 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interactive Knowledge-based Multi-objective Evolutionary Algorithm Framework for Practical Optimization Problems
Sep 18, 2022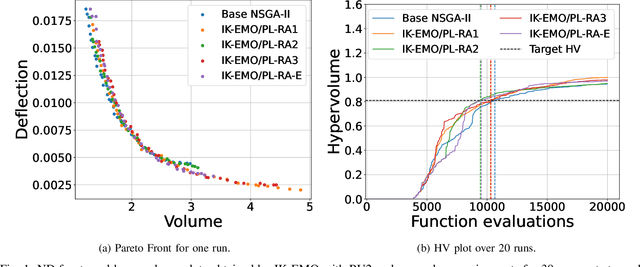
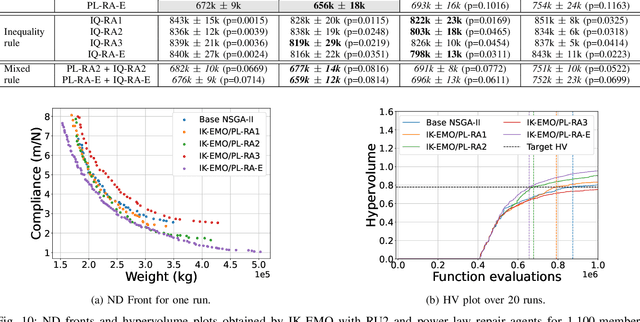
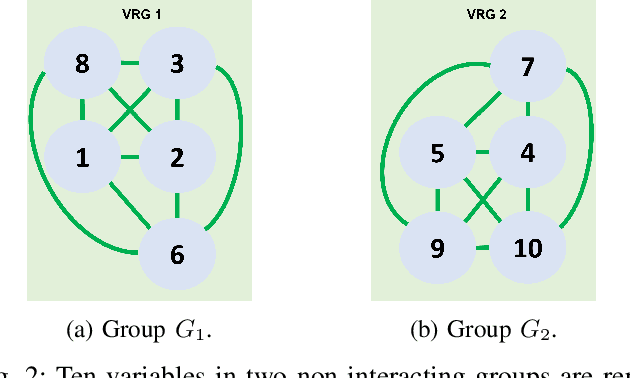
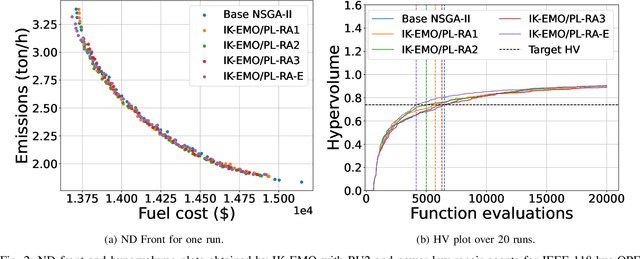
Experienced users often have useful knowledge and intuition in solving real-world optimization problems. User knowledge can be formulated as inter-variable relationships to assist an optimization algorithm in finding good solutions faster. Such inter-variable interactions can also be automatically learned from high-performing solutions discovered at intermediate iterations in an optimization run - a process called innovization. These relations, if vetted by the users, can be enforced among newly generated solutions to steer the optimization algorithm towards practically promising regions in the search space. Challenges arise for large-scale problems where the number of such variable relationships may be high. This paper proposes an interactive knowledge-based evolutionary multi-objective optimization (IK-EMO) framework that extracts hidden variable-wise relationships as knowledge from evolving high-performing solutions, shares them with users to receive feedback, and applies them back to the optimization process to improve its effectiveness. The knowledge extraction process uses a systematic and elegant graph analysis method which scales well with number of variables. The working of the proposed IK-EMO is demonstrated on three large-scale real-world engineering design problems. The simplicity and elegance of the proposed knowledge extraction process and achievement of high-performing solutions quickly indicate the power of the proposed framework. The results presented should motivate further such interaction-based optimization studies for their routine use in practice.
