 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATR-UMMIM: A Benchmark Dataset for UAV-Based Multimodal Image Registration under Complex Imaging Conditions
Jul 28, 2025Multimodal fusion has become a key enabler for UAV-based object detection, as each modality provides complementary cues for robust feature extraction. However, due to significant differences in resolution, field of view, and sensing characteristics across modalities, accurate registration is a prerequisite before fusion. Despite its importance, there is currently no publicly available benchmark specifically designed for multimodal registration in UAV-based aerial scenarios, which severely limits the development and evaluation of advanced registration methods under real-world conditions. To bridge this gap, we present ATR-UMMIM, the first benchmark dataset specifically tailored for multimodal image registration in UAV-based applications. This dataset includes 7,969 triplets of raw visible, infrared, and precisely registered visible images captured covers diverse scenarios including flight altitudes from 80m to 300m, camera angles from 0{\deg} to 75{\deg}, and all-day, all-year temporal variations under rich weather and illumination conditions. To ensure high registration quality, we design a semi-automated annotation pipeline to introduce reliable pixel-level ground truth to each triplet. In addition, each triplet is annotated with six imaging condition attributes, enabling benchmarking of registration robustness under real-world deployment settings. To further support downstream tasks, we provide object-level annotations on all registered images, covering 11 object categories with 77,753 visible and 78,409 infrared bounding boxes. We believe ATR-UMMIM will serve as a foundational benchmark for advancing multimodal registration, fusion, and perception in real-world UAV scenarios. The datatset can be download from https://github.com/supercpy/ATR-UMMIM
MoESD: Unveil Speculative Decoding's Potential for Accelerating Sparse MoE
May 26, 2025Large Language Models (LLMs) have achieved remarkable success across many applications, with Mixture of Experts (MoE) models demonstrating great potential. Compared to traditional dense models, MoEs achieve better performance with less computation. Speculative decoding (SD) is a widely used technique to accelerate LLM inference without accuracy loss, but it has been considered efficient only for dense models. In this work, we first demonstrate that, under medium batch sizes, MoE surprisingly benefits more from SD than dense models. Furthermore, as MoE becomes sparser -- the prevailing trend in MoE designs -- the batch size range where SD acceleration is expected to be effective becomes broader. To quantitatively understand tradeoffs involved in SD, we develop a reliable modeling based on theoretical analyses. While current SD research primarily focuses on improving acceptance rates of algorithms, changes in workload and model architecture can still lead to degraded SD acceleration even with high acceptance rates. To address this limitation, we introduce a new metric 'target efficiency' that characterizes these effects, thus helping researchers identify system bottlenecks and understand SD acceleration more comprehensively. For scenarios like private serving, this work unveils a new perspective to speed up MoE inference, where existing solutions struggle. Experiments on different GPUs show up to 2.29x speedup for Qwen2-57B-A14B at medium batch sizes and validate our theoretical predictions.
FastAttention: Extend FlashAttention2 to NPUs and Low-resource GPUs
Oct 22, 2024



FlashAttention series has been widely applied in the inference of large language models (LLMs). However, FlashAttention series only supports the high-level GPU architectures, e.g., Ampere and Hopper. At present, FlashAttention series is not easily transferrable to NPUs and low-resource GPUs. Moreover, FlashAttention series is inefficient for multi- NPUs or GPUs inference scenarios. In this work, we propose FastAttention which pioneers the adaptation of FlashAttention series for NPUs and low-resource GPUs to boost LLM inference efficiency. Specifically, we take Ascend NPUs and Volta-based GPUs as representatives for designing our FastAttention. We migrate FlashAttention series to Ascend NPUs by proposing a novel two-level tiling strategy for runtime speedup, tiling-mask strategy for memory saving and the tiling-AllReduce strategy for reducing communication overhead, respectively. Besides, we adapt FlashAttention for Volta-based GPUs by redesigning the operands layout in shared memory and introducing a simple yet effective CPU-GPU cooperative strategy for efficient memory utilization. On Ascend NPUs, our FastAttention can achieve a 10.7$\times$ speedup compared to the standard attention implementation. Llama-7B within FastAttention reaches up to 5.16$\times$ higher throughput than within the standard attention. On Volta architecture GPUs, FastAttention yields 1.43$\times$ speedup compared to its equivalents in \texttt{xformers}. Pangu-38B within FastAttention brings 1.46$\times$ end-to-end speedup using FasterTransformer. Coupled with the propose CPU-GPU cooperative strategy, FastAttention supports a maximal input length of 256K on 8 V100 GPUs. All the codes will be made available soon.
Evolutionary Computation and Explainable AI: A Roadmap to Transparent Intelligent Systems
Jun 12, 2024



