 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Generalization in Evolutionary Feature Construction for Symbolic Regression through Vicinal Jensen Gap Minimization
Feb 02, 2026Genetic programming-based feature construction has achieved significant success in recent years as an automated machine learning technique to enhance learning performance. However, overfitting remains a challenge that limits its broader applicability. To improve generalization, we prove that vicinal risk, estimated through noise perturbation or mixup-based data augmentation, is bounded by the sum of empirical risk and a regularization term-either finite difference or the vicinal Jensen gap. Leveraging this decomposition, we propose an evolutionary feature construction framework that jointly optimizes empirical risk and the vicinal Jensen gap to control overfitting. Since datasets may vary in noise levels, we develop a noise estimation strategy to dynamically adjust regularization strength. Furthermore, to mitigate manifold intrusion-where data augmentation may generate unrealistic samples that fall outside the data manifold-we propose a manifold intrusion detection mechanism. Experimental results on 58 datasets demonstrate the effectiveness of Jensen gap minimization compared to other complexity measures. Comparisons with 15 machine learning algorithms further indicate that genetic programming with the proposed overfitting control strategy achieves superior performance.
LLM-Meta-SR: Learning to Evolve Selection Operators for Symbolic Regression
May 24, 2025Large language models (LLMs) have revolutionized algorithm development, yet their application in symbolic regression, where algorithms automatically discover symbolic expressions from data, remains constrained and is typically designed manually by human experts. In this paper, we propose a learning-to-evolve framework that enables LLMs to automatically design selection operators for evolutionary symbolic regression algorithms. We first identify two key limitations in existing LLM-based algorithm evolution techniques: code bloat and a lack of semantic guidance. Bloat results in unnecessarily complex components, and the absence of semantic awareness can lead to ineffective exchange of useful code components, both of which can reduce the interpretability of the designed algorithm or hinder evolutionary learning progress. To address these issues, we enhance the LLM-based evolution framework for meta symbolic regression with two key innovations: bloat control and a complementary, semantics-aware selection operator. Additionally, we embed domain knowledge into the prompt, enabling the LLM to generate more effective and contextually relevant selection operators. Our experimental results on symbolic regression benchmarks show that LLMs can devise selection operators that outperform nine expert-designed baselines, achieving state-of-the-art performance. This demonstrates that LLMs can exceed expert-level algorithm design for symbolic regression.
Call for Action: towards the next generation of symbolic regression benchmark
May 06, 2025


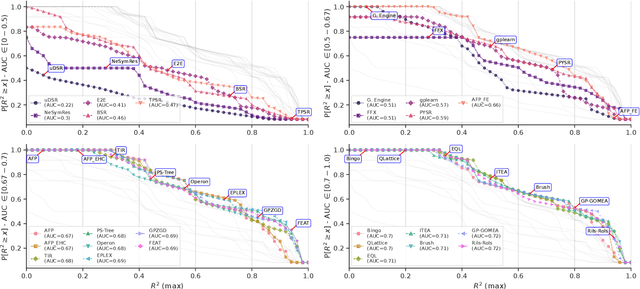
Symbolic Regression (SR) is a powerful technique for discovering interpretable mathematical expressions. However, benchmarking SR methods remains challenging due to the diversity of algorithms, datasets, and evaluation criteria. In this work, we present an updated version of SRBench. Our benchmark expands the previous one by nearly doubling the number of evaluated methods, refining evaluation metrics, and using improved visualizations of the results to understand the performances. Additionally, we analyze trade-offs between model complexity, accuracy, and energy consumption. Our results show that no single algorithm dominates across all datasets. We propose a call for action from SR community in maintaining and evolving SRBench as a living benchmark that reflects the state-of-the-art in symbolic regression, by standardizing hyperparameter tuning, execution constraints, and computational resource allocation. We also propose deprecation criteria to maintain the benchmark's relevance and discuss best practices for improving SR algorithms, such as adaptive hyperparameter tuning and energy-efficient implementations.
Sharpness-Aware Minimization for Evolutionary Feature Construction in Regression
May 11, 2024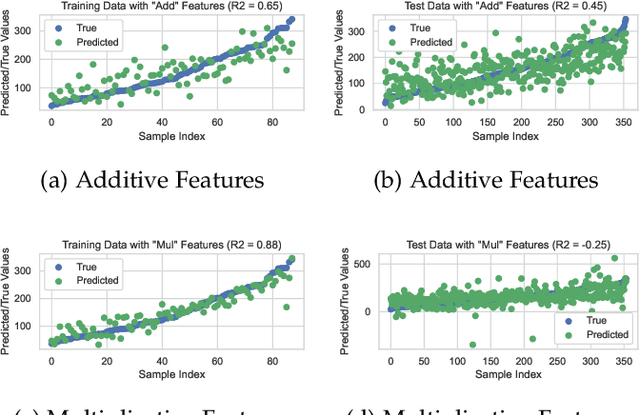