Enhanced Innovized Repair Operator for Evolutionary Multi- and Many-objective Optimization
Nov 21, 2020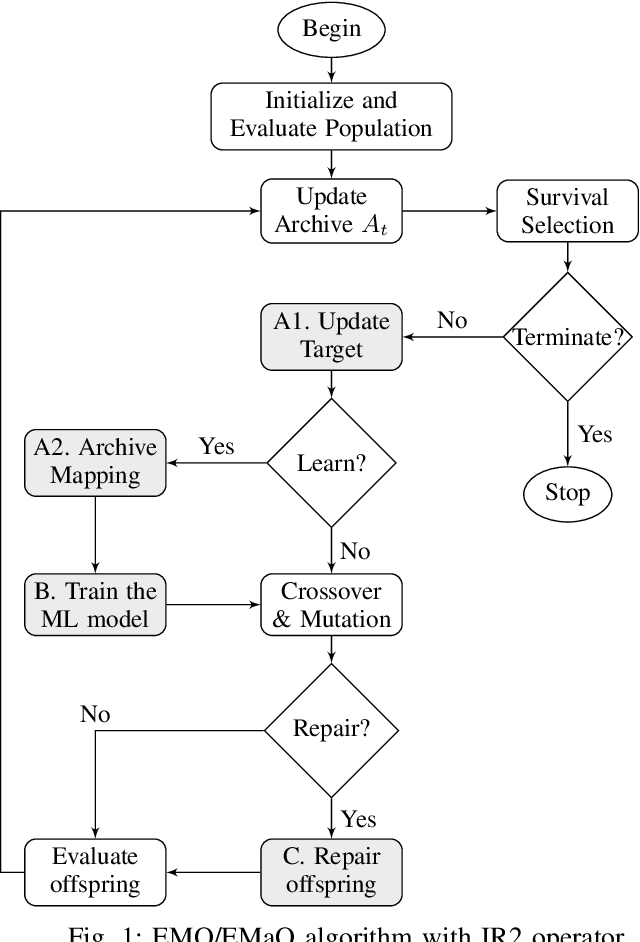
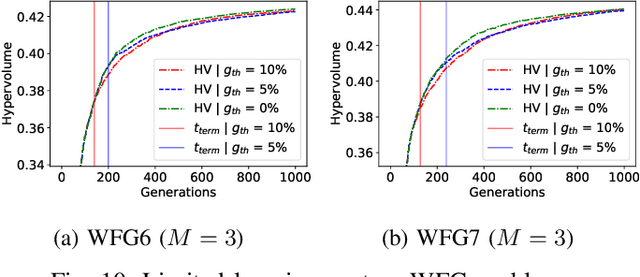
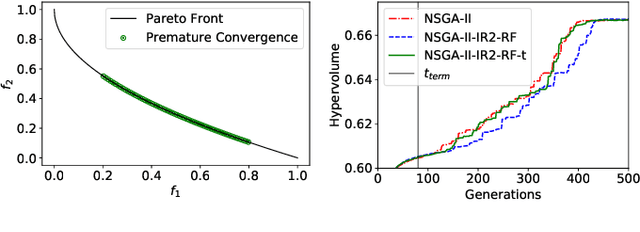
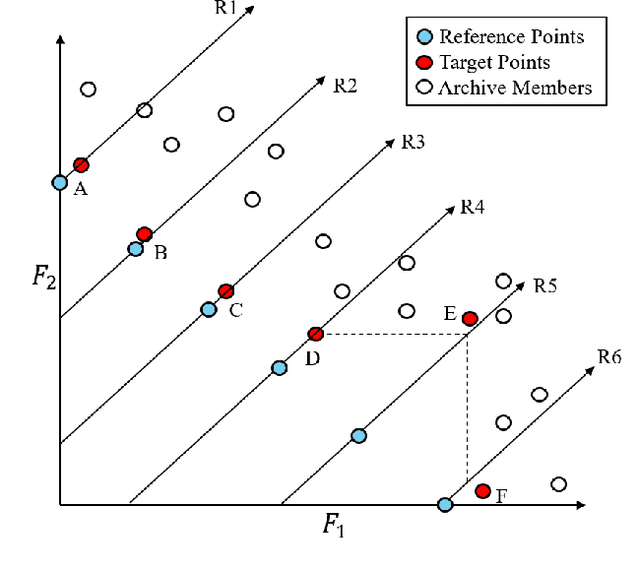
"Innovization" is a task of learning common relationships among some or all of the Pareto-optimal (PO) solutions in multi- and many-objective optimization problems. Recent studies have shown that a chronological sequence of non-dominated solutions obtained in consecutive iterations during an optimization run also possess salient patterns that can be used to learn problem features to help create new and improved solutions. In this paper, we propose a machine-learning- (ML-) assisted modelling approach that learns the modifications in design variables needed to advance population members towards the Pareto-optimal set. We then propose to use the resulting ML model as an additional innovized repair (IR2) operator to be applied on offspring solutions created by the usual genetic operators, as a novel mean of improving their convergence properties. In this paper, the well-known random forest (RF) method is used as the ML model and is integrated with various evolutionary multi- and many-objective optimization algorithms, including NSGA-II, NSGA-III, and MOEA/D. On several test problems ranging from two to five objectives, we demonstrate improvement in convergence behaviour using the proposed IR2-RF operator. Since the operator does not demand any additional solution evaluations, instead using the history of gradual and progressive improvements in solutions over generations, the proposed ML-based optimization opens up a new direction of optimization algorithm development with advances in AI and ML approaches.
