 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effects of Population Size on the Performance of BEAGLE GPU-Based Genetic Programming Runs
Apr 27, 2026The Beagle framework, through GPU-based Genetic Programming, enables population dynamics previously unattainable (within practical time frames) by CPU-constrained Genetic Programming systems. This work explores how GPU-enabled population sizes impact the success of training for symbolic regression problems. Specifically, when using constant population sizes, we see benefits of using very narrow and deep searches (as narrow as 1000 individuals) for some problems, while other problems benefit from very broad and shallow searches (as broad as 10 million individuals). We also explore stepped population sizes that start with large populations and drop to small populations to balance the breadth and depth of search.
EvoIQA - Explaining Image Distortions with Evolved White-Box Logic
Mar 16, 2026Traditional Image Quality Assessment (IQA) metrics typically fall into one of two extremes: rigid, hand-crafted mathematical models or "black-box" deep learning architectures that completely lack interpretability. To bridge this gap, we propose EvoIQA, a fully explainable symbolic regression framework based on Genetic Programming that Evolves explicit, human-readable mathematical formulas for image quality assessment (IQA). Utilizing a rich terminal set from the VSI, VIF, FSIM, and HaarPSI metrics, our framework inherently maps structural, chromatic, and information-theoretic degradations into observable mathematical equations. Our results demonstrate that the evolved GP models consistently achieve strong alignment between the predictions and human visual preferences. Furthermore, they not only outperform traditional hand-crafted metrics but also achieve performance parity with complex, state-of-the-art deep learning models like DB-CNN, proving that we no longer have to sacrifice interpretability for state-of-the-art performance.
GPU-Accelerated Genetic Programming for Symbolic Regression with Beagle Framework
Mar 10, 2026Beagle is a new software framework that enables execution of Genetic Programming tasks on the GPU. Currently available for symbolic regression, it processes individuals of the population and fitness cases for training in a way that maximizes throughput on extant GPU platforms. In this contribution, we report on the benchmarking of Beagle on the Feynman Symbolic Regression dataset and compare its performance with a fast CPU system called StackGP and the widely available PySR system under the same wall clock budget. We also report on the use of two different fitness functions, one a point-to-point error function, the other a correlation fitness function. The results demonstrate that the Beagle's GPU-aided Symbolic Regression significantly outperforms leading CPU-based frameworks.
Enhancing Generalization in Evolutionary Feature Construction for Symbolic Regression through Vicinal Jensen Gap Minimization
Feb 02, 2026Genetic programming-based feature construction has achieved significant success in recent years as an automated machine learning technique to enhance learning performance. However, overfitting remains a challenge that limits its broader applicability. To improve generalization, we prove that vicinal risk, estimated through noise perturbation or mixup-based data augmentation, is bounded by the sum of empirical risk and a regularization term-either finite difference or the vicinal Jensen gap. Leveraging this decomposition, we propose an evolutionary feature construction framework that jointly optimizes empirical risk and the vicinal Jensen gap to control overfitting. Since datasets may vary in noise levels, we develop a noise estimation strategy to dynamically adjust regularization strength. Furthermore, to mitigate manifold intrusion-where data augmentation may generate unrealistic samples that fall outside the data manifold-we propose a manifold intrusion detection mechanism. Experimental results on 58 datasets demonstrate the effectiveness of Jensen gap minimization compared to other complexity measures. Comparisons with 15 machine learning algorithms further indicate that genetic programming with the proposed overfitting control strategy achieves superior performance.
ECLIPSE: An Evolutionary Computation Library for Instrumentation Prototyping in Scientific Engineering
Jan 08, 2026Designing scientific instrumentation often requires exploring large, highly constrained design spaces using computationally expensive physics simulations. These simulators pose substantial challenges for integrating evolutionary computation (EC) into scientific design workflows. Evolutionary computation typically requires numerous design evaluations, making the integration of slow, low-throughput simulators particularly challenging, as they are optimized for accuracy and ease of use rather than throughput. We present ECLIPSE, an evolutionary computation framework built to interface directly with complex, domain-specific simulation tools while supporting flexible geometric and parametric representations of scientific hardware. ECLIPSE provides a modular architecture consisting of (1) Individuals, which encode hardware designs using domain-aware, physically constrained representations; (2) Evaluators, which prepare simulation inputs, invoke external simulators, and translate the simulator's outputs into fitness measures; and (3) Evolvers, which implement EC algorithms suitable for high-cost, limited-throughput environments. We demonstrate the utility of ECLIPSE across several active space-science applications, including evolved 3D antennas and spacecraft geometries optimized for drag reduction in very low Earth orbit. We further discuss the practical challenges encountered when coupling EC with scientific simulation workflows, including interoperability constraints, parallelization limits, and extreme evaluation costs, and outline ongoing efforts to combat these challenges. ECLIPSE enables interdisciplinary teams of physicists, engineers, and EC researchers to collaboratively explore unconventional designs for scientific hardware while leveraging existing domain-specific simulation software.