AI methods are finding an increasing number of applications, but their often black-box nature has raised concerns about accountability and trust. The field of explainable artificial intelligence (XAI) has emerged in response to the need for human understanding of AI models. Evolutionary computation (EC), as a family of powerful optimization and learning tools, has significant potential to contribute to XAI. In this paper, we provide an introduction to XAI and review various techniques in current use for explaining machine learning (ML) models. We then focus on how EC can be used in XAI, and review some XAI approaches which incorporate EC techniques. Additionally, we discuss the application of XAI principles within EC itself, examining how these principles can shed some light on the behavior and outcomes of EC algorithms in general, on the (automatic) configuration of these algorithms, and on the underlying problem landscapes that these algorithms optimize. Finally, we discuss some open challenges in XAI and opportunities for future research in this field using EC. Our aim is to demonstrate that EC is well-suited for addressing current problems in explainability and to encourage further exploration of these methods to contribute to the development of more transparent and trustworthy ML models and EC algorithms.
Scaled Prompt-Tuning for Few-Shot Natural Language Generation
Sep 13, 2023



The increasingly Large Language Models (LLMs) demonstrate stronger language understanding and generation capabilities, while the memory demand and computation cost of fine-tuning LLMs on downstream tasks are non-negligible. Besides, fine-tuning generally requires a certain amount of data from individual tasks whilst data collection cost is another issue to consider in real-world applications. In this work, we focus on Parameter-Efficient Fine-Tuning (PEFT) methods for few-shot Natural Language Generation (NLG), which freeze most parameters in LLMs and tune a small subset of parameters in few-shot cases so that memory footprint, training cost, and labeling cost are reduced while maintaining or even improving the performance. We propose a Scaled Prompt-Tuning (SPT) method which surpasses conventional PT with better performance and generalization ability but without an obvious increase in training cost. Further study on intermediate SPT suggests the superior transferability of SPT in few-shot scenarios, providing a recipe for data-deficient and computation-limited circumstances. Moreover, a comprehensive comparison of existing PEFT methods reveals that certain approaches exhibiting decent performance with modest training cost such as Prefix-Tuning in prior study could struggle in few-shot NLG tasks, especially on challenging datasets.
Genetic heterogeneity analysis using genetic algorithm and network science
Aug 12, 2023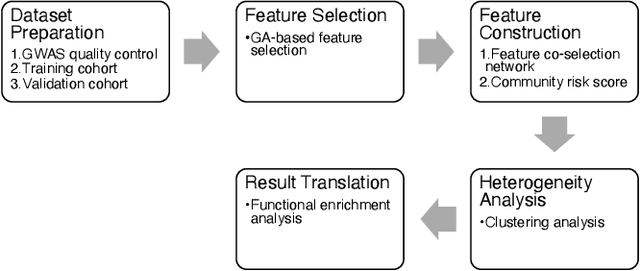


Through genome-wide association studies (GWAS), disease susceptible genetic variables can be identified by comparing the genetic data of individuals with and without a specific disease. However, the discovery of these associations poses a significant challenge due to genetic heterogeneity and feature interactions. Genetic variables intertwined with these effects often exhibit lower effect-size, and thus can be difficult to be detected using machine learning feature selection methods. To address these challenges, this paper introduces a novel feature selection mechanism for GWAS, named Feature Co-selection Network (FCSNet). FCS-Net is designed to extract heterogeneous subsets of genetic variables from a network constructed from multiple independent feature selection runs based on a genetic algorithm (GA), an evolutionary learning algorithm. We employ a non-linear machine learning algorithm to detect feature interaction. We introduce the Community Risk Score (CRS), a synthetic feature designed to quantify the collective disease association of each variable subset. Our experiment showcases the effectiveness of the utilized GA-based feature selection method in identifying feature interactions through synthetic data analysis. Furthermore, we apply our novel approach to a case-control colorectal cancer GWAS dataset. The resulting synthetic features are then used to explain the genetic heterogeneity in an additional case-only GWAS dataset.
Evolutionary approaches to explainable machine learning
Jun 23, 2023Machine learning models are increasingly being used in critical sectors, but their black-box nature has raised concerns about accountability and trust. The field of explainable artificial intelligence (XAI) or explainable machine learning (XML) has emerged in response to the need for human understanding of these models. Evolutionary computing, as a family of powerful optimization and learning tools, has significant potential to contribute to XAI/XML. In this chapter, we provide a brief introduction to XAI/XML and review various techniques in current use for explaining machine learning models. We then focus on how evolutionary computing can be used in XAI/XML, and review some approaches which incorporate EC techniques. We also discuss some open challenges in XAI/XML and opportunities for future research in this field using EC. Our aim is to demonstrate that evolutionary computing is well-suited for addressing current problems in explainability, and to encourage further exploration of these methods to contribute to the development of more transparent, trustworthy and accountable machine learning models.
Phenotype Search Trajectory Networks for Linear Genetic Programming
Nov 15, 2022Genotype-to-phenotype mappings translate genotypic variations such as mutations into phenotypic changes. Neutrality is the observation that some mutations do not lead to phenotypic changes. Studying the search trajectories in genotypic and phenotypic spaces, especially through neutral mutations, helps us to better understand the progression of evolution and its algorithmic behaviour. In this study, we visualise the search trajectories of a genetic programming system as graph-based models, where nodes are genotypes/phenotypes and edges represent their mutational transitions. We also quantitatively measure the characteristics of phenotypes including their genotypic abundance (the requirement for neutrality) and Kolmogorov complexity. We connect these quantified metrics with search trajectory visualisations, and find that more complex phenotypes are under-represented by fewer genotypes and are harder for evolution to discover. Less complex phenotypes, on the other hand, are over-represented by genotypes, are easier to find, and frequently serve as stepping-stones for evolution.
Empirical Evaluation of Post-Training Quantization Methods for Language Tasks
Oct 29, 2022