NSGANetV2: Evolutionary Multi-Objective Surrogate-Assisted Neural Architecture Search
Jul 20, 2020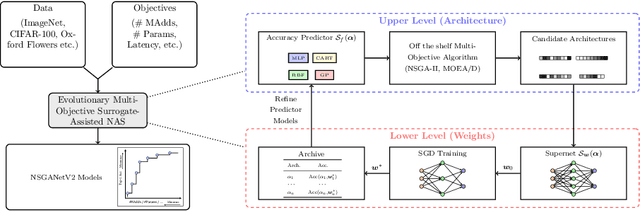

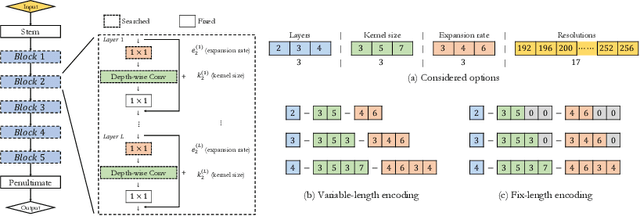
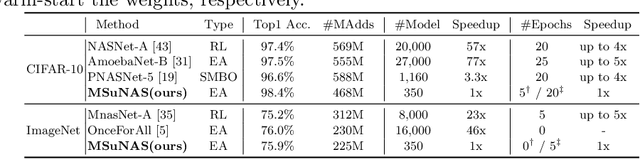
In this paper, we propose an efficient NAS algorithm for generating task-specific models that are competitive under multiple competing objectives. It comprises of two surrogates, one at the architecture level to improve sample efficiency and one at the weights level, through a supernet, to improve gradient descent training efficiency. On standard benchmark datasets (C10, C100, ImageNet), the resulting models, dubbed NSGANetV2, either match or outperform models from existing approaches with the search being orders of magnitude more sample efficient. Furthermore, we demonstrate the effectiveness and versatility of the proposed method on six diverse non-standard datasets, e.g. STL-10, Flowers102, Oxford Pets, FGVC Aircrafts etc. In all cases, NSGANetV2s improve the state-of-the-art (under mobile setting), suggesting that NAS can be a viable alternative to conventional transfer learning approaches in handling diverse scenarios such as small-scale or fine-grained datasets. Code is available at https://github.com/mikelzc1990/nsganetv2
Neural Architecture Transfer
May 12, 2020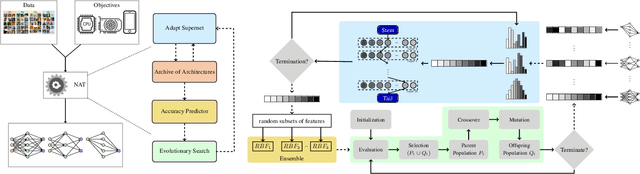
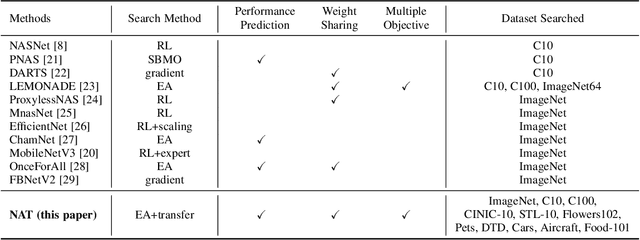
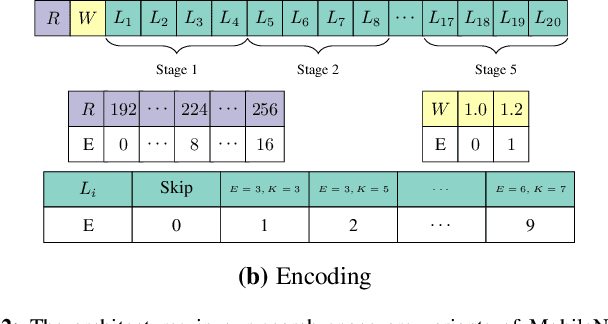
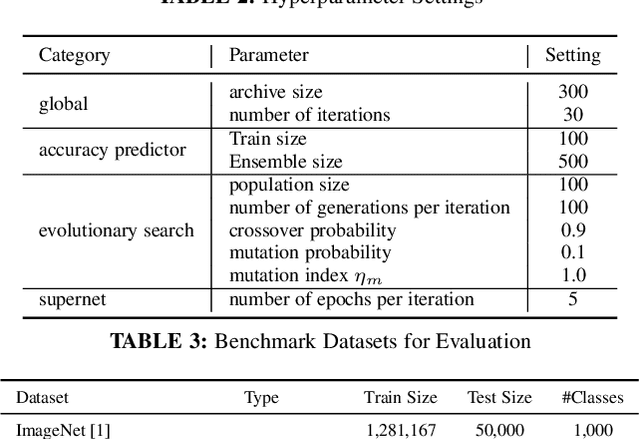
Neural architecture search (NAS) has emerged as a promising avenue for automatically designing task-specific neural networks. Most existing NAS approaches require one complete search for each deployment specification of hardware or objective. This is a computationally impractical endeavor given the potentially large number of application scenarios. In this paper, we propose Neural Architecture Transfer (NAT) to overcome this limitation. NAT is designed to efficiently generate task-specific custom models that are competitive even under multiple conflicting objectives. To realize this goal we learn task-specific supernets from which specialized subnets can be sampled without any additional training. The key to our approach is an integrated online transfer learning and many-objective evolutionary search procedure. A pre-trained