Bridging Fitness With Search Spaces By Fitness Supremums: A Theoretical Study on LGP
May 28, 2025Genetic programming has undergone rapid development in recent years. However, theoretical studies of genetic programming are far behind. One of the major obstacles to theoretical studies is the challenge of developing a model to describe the relationship between fitness values and program genotypes. In this paper, we take linear genetic programming (LGP) as an example to study the fitness-to-genotype relationship. We find that the fitness expectation increases with fitness supremum over instruction editing distance, considering 1) the fitness supremum linearly increases with the instruction editing distance in LGP, 2) the fitness infimum is fixed, and 3) the fitness probabilities over different instruction editing distances are similar. We then extend these findings to explain the bloat effect and the minimum hitting time of LGP based on instruction editing distance. The bloat effect happens because it is more likely to produce better offspring by adding instructions than by removing them, given an instruction editing distance from the optimal program. The analysis of the minimum hitting time suggests that for a basic LGP genetic operator (i.e., freemut), maintaining a necessarily small program size and mutating multiple instructions each time can improve LGP performance. The reported empirical results verify our hypothesis.
Multi-Representation Genetic Programming: A Case Study on Tree-based and Linear Representations
May 23, 2024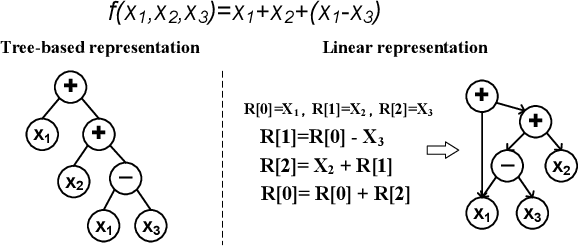

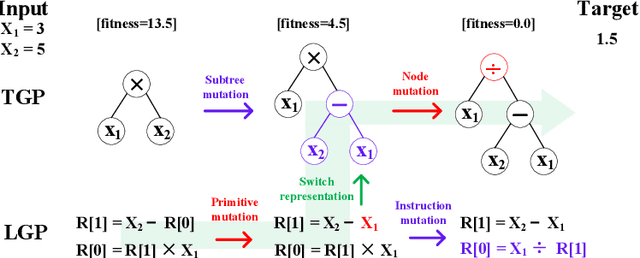
Existing genetic programming (GP) methods are typically designed based on a certain representation, such as tree-based or linear representations. These representations show various pros and cons in different domains. However, due to the complicated relationships among representation and fitness landscapes of GP, it is hard to intuitively determine which GP representation is the most suitable for solving a certain problem. Evolving programs (or models) with multiple representations simultaneously can alternatively search on different fitness landscapes since representations are highly related to the search space that essentially defines the fitness landscape. Fully using the latent synergies among different GP individual representations might be helpful for GP to search for better solutions. However, existing GP literature rarely investigates the simultaneous effective use of evolving multiple representations. To fill this gap, this paper proposes a multi-representation GP algorithm based on tree-based and linear representations, which are two commonly used GP representations. In addition, we develop a new cross-representation crossover operator to harness the interplay between tree-based and linear representations. Empirical results show that navigating the learned knowledge between basic tree-based and linear representations successfully improves the effectiveness of GP with solely tree-based or linear representation in solving symbolic regression and dynamic job shop scheduling problems.
Sharpness-Aware Minimization in Genetic Programming
May 17, 2024



Sharpness-Aware Minimization (SAM) was recently introduced as a regularization procedure for training deep neural networks. It simultaneously minimizes the fitness (or loss) function and the so-called fitness sharpness. The latter serves as a measure of the nonlinear behavior of a solution and does so by finding solutions that lie in neighborhoods having uniformly similar loss values across all fitness cases. In this contribution, we adapt SAM for tree Genetic Programming (TGP) by exploring the semantic neighborhoods of solutions using two simple approaches. By capitalizing upon perturbing input and output of program trees, sharpness can be estimated and used as a second optimization criterion during the evolution. To better understand the impact of this variant of SAM on TGP, we collect numerous indicators of the evolutionary process, including generalization ability, complexity, diversity, and a recently proposed genotype-phenotype mapping to study the amount of redundancy in trees. The experimental results demonstrate that using any of the two proposed SAM adaptations in TGP allows (i) a significant reduction of tree sizes in the population and (ii) a decrease in redundancy of the trees. When assessed on real-world benchmarks, the generalization ability of the elite solutions does not deteriorate.
