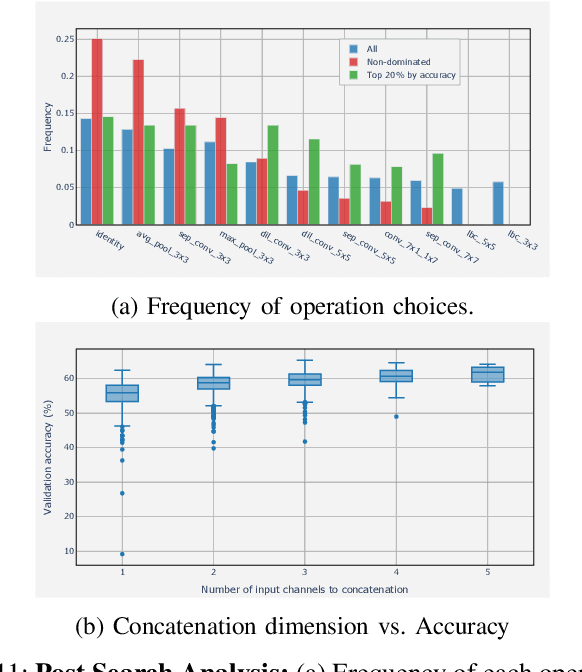
Convolutional neural networks (CNNs) are the backbones of deep learning paradigms for numerous vision tasks. Early advancements in CNN architectures are primarily driven by human expertise and elaborate design. Recently, neural architecture search was proposed with the aim of automating the network design process and generating task-dependent architectures. While existing approaches have achieved competitive performance in image classification, they are not well suited under limited computational budget for two reasons: (1) the obtained architectures are either solely optimized for classification performance or only for one targeted resource requirement; (2) the search process requires vast computational resources in most approaches. To overcome this limitation, we propose an evolutionary algorithm for searching neural architectures under multiple objectives, such as classification performance and FLOPs. The proposed method addresses the first shortcoming by populating a set of architectures to approximate the entire Pareto frontier through genetic operations that recombine and modify architectural components progressively. Our approach improves the computation efficiency by carefully down-scaling the architectures during the search as well as reinforcing the patterns commonly shared among the past successful architectures through Bayesian Learning. The integration of these two main contributions allows an efficient design of architectures that are competitive and in many cases outperform both manually and automatically designed architectures on benchmark image classification datasets, CIFAR, ImageNet and human chest X-ray. The flexibility provided from simultaneously obtaining multiple architecture choices for different compute requirements further differentiates our approach from other methods in the literature.
NSGA-NET: A Multi-Objective Genetic Algorithm for Neural Architecture Search
Oct 08, 2018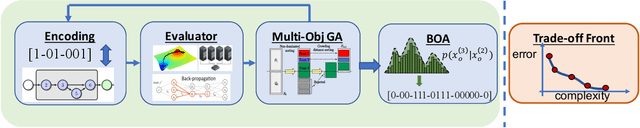
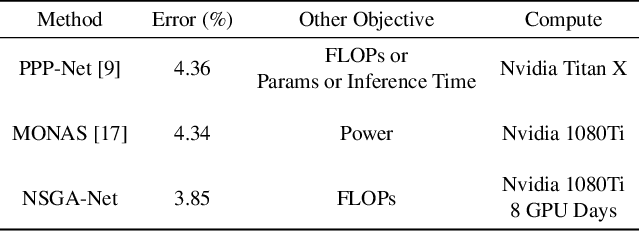

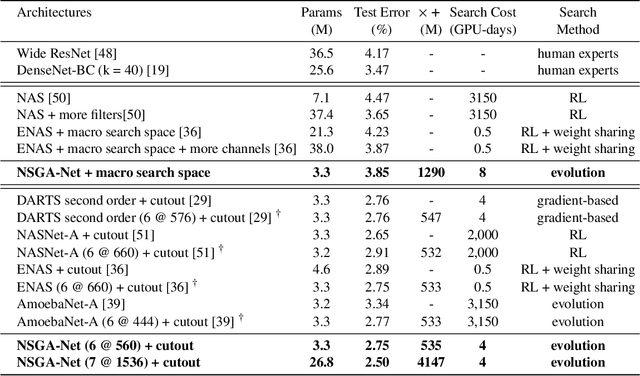
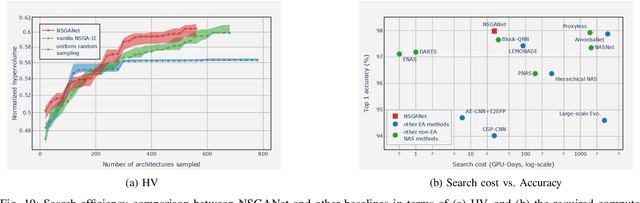
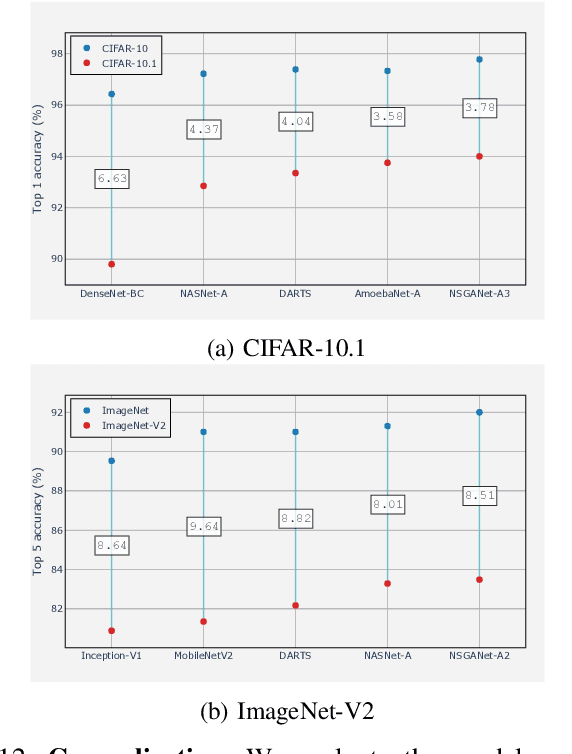
This paper introduces NSGA-Net, an evolutionary approach for neural architecture search (NAS). NSGA-Net is designed with three goals in mind: (1) a NAS procedure for multiple, possibly conflicting, objectives, (2) efficient exploration and exploitation of the space of potential neural network architectures, and (3) output of a diverse set of network architectures spanning a trade-off frontier of the objectives in a single run. NSGA-Net is a population-based search algorithm that explores a space of potential neural network architectures in three steps, namely, a population initialization step that is based on prior-knowledge from hand-crafted architectures, an exploration step comprising crossover and mutation of architectures and finally an exploitation step that applies the entire history of evaluated neural architectures in the form of a Bayesian Network prior. Experimental results suggest that combining the objectives of minimizing both an error metric and computational complexity, as measured by FLOPS, allows NSGA-Net to find competitive neural architectures near the Pareto front of both objectives on two different tasks, object classification and object alignment. NSGA-Net obtains networks that achieve 3.72% (at 4.5 million FLOP) error on CIFAR-10 classification and 8.64% (at 26.6 million FLOP) error on the CMU-Car alignment task. Code available at: https://github.com/ianwhale/nsga-net