supernet is iteratively adapted while simultaneously searching for task-specific subnets. We demonstrate the efficacy of NAT on 11 benchmark image classification tasks ranging from large-scale multi-class to small-scale fine-grained datasets. In all cases, including ImageNet, NATNets improve upon the state-of-the-art under mobile settings ($\leq$ 600M Multiply-Adds). Surprisingly, small-scale fine-grained datasets benefit the most from NAT. At the same time, the architecture search and transfer is orders of magnitude more efficient than existing NAS methods. Overall, experimental evaluation indicates that across diverse image classification tasks and computational objectives, NAT is an appreciably more effective alternative to fine-tuning based transfer learning. Code is available at https://github.com/human-analysis/neural-architecture-transfer
It is Time for New Perspectives on How to Fight Bloat in GP
May 01, 2020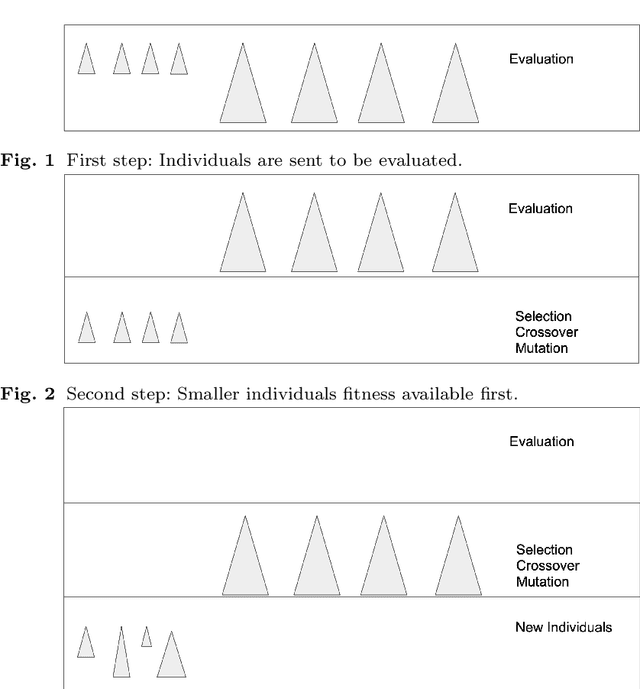
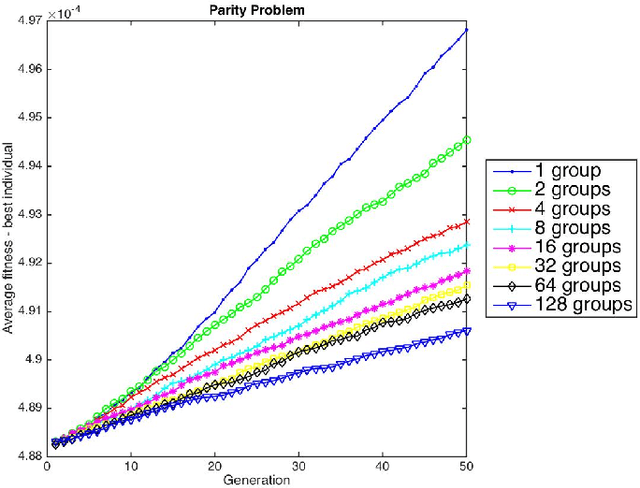
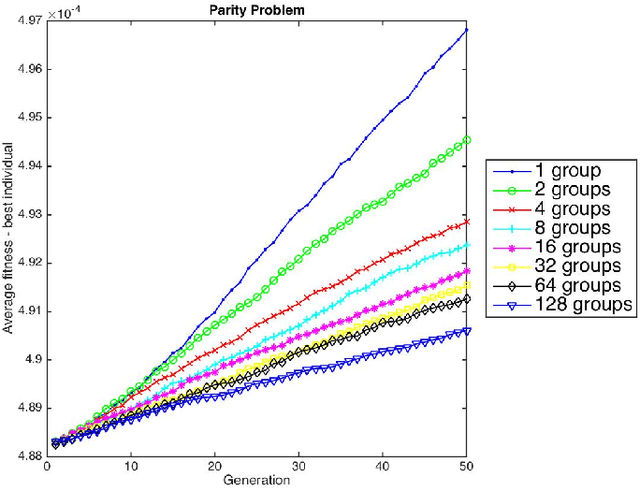
The present and future of evolutionary algorithms depends on the proper use of modern parallel and distributed computing infrastructures. Although still sequential approaches dominate the landscape, available multi-core, many-core and distributed systems will make users and researchers to more frequently deploy parallel version of the algorithms. In such a scenario, new possibilities arise regarding the time saved when parallel evaluation of individuals are performed. And this time saving is particularly relevant in Genetic Programming. This paper studies how evaluation time influences not only time to solution in parallel/distributed systems, but may also affect size evolution of individuals in the population, and eventually will reduce the bloat phenomenon GP features. This paper considers time and space as two sides of a single coin when devising a more natural method for fighting bloat. This new perspective allows us to understand that new methods for bloat control can be derived, and the first of such a method is described and tested. Experimental data confirms the strength of the approach: using computing time as a measure of individuals' complexity allows to control the growth in size of genetic programming individuals.