Transformer-based architectures like BERT have achieved great success in a wide range of Natural Language tasks. Despite their decent performance, the models still have numerous parameters and high computational complexity, impeding their deployment in resource-constrained environments. Post-Training Quantization (PTQ), which enables low-bit computations without extra training, could be a promising tool. In this work, we conduct an empirical evaluation of three PTQ methods on BERT-Base and BERT-Large: Linear Quantization (LQ), Analytical Clipping for Integer Quantization (ACIQ), and Outlier Channel Splitting (OCS). OCS theoretically surpasses the others in minimizing the Mean Square quantization Error and avoiding distorting the weights' outliers. That is consistent with the evaluation results of most language tasks of GLUE benchmark and a reading comprehension task, SQuAD. Moreover, low-bit quantized BERT models could outperform the corresponding 32-bit baselines on several small language tasks, which we attribute to the alleviation of over-parameterization. We further explore the limit of quantization bit and show that OCS could quantize BERT-Base and BERT-Large to 3-bits and retain 98% and 96% of the performance on the GLUE benchmark accordingly. Moreover, we conduct quantization on the whole BERT family, i.e., BERT models in different configurations, and comprehensively evaluate their performance on the GLUE benchmark and SQuAD, hoping to provide valuable guidelines for their deployment in various computation environments.
A spectral-spatial fusion anomaly detection method for hyperspectral imagery
Feb 24, 2022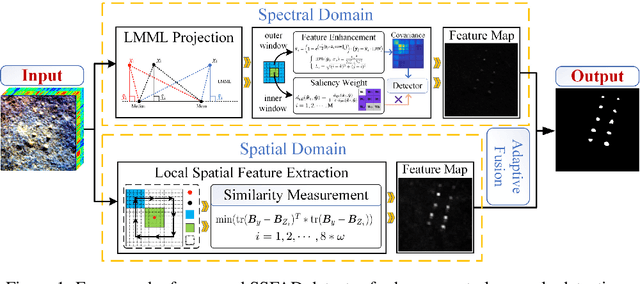
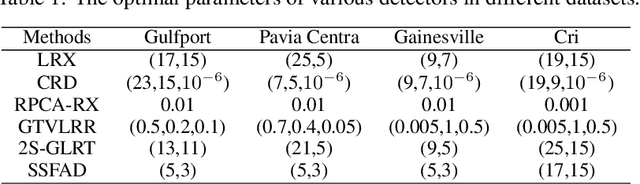
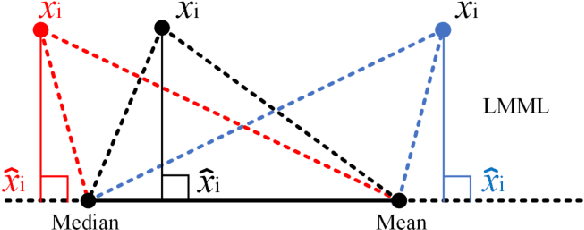
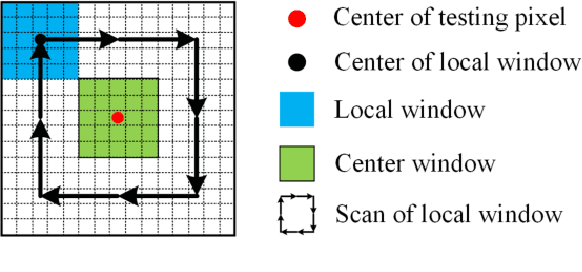
In hyperspectral, high-quality spectral signals convey subtle spectral differences to distinguish similar materials, thereby providing unique advantage for anomaly detection. Hence fine spectra of anomalous pixels can be effectively screened out from heterogeneous background pixels. Since the same materials have similar characteristics in spatial and spectral dimension, detection performance can be significantly enhanced by jointing spatial and spectral information. In this paper, a spectralspatial fusion anomaly detection (SSFAD) method is proposed for hyperspectral imagery. First, original spectral signals are mapped to a local linear background space composed of median and mean with high confidence, where saliency weight and feature enhancement strategies are implemented to obtain an initial detection map in spectral domain. Futhermore, to make full use of similarity information of local background around testing pixel, a new detector is designed to extract the local similarity spatial features of patch images in spatial domain. Finally, anomalies are detected by adaptively combining the spectral and spatial detection maps. The experimental results demonstrate that our proposed method has superior detection performance than traditional methods.