Sharpness-Aware Minimization for Evolutionary Feature Construction in Regression
May 11, 2024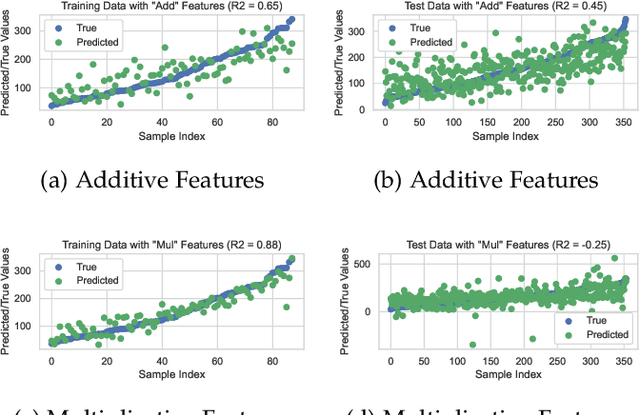

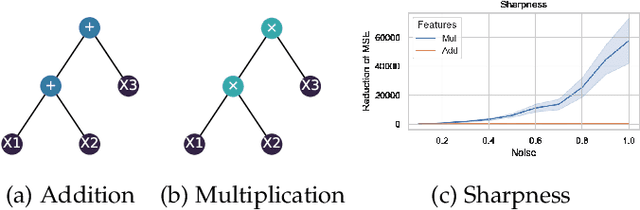

In recent years, genetic programming (GP)-based evolutionary feature construction has achieved significant success. However, a primary challenge with evolutionary feature construction is its tendency to overfit the training data, resulting in poor generalization on unseen data. In this research, we draw inspiration from PAC-Bayesian theory and propose using sharpness-aware minimization in function space to discover symbolic features that exhibit robust performance within a smooth loss landscape in the semantic space. By optimizing sharpness in conjunction with cross-validation loss, as well as designing a sharpness reduction layer, the proposed method effectively mitigates the overfitting problem of GP, especially when dealing with a limited number of instances or in the presence of label noise. Experimental results on 58 real-world regression datasets show that our approach outperforms standard GP as well as six state-of-the-art complexity measurement methods for GP in controlling overfitting. Furthermore, the ensemble version of GP with sharpness-aware minimization demonstrates superior performance compared to nine fine-tuned machine learning and symbolic regression algorithms, including XGBoost and LightGBM.
On The Nature Of The Phenotype In Tree Genetic Programming
Feb 12, 2024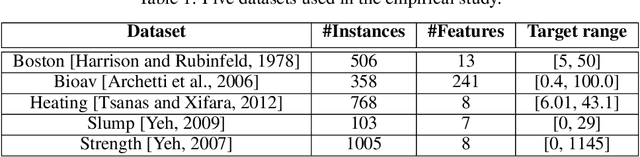
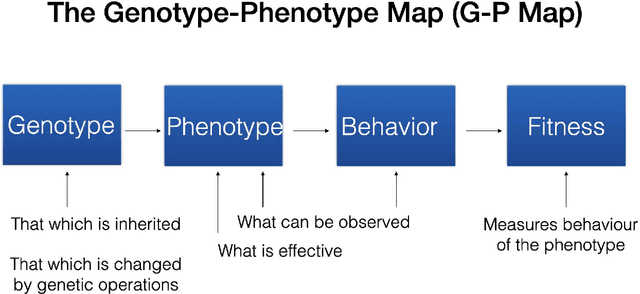
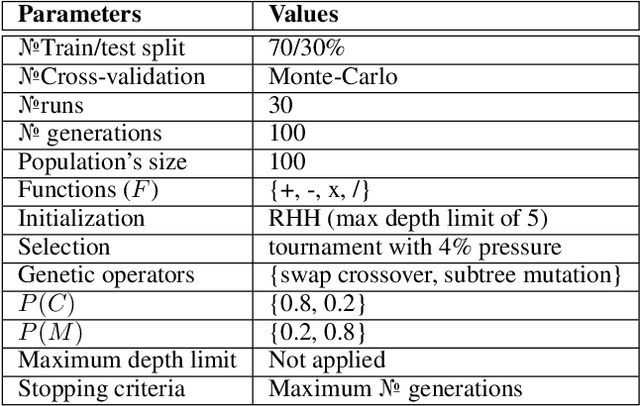
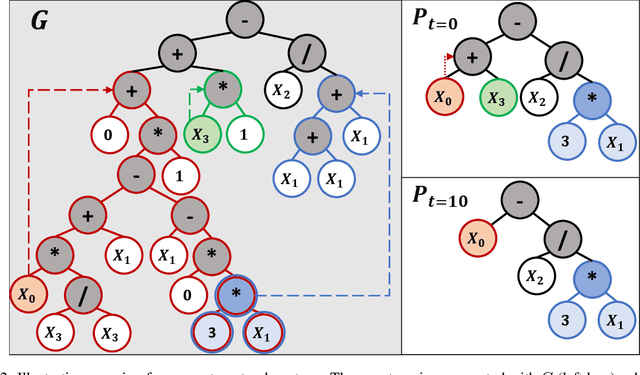
In this contribution, we discuss the basic concepts of genotypes and phenotypes in tree-based GP (TGP), and then analyze their behavior using five benchmark datasets. We show that TGP exhibits the same behavior that we can observe in other GP representations: At the genotypic level trees show frequently unchecked growth with seemingly ineffective code, but on the phenotypic level, much smaller trees can be observed. To generate phenotypes, we provide a unique technique for removing semantically ineffective code from GP trees. The approach extracts considerably simpler phenotypes while not being limited to local operations in the genotype. We generalize this transformation based on a problem-independent parameter that enables a further simplification of the exact phenotype by coarse-graining to produce approximate phenotypes. The concept of these phenotypes (exact and approximate) allows us to clarify what evolved solutions truly predict, making GP models considered at the phenotypic level much better interpretable.