Multi-Criterion Evolutionary Design of Deep Convolutional Neural Networks
Dec 03, 2019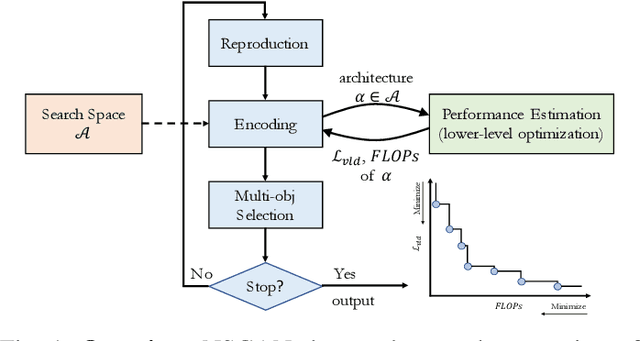
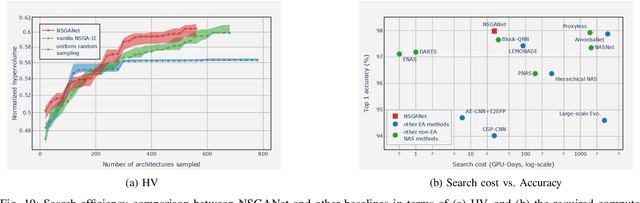
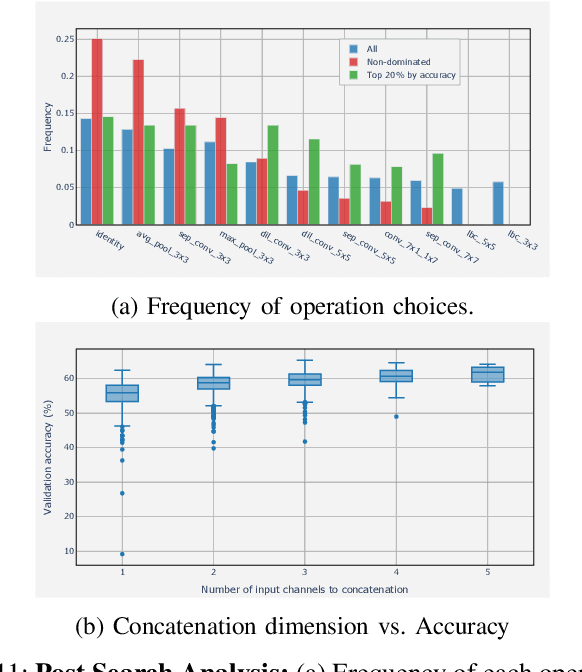
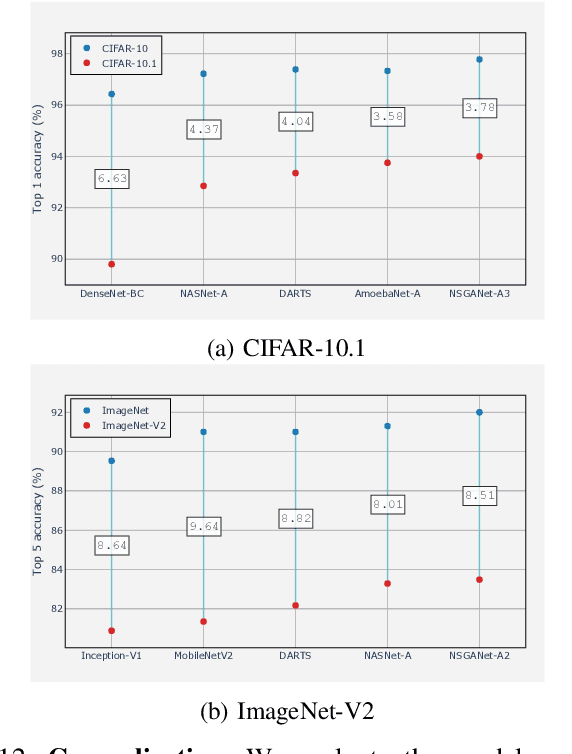
Convolutional neural networks (CNNs) are the backbones of deep learning paradigms for numerous vision tasks. Early advancements in CNN architectures are primarily driven by human expertise and elaborate design. Recently, neural architecture search was proposed with the aim of automating the network design process and generating task-dependent architectures. While existing approaches have achieved competitive performance in image classification, they are not well suited under limited computational budget for two reasons: (1) the obtained architectures are either solely optimized for classification performance or only for one targeted resource requirement; (2) the search process requires vast computational resources in most approaches. To overcome this limitation, we propose an evolutionary algorithm for searching neural architectures under multiple objectives, such as classification performance and FLOPs. The proposed method addresses the first shortcoming by populating a set of architectures to approximate the entire Pareto frontier through genetic operations that recombine and modify architectural components progressively. Our approach improves the computation efficiency by carefully down-scaling the architectures during the search as well as reinforcing the patterns commonly shared among the past successful architectures through Bayesian Learning. The integration of these two main contributions allows an efficient design of architectures that are competitive and in many cases outperform both manually and automatically designed architectures on benchmark image classification datasets, CIFAR, ImageNet and human chest X-ray. The flexibility provided from simultaneously obtaining multiple architecture choices for different compute requirements further differentiates our approach from other methods in the literature.