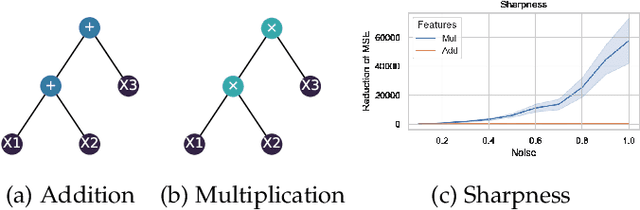

In recent years, genetic programming (GP)-based evolutionary feature construction has achieved significant success. However, a primary challenge with evolutionary feature construction is its tendency to overfit the training data, resulting in poor generalization on unseen data. In this research, we draw inspiration from PAC-Bayesian theory and propose using sharpness-aware minimization in function space to discover symbolic features that exhibit robust performance within a smooth loss landscape in the semantic space. By optimizing sharpness in conjunction with cross-validation loss, as well as designing a sharpness reduction layer, the proposed method effectively mitigates the overfitting problem of GP, especially when dealing with a limited number of instances or in the presence of label noise. Experimental results on 58 real-world regression datasets show that our approach outperforms standard GP as well as six state-of-the-art complexity measurement methods for GP in controlling overfitting. Furthermore, the ensemble version of GP with sharpness-aware minimization demonstrates superior performance compared to nine fine-tuned machine learning and symbolic regression algorithms, including XGBoost and LightGBM.
BertNet: Harvesting Knowledge Graphs from Pretrained Language Models
Jun 28, 2022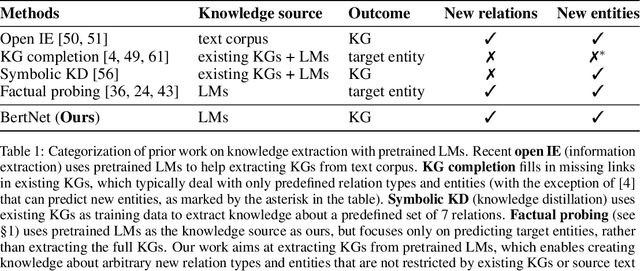
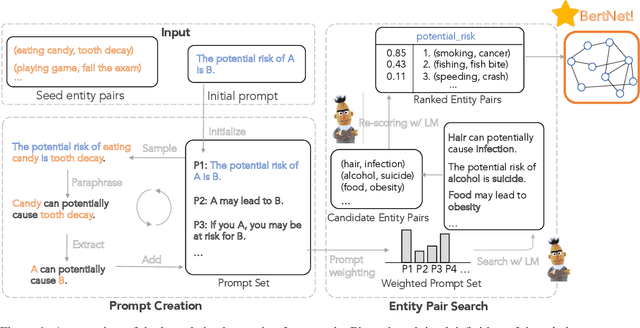
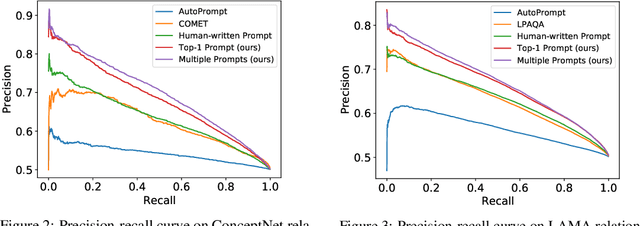

Symbolic knowledge graphs (KGs) have been constructed either by expensive human crowdsourcing or with domain-specific complex information extraction pipelines. The emerging large pretrained language models (LMs), such as Bert, have shown to implicitly encode massive knowledge which can be queried with properly designed prompts. However, compared to the explicit KGs, the implict knowledge in the black-box LMs is often difficult to access or edit and lacks explainability. In this work, we aim at harvesting symbolic KGs from the LMs, a new framework for automatic KG construction empowered by the neural LMs' flexibility and scalability. Compared to prior works that often rely on large human annotated data or existing massive KGs, our approach requires only the minimal definition of relations as inputs, and hence is suitable for extracting knowledge of rich new relations not available before.The approach automatically generates diverse prompts, and performs efficient knowledge search within a given LM for consistent and extensive outputs. The harvested knowledge with our approach is substantially more accurate than with previous methods, as shown in both automatic and human evaluation. As a result, we derive from diverse LMs a family of new KGs (e.g., BertNet and RoBERTaNet) that contain a richer set of commonsense relations, including complex ones (e.g., "A is capable of but not good at B"), than the human-annotated KGs (e.g., ConceptNet). Besides, the resulting KGs also serve as a vehicle to interpret the respective source LMs, leading to new insights into the varying knowledge capability of different LMs.