Embedding Push and Pull Search in the Framework of Differential Evolution for Solving Constrained Single-objective Optimization Problems
Dec 16, 2018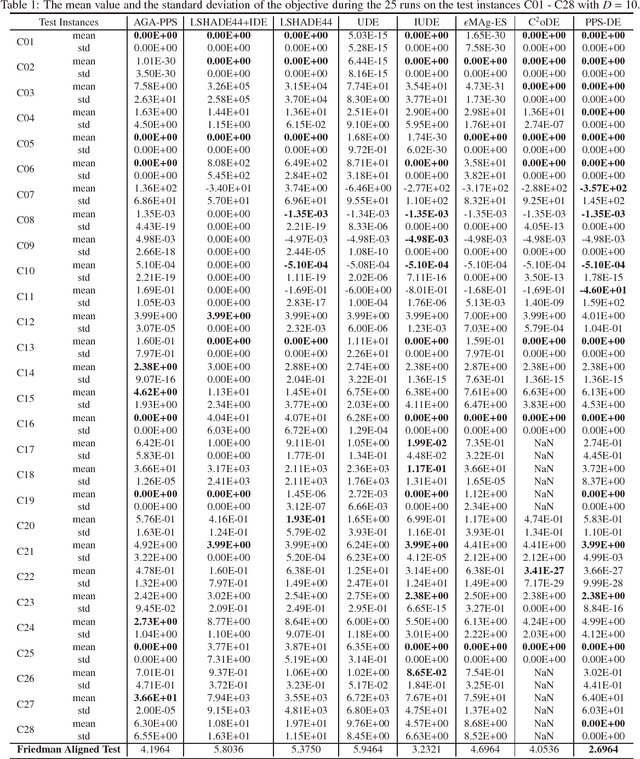
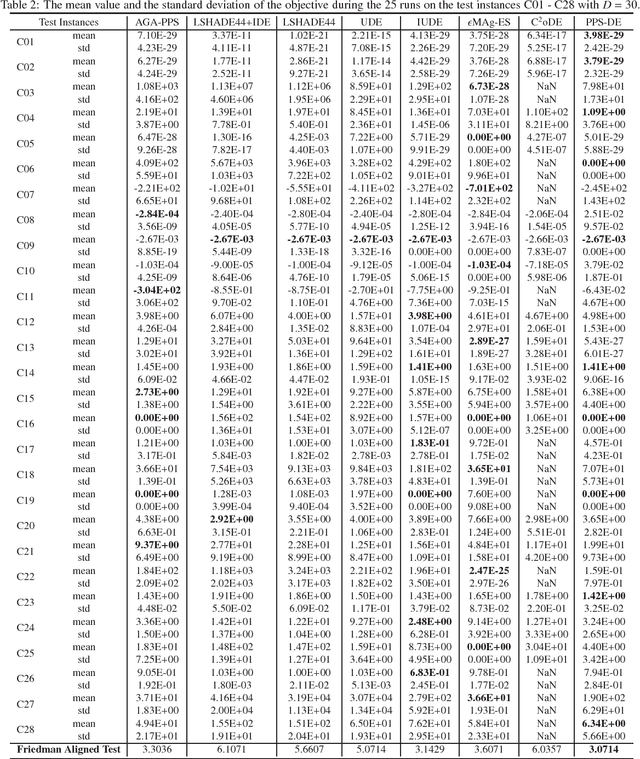
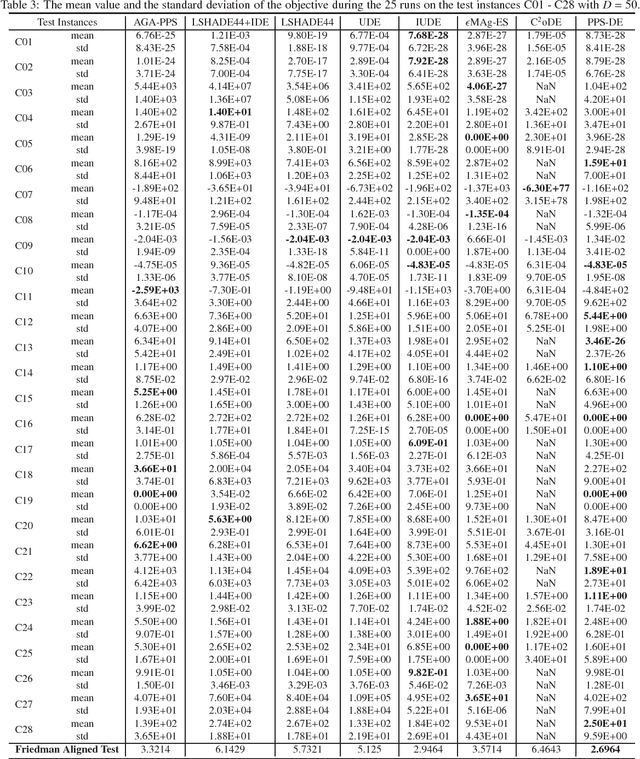
This paper proposes a push and pull search method in the framework of differential evolution (PPS-DE) to solve constrained single-objective optimization problems (CSOPs). More specifically, two sub-populations, including the top and bottom sub-populations, are collaborated with each other to search global optimal solutions efficiently. The top sub-population adopts the pull and pull search (PPS) mechanism to deal with constraints, while the bottom sub-population use the superiority of feasible solutions (SF) technique to deal with constraints. In the top sub-population, the search process is divided into two different stages --- push and pull stages.An adaptive DE variant with three trial vector generation strategies is employed in the proposed PPS-DE. In the top sub-population, all the three trial vector generation strategies are used to generate offsprings, just like in CoDE. In the bottom sub-population, a strategy adaptation, in which the trial vector generation strategies are periodically self-adapted by learning from their experiences in generating promising solutions in the top sub-population, is used to choose a suitable trial vector generation strategy to generate one offspring. Furthermore, a parameter adaptation strategy from LSHADE44 is employed in both sup-populations to generate scale factor $F$ and crossover rate $CR$ for each trial vector generation strategy. Twenty-eight CSOPs with 10-, 30-, and 50-dimensional decision variables provided in the CEC2018 competition on real parameter single objective optimization are optimized by the proposed PPS-DE. The experimental results demonstrate that the proposed PPS-DE has the best performance compared with the other seven state-of-the-art algorithms, including AGA-PPS, LSHADE44, LSHADE44+IDE, UDE, IUDE, $\epsilon$MAg-ES and C$^2$oDE.
NSGA-NET: A Multi-Objective Genetic Algorithm for Neural Architecture Search
Oct 08, 2018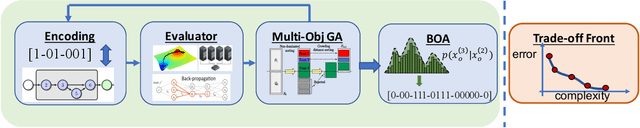
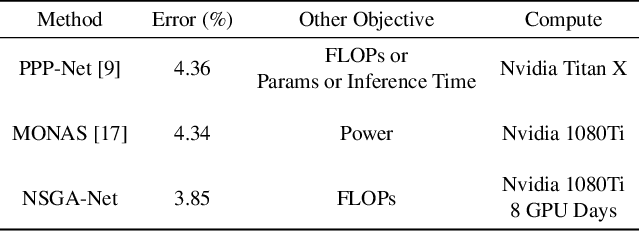

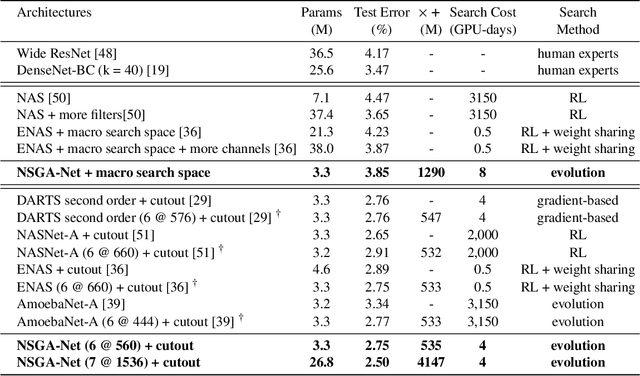
This paper introduces NSGA-Net, an evolutionary approach for neural architecture search (NAS). NSGA-Net is designed with three goals in mind: (1) a NAS procedure for multiple, possibly conflicting, objectives, (2) efficient exploration and exploitation of the space of potential neural network architectures, and (3) output of a diverse set of network architectures spanning a trade-off frontier of the objectives in a single run. NSGA-Net is a population-based search algorithm that explores a space of potential neural network architectures in three steps, namely, a population initialization step that is based on prior-knowledge from hand-crafted architectures, an exploration step comprising crossover and mutation of architectures and finally an exploitation step that applies the entire history of evaluated neural architectures in the form of a Bayesian Network prior. Experimental results suggest that combining the objectives of minimizing both an error metric and computational complexity, as measured by FLOPS, allows NSGA-Net to find competitive neural architectures near the Pareto front of both objectives on two different tasks, object classification and object alignment. NSGA-Net obtains networks that achieve 3.72% (at 4.5 million FLOP) error on CIFAR-10 classification and 8.64% (at 26.6 million FLOP) error on the CMU-Car alignment task. Code available at: https://github.com/ianwhale/nsga-net
MOEA/D with Angle-based Constrained Dominance Principle for Constrained Multi-objective Optimization Problems
Feb 10, 2018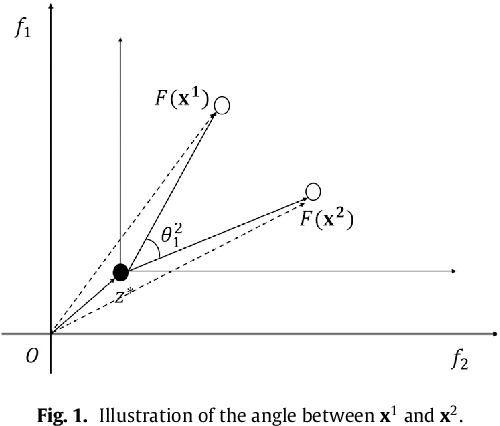
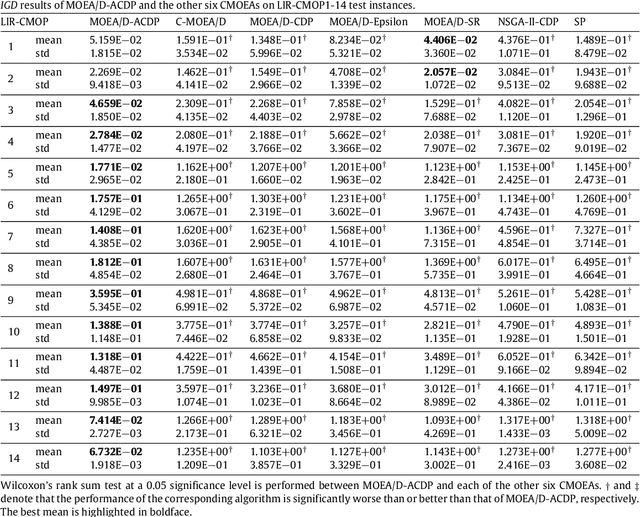
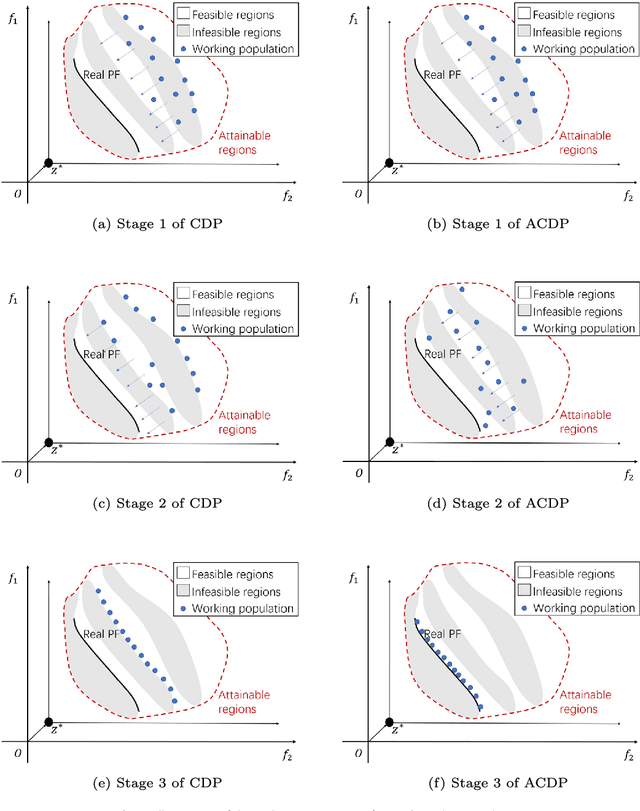
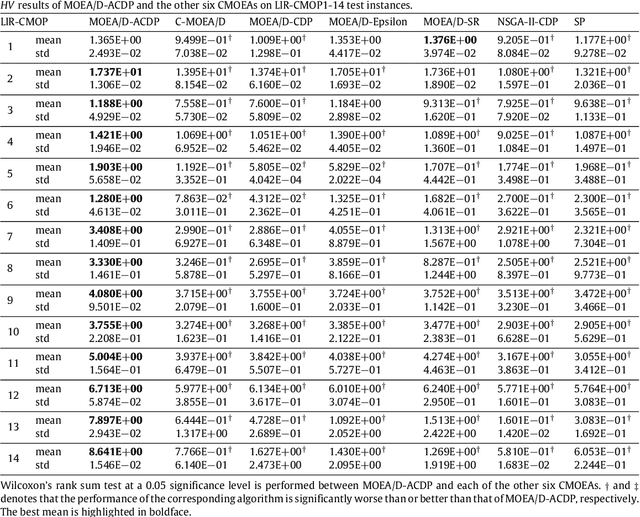
This paper proposes a novel constraint-handling mechanism named angle-based constrained dominance principle (ACDP) embedded in a decomposition-based multi-objective evolutionary algorithm (MOEA/D) to solve constrained multi-objective optimization problems (CMOPs). To maintain the diversity of the working population, ACDP utilizes the information of the angle of solutions to adjust the dominance relation of solutions during the evolutionary process. This paper uses 14 benchmark instances to evaluate the performance of the MOEA/D with ACDP (MOEA/D-ACDP). Additionally, an engineering optimization problem (which is I-beam optimization problem) is optimized. The proposed MOEA/D-ACDP, and four other decomposition-based CMOEAs, including C-MOEA/D, MOEA/D-CDP, MOEA/D-Epsilon and MOEA/D-SR are tested by the above benchmarks and the engineering application. The experimental results manifest that MOEA/D-ACDP is significantly better than the other four CMOEAs on these test instances and the real-world case, which indicates that ACDP is more effective for solving CMOPs.
Modeling and Multi-objective Optimization of a Kind of Teaching Manipulator
Jan 31, 2018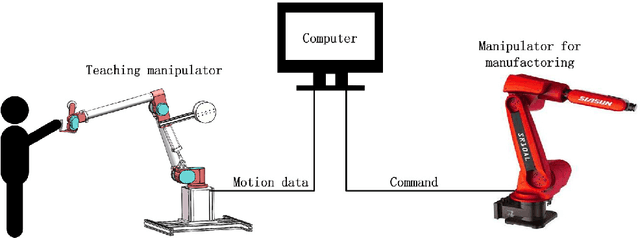

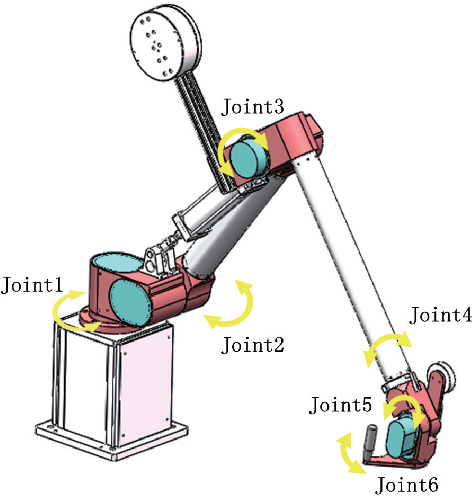
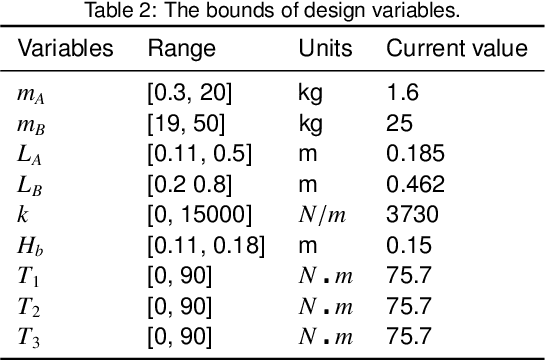
A new kind of six degree-of-freedom teaching manipulator without actuators is designed, for recording and conveniently setting a trajectory of an industrial robot. The device requires good gravity balance and operating force performance to ensure being controlled easily and fluently. In this paper, we propose a process for modeling the manipulator and then the model is used to formulate a multi-objective optimization problem to optimize the design of the testing manipulator. Three objectives, including total mass of the device, gravity balancing and operating force performance are analyzed and defined. A popular non-dominated sorting genetic algorithm (NSGA-II-CDP) is used to solve the optimization problem. The obtained solutions all outperform the design of a human expert. To extract design knowledge, an innovization study is performed to establish meaningful implicit relationship between the objective space and the decision space, which can be reused by the designer